(转)几种范数的解释 l0-Norm, l1-Norm, l2-Norm, … , l-infinity Norm
几种范数的解释 l0-Norm, l1-Norm, l2-Norm, … , l-infinity Norm
from Rorasa's blog
l0-Norm, l1-Norm, l2-Norm, … , l-infinity Norm
I’m working on things related to norm a lot lately and it is time to talk about it. In this post we are going to discuss about a whole family of norm.
What is a norm?
Mathematically a norm is a total size or length of all vectors in a vector space or matrices. For simplicity, we can say that the higher the norm is, the bigger the (value in) matrix or vector is. Norm may come in many forms and many names, including these popular name: Euclidean distance, Mean-squared Error, etc.
Most of the time you will see the norm appears in a equation like this:


For example, a Euclidean norm of a vector 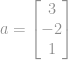
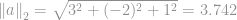

The above example shows how to compute a Euclidean norm, or formally called an 
Formally the 


That’s it! A p-th-root of a summation of all elements to the p-th power is what we call a norm.
The interesting point is even though every
l0-norm
The first norm we are going to discuss is a 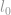

Strictly speaking, 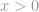

that is a total number of non-zero elements in a vector.
Because it is a number of non-zero element, there is so many applications that use
l0-optimisation
Many application, including Compressive Sensing, try to minimise the
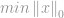

However, doing so is not an easy task. Because the lack of
In many case, 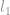
l1-norm
Following the definition of norm,
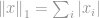
This norm is quite common among the norm family. It has many name and many forms among various fields, namely Manhattan norm is it’s nickname. If the

it is called Sum of Absolute Difference (SAD) among computer vision scientists.
In more general case of signal difference measurement, it may be scaled to a unit vector by:
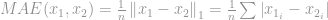
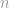
which is known as Mean-Absolute Error (MAE).
l2-norm
The most popular of all norm is the
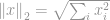
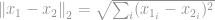
or in its squared form, known as a Sum of Squared Difference (SSD) among Computer Vision scientists:

It’s most well known application in the signal processing field is the Mean-Squared Error (MSE) measurement, which is used to compute a similarity, a quality, or a correlation between two signals. MSE is
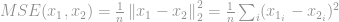
As previously discussed in
l2-optimisation
As in

Assume that the constraint matrix 
By using a trick of Lagrange multipliers, we can then define a Lagrangian

where 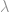

plug this solution into the constraint to get

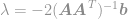
and finally

By using this equation, we can now instantly compute an optimal solution of the
However, even though the solution of Least Square method is easy to compute, it’s not necessary be the best solution. Because of the smooth nature of

In contrary, the
l1-optimisation
As usual, the
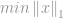
Because the nature of

However, even though the problem of
Since there is no easy way to find the solution for this problem mathematically, the usefulness of
There are many toolboxes for
Now that we have discussed many members of norm family, starting from 
l-infinity norm
As always, the definition for
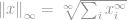
Now this definition looks tricky again, but actually it is quite strait forward. Consider the vector 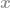
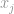

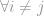
then
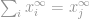
then
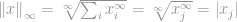
Now we can simply say that the
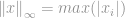
that is the maximum entries’ magnitude of that vector. That surely demystified the meaning of
Now we have discussed the whole family of norm from
Reference and further reading:
Michael Elad – “Sparse and Redundant Representations : From Theory to Applications in Signal and Image Processing” , Springer, 2010.
Linear Programming – MathWorld
Compressive Sensing – Rice University
Edit (15/02/15) : Corrected inaccuracies of the content.
(转)几种范数的解释 l0-Norm, l1-Norm, l2-Norm, … , l-infinity Norm的更多相关文章
- 机器学习中的范数规则化 L0、L1与L2范数 核范数与规则项参数选择
http://blog.csdn.net/zouxy09/article/details/24971995 机器学习中的范数规则化之(一)L0.L1与L2范数 zouxy09@qq.com http: ...
- paper 126:[转载] 机器学习中的范数规则化之(一)L0、L1与L2范数
机器学习中的范数规则化之(一)L0.L1与L2范数 zouxy09@qq.com http://blog.csdn.net/zouxy09 今天我们聊聊机器学习中出现的非常频繁的问题:过拟合与规则化. ...
- 机器学习中的范数规则化之(一)L0、L1与L2范数(转)
http://blog.csdn.net/zouxy09/article/details/24971995 机器学习中的范数规则化之(一)L0.L1与L2范数 zouxy09@qq.com http: ...
- L0、L1与L2范数、核范数(转)
L0.L1与L2范数.核范数 今天我们聊聊机器学习中出现的非常频繁的问题:过拟合与规则化.我们先简单的来理解下常用的L0.L1.L2和核范数规则化.最后聊下规则化项参数的选择问题.这里因为篇幅比较庞大 ...
- 机器学习中的范数规则化之(一)L0、L1与L2范数 非常好,必看
机器学习中的范数规则化之(一)L0.L1与L2范数 zouxy09@qq.com http://blog.csdn.net/zouxy09 今天我们聊聊机器学习中出现的非常频繁的问题:过拟合与规则化. ...
- 『科学计算』L0、L1与L2范数_理解
『教程』L0.L1与L2范数 一.L0范数.L1范数.参数稀疏 L0范数是指向量中非0的元素的个数.如果我们用L0范数来规则化一个参数矩阵W的话,就是希望W的大部分元素都是0,换句话说,让参数W是稀 ...
- 机器学习中的范数规则化之L0、L1与L2范数
今天看到一篇讲机器学习范数规则化的文章,讲得特别好,记录学习一下.原博客地址(http://blog.csdn.net/zouxy09). 今天我们聊聊机器学习中出现的非常频繁的问题:过拟合与规则化. ...
- Machine Learning系列--L0、L1、L2范数
今天我们聊聊机器学习中出现的非常频繁的问题:过拟合与规则化.我们先简单的来理解下常用的L0.L1.L2和核范数规则化.最后聊下规则化项参数的选择问题.这里因为篇幅比较庞大,为了不吓到大家,我将这个五个 ...
- 机器学习中的范数规则化之 L0、L1与L2范数、核范数与规则项参数选择
装载自:https://blog.csdn.net/u012467880/article/details/52852242 今天我们聊聊机器学习中出现的非常频繁的问题:过拟合与规则化.我们先简单的来理 ...
随机推荐
- SVM学习(续)
SVM的文章可以看:http://www.cnblogs.com/charlesblc/p/6193867.html 有写的最好的文章来自:http://www.blogjava.net/zhenan ...
- bootstrap selectpicker
mark 一下使用 bootstrap selectpicker 遇到的一个小issue,作为下次查错使用 $('.selectpicker').selectpicker('val', 'Mustar ...
- tab选项卡(选择上面的菜单,下面出现对应的不同的内容)
使用jQuery完成 <!DOCTYPE html> <html lang="en"> <head> <meta charset=&quo ...
- c/c++ 软件集成 安装和可卸载软件
作为一个工程师应具备的一些能力: 1. 首先具备这款软件: >inno Setup 免费版还开源,良心货,妥妥的. 2. 这款软件上手也比较款,可自行参考使用文档 3.编译成功,生 ...
- launch文件
launch在ROS应用中,每个节点通常有许多参数需要设置,为了方便高效操作多个节点,可以编写launch文件,然后用roslaunch命令运行roslaunch: roslaunch [option ...
- JavaScript 数组的创建
数组定义:数组(array)是一种数据类型,它包含或者存储了编码的值,每个编码的值称作该数组的一个元素(element), 每个元素的编码被称作为下标(index). JavaScript一维数组创建 ...
- HTTP 304
304 的标准解释是:Not Modified 客户端有缓冲的文档并发出了一个条件性的请求(一般是提供If-Modified-Since头表示客户只想比指定日期更新的文档).服务器告诉客户,原来缓冲的 ...
- Android M新特性之Behavior Changes
1.Runtime Permissions On your apps that target the M Preview release or higher, make sure to check f ...
- 将事件绑定在html标签中和js动态绑定的区别
一:绑定在标签中: 能够一眼看出那些元素绑定了什么事件. 只能将元素和事件逐一实现绑定. 二js动态绑定: 可以一次动态的给多个元素绑定事件,批量绑定事件. html标签绑定的缺点: ①:可能有时间差 ...
- codeforces 446B(优先队列)
题目链接:http://codeforces.com/problemset/problem/446/B #include<bits/stdc++.h> using namespace st ...