Python 进阶 - 正则表达式
1. 正则表达式基础
1.1. 简单介绍
正则表达式并不是Python的一部分。正则表达式是用于处理字符串的强大工具,拥有自己独特的语法以及一个独立的处理引擎,效率上可能不如str自带的方法,但功能十分强大。得益于这一点,在提供了正则表达式的语言里,正则表达式的语法都是一样的,区别只在于不同的编程语言实现支持的语法数量不同;但不用担心,不被支持的语法通常是不常用的部分。如果已经在其他语言里使用过正则表达式,只需要简单看一看就可以上手了。
下图展示了使用正则表达式进行匹配的流程: 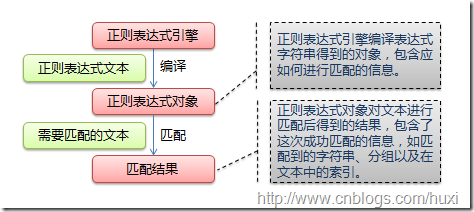
正则表达式的大致匹配过程是:依次拿出表达式和文本中的字符比较,如果每一个字符都能匹配,则匹配成功;一旦有匹配不成功的字符则匹配失败。如果表达式中有量词或边界,这个过程会稍微有一些不同,但也是很好理解的,看下图中的示例以及自己多使用几次就能明白。
下图列出了Python支持的正则表达式元字符和语法: 
1.2. 数量词的贪婪模式与非贪婪模式
正则表达式通常用于在文本中查找匹配的字符串。Python里数量词默认是贪婪的(在少数语言里也可能是默认非贪婪),总是尝试匹配尽可能多的字符;非贪婪的则相反,总是尝试匹配尽可能少的字符。例如:正则表达式"ab*"如果用于查找"abbbc",将找到"abbb"。而如果使用非贪婪的数量词"ab*?",将找到"a"。
1.3. 反斜杠的困扰
与大多数编程语言相同,正则表达式里使用"\"作为转义字符,这就可能造成反斜杠困扰。假如你需要匹配文本中的字符"\",那么使用编程语言表示的正则表达式里将需要4个反斜杠"\\\\":前两个和后两个分别用于在编程语言里转义成反斜杠,转换成两个反斜杠后再在正则表达式里转义成一个反斜杠。Python里的原生字符串很好地解决了这个问题,这个例子中的正则表达式可以使用r"\\"表示。同样,匹配一个数字的"\\d"可以写成r"\d"。有了原生字符串,你再也不用担心是不是漏写了反斜杠,写出来的表达式也更直观。
1.4. 匹配模式
正则表达式提供了一些可用的匹配模式,比如忽略大小写、多行匹配等,这部分内容将在Pattern类的工厂方法re.compile(pattern[, flags])中一起介绍。
2. re模块
2.1. 开始使用re
Python通过re模块提供对正则表达式的支持。使用re的一般步骤是先将正则表达式的字符串形式编译为Pattern实例,然后使用Pattern实例处理文本并获得匹配结果(一个Match实例),最后使用Match实例获得信息,进行其他的操作。
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
|
# encoding: UTF-8import re# 将正则表达式编译成Pattern对象pattern = re.compile(r'hello')# 使用Pattern匹配文本,获得匹配结果,无法匹配时将返回Nonematch = pattern.match('hello world!')if match: # 使用Match获得分组信息 print match.group()### 输出 #### hello |
re.compile(strPattern[, flag]):
这个方法是Pattern类的工厂方法,用于将字符串形式的正则表达式编译为Pattern对象。 第二个参数flag是匹配模式,取值可以使用按位或运算符'|'表示同时生效,比如re.I | re.M。另外,你也可以在regex字符串中指定模式,比如re.compile('pattern', re.I | re.M)与re.compile('(?im)pattern')是等价的。 可选值有:
- re.I(re.IGNORECASE): 忽略大小写(括号内是完整写法,下同)
- M(MULTILINE): 多行模式,改变'^'和'$'的行为(参见上图)
- S(DOTALL): 点任意匹配模式,改变'.'的行为
- L(LOCALE): 使预定字符类 \w \W \b \B \s \S 取决于当前区域设定
- U(UNICODE): 使预定字符类 \w \W \b \B \s \S \d \D 取决于unicode定义的字符属性
- X(VERBOSE): 详细模式。这个模式下正则表达式可以是多行,忽略空白字符,并可以加入注释。以下两个正则表达式是等价的:
|
1
2
3
4
|
a = re.compile(r"""\d + # the integral part \. # the decimal point \d * # some fractional digits""", re.X)b = re.compile(r"\d+\.\d*") |
re提供了众多模块方法用于完成正则表达式的功能。这些方法可以使用Pattern实例的相应方法替代,唯一的好处是少写一行re.compile()代码,但同时也无法复用编译后的Pattern对象。这些方法将在Pattern类的实例方法部分一起介绍。如上面这个例子可以简写为:
|
1
2
|
m = re.match(r'hello', 'hello world!')print m.group() |
re模块还提供了一个方法escape(string),用于将string中的正则表达式元字符如*/+/?等之前加上转义符再返回,在需要大量匹配元字符时有那么一点用。
2.2. Match
Match对象是一次匹配的结果,包含了很多关于此次匹配的信息,可以使用Match提供的可读属性或方法来获取这些信息。
属性:
- string: 匹配时使用的文本。
- re: 匹配时使用的Pattern对象。
- pos: 文本中正则表达式开始搜索的索引。值与Pattern.match()和Pattern.seach()方法的同名参数相同。
- endpos: 文本中正则表达式结束搜索的索引。值与Pattern.match()和Pattern.seach()方法的同名参数相同。
- lastindex: 最后一个被捕获的分组在文本中的索引。如果没有被捕获的分组,将为None。
- lastgroup: 最后一个被捕获的分组的别名。如果这个分组没有别名或者没有被捕获的分组,将为None。
方法:
- group([group1, …]): 获得一个或多个分组截获的字符串;指定多个参数时将以元组形式返回。group1可以使用编号也可以使用别名;编号0代表整个匹配的子串;不填写参数时,返回group(0);没有截获字符串的组返回None;截获了多次的组返回最后一次截获的子串。
- groups([default]): 以元组形式返回全部分组截获的字符串。相当于调用group(1,2,…last)。default表示没有截获字符串的组以这个值替代,默认为None。
- groupdict([default]): 返回以有别名的组的别名为键、以该组截获的子串为值的字典,没有别名的组不包含在内。default含义同上。
- start([group]): 返回指定的组截获的子串在string中的起始索引(子串第一个字符的索引)。group默认值为0。
- end([group]): 返回指定的组截获的子串在string中的结束索引(子串最后一个字符的索引+1)。group默认值为0。
- span([group]): 返回(start(group), end(group))。
- expand(template): 将匹配到的分组代入template中然后返回。template中可以使用\id或\g<id>、\g<name>引用分组,但不能使用编号0。\id与\g<id>是等价的;但\10将被认为是第10个分组,如果你想表达\1之后是字符'0',只能使用\g<1>0。
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
|
import rem = re.match(r'(\w+) (\w+)(?P<sign>.*)', 'hello world!')print "m.string:", m.stringprint "m.re:", m.reprint "m.pos:", m.posprint "m.endpos:", m.endposprint "m.lastindex:", m.lastindexprint "m.lastgroup:", m.lastgroupprint "m.group(1,2):", m.group(1, 2)print "m.groups():", m.groups()print "m.groupdict():", m.groupdict()print "m.start(2):", m.start(2)print "m.end(2):", m.end(2)print "m.span(2):", m.span(2)print r"m.expand(r'\2 \1\3'):", m.expand(r'\2 \1\3')### output #### m.string: hello world!# m.re: <_sre.SRE_Pattern object at 0x016E1A38># m.pos: 0# m.endpos: 12# m.lastindex: 3# m.lastgroup: sign# m.group(1,2): ('hello', 'world')# m.groups(): ('hello', 'world', '!')# m.groupdict(): {'sign': '!'}# m.start(2): 6# m.end(2): 11# m.span(2): (6, 11)# m.expand(r'\2 \1\3'): world hello! |
2.3. Pattern
Pattern对象是一个编译好的正则表达式,通过Pattern提供的一系列方法可以对文本进行匹配查找。
Pattern不能直接实例化,必须使用re.compile()进行构造。
Pattern提供了几个可读属性用于获取表达式的相关信息:
- pattern: 编译时用的表达式字符串。
- flags: 编译时用的匹配模式。数字形式。
- groups: 表达式中分组的数量。
- groupindex: 以表达式中有别名的组的别名为键、以该组对应的编号为值的字典,没有别名的组不包含在内。
|
1
2
3
4
5
6
7
8
9
10
11
12
13
|
import rep = re.compile(r'(\w+) (\w+)(?P<sign>.*)', re.DOTALL)print "p.pattern:", p.patternprint "p.flags:", p.flagsprint "p.groups:", p.groupsprint "p.groupindex:", p.groupindex### output #### p.pattern: (\w+) (\w+)(?P<sign>.*)# p.flags: 16# p.groups: 3# p.groupindex: {'sign': 3} |
实例方法[ | re模块方法]:
- match(string[, pos[, endpos]]) | re.match(pattern, string[, flags]): 这个方法将从string的pos下标处起尝试匹配pattern;如果pattern结束时仍可匹配,则返回一个Match对象;如果匹配过程中pattern无法匹配,或者匹配未结束就已到达endpos,则返回None。 pos和endpos的默认值分别为0和len(string);re.match()无法指定这两个参数,参数flags用于编译pattern时指定匹配模式。 注意:这个方法并不是完全匹配。当pattern结束时若string还有剩余字符,仍然视为成功。想要完全匹配,可以在表达式末尾加上边界匹配符'$'。 示例参见2.1小节。
- search(string[, pos[, endpos]]) | re.search(pattern, string[, flags]): 这个方法用于查找字符串中可以匹配成功的子串。从string的pos下标处起尝试匹配pattern,如果pattern结束时仍可匹配,则返回一个Match对象;若无法匹配,则将pos加1后重新尝试匹配;直到pos=endpos时仍无法匹配则返回None。 pos和endpos的默认值分别为0和len(string));re.search()无法指定这两个参数,参数flags用于编译pattern时指定匹配模式。
12345678910111213141516
# encoding: UTF-8importre# 将正则表达式编译成Pattern对象pattern=re.compile(r'world')# 使用search()查找匹配的子串,不存在能匹配的子串时将返回None# 这个例子中使用match()无法成功匹配match=pattern.search('hello world!')ifmatch:# 使用Match获得分组信息printmatch.group()### 输出 #### world - split(string[, maxsplit]) | re.split(pattern, string[, maxsplit]): 按照能够匹配的子串将string分割后返回列表。maxsplit用于指定最大分割次数,不指定将全部分割。
1234567
importrep=re.compile(r'\d+')printp.split('one1two2three3four4')### output #### ['one', 'two', 'three', 'four', ''] - findall(string[, pos[, endpos]]) | re.findall(pattern, string[, flags]): 搜索string,以列表形式返回全部能匹配的子串。
1234567
importrep=re.compile(r'\d+')printp.findall('one1two2three3four4')### output #### ['1', '2', '3', '4'] - finditer(string[, pos[, endpos]]) | re.finditer(pattern, string[, flags]): 搜索string,返回一个顺序访问每一个匹配结果(Match对象)的迭代器。
12345678
importrep=re.compile(r'\d+')forminp.finditer('one1two2three3four4'):printm.group(),### output #### 1 2 3 4 - sub(repl, string[, count]) | re.sub(pattern, repl, string[, count]): 使用repl替换string中每一个匹配的子串后返回替换后的字符串。 当repl是一个字符串时,可以使用\id或\g<id>、\g<name>引用分组,但不能使用编号0。 当repl是一个方法时,这个方法应当只接受一个参数(Match对象),并返回一个字符串用于替换(返回的字符串中不能再引用分组)。 count用于指定最多替换次数,不指定时全部替换。
123456789101112131415
importrep=re.compile(r'(\w+) (\w+)')s='i say, hello world!'printp.sub(r'\2 \1', s)deffunc(m):returnm.group(1).title()+' '+m.group(2).title()printp.sub(func, s)### output #### say i, world hello!# I Say, Hello World! - subn(repl, string[, count]) |re.sub(pattern, repl, string[, count]): 返回 (sub(repl, string[, count]), 替换次数)。
123456789101112131415
importrep=re.compile(r'(\w+) (\w+)')s='i say, hello world!'printp.subn(r'\2 \1', s)deffunc(m):returnm.group(1).title()+' '+m.group(2).title()printp.subn(func, s)### output #### ('say i, world hello!', 2)# ('I Say, Hello World!', 2)
以上就是Python对于正则表达式的支持。熟练掌握正则表达式是每一个程序员必须具备的技能,这年头没有不与字符串打交道的程序了。笔者也处于初级阶段,与君共勉,^_^
另外,图中的特殊构造部分没有举出例子,用到这些的正则表达式是具有一定难度的。有兴趣可以思考一下,如何匹配不是以abc开头的单词,^_^
全文结束
本文为转载
Python 进阶 - 正则表达式的更多相关文章
- Python进阶-Ⅹ 正则表达式(RexEx)、re模块
1.正则表达式(RexEx)常用知识 2.python中re模块的初步使用 1).findall方法 ret = re.findall('a', 'eva egon yuan') # 返回所有满足匹配 ...
- python进阶11 正则表达式
python进阶11 正则表达式 一.概念 #正则表达式主要解决什么问题? #1.判断一个字符串是否匹配给定的格式,判断用户提交的又想的格式是否正确 #2.从一个字符串中按指定格式提取信息,抓取页面中 ...
- python进阶(20) 正则表达式的超详细使用
正则表达式 正则表达式(Regular Expression,在代码中常简写为regex. regexp.RE 或re)是预先定义好的一个"规则字符率",通过这个"规 ...
- 【Python】正则表达式纯代码极简教程
<Python3正则表达式>文字版详细教程链接:https://www.cnblogs.com/leejack/p/9189796.html ''' 内容:Python3正则表达式 日期: ...
- 【Python】正则表达式简单教程
说明:本文主要是根据廖雪峰网站的正则表达式教程学习,并根据需要做了少许修改,此处记录下来以备后续查看. <Python正则表达式纯代码极简教程>链接:https://www.cnblogs ...
- Python进阶(十二)----re模块
Python进阶(十二)----re模块 一丶re模块 re模块是python将正则表达式封装之后的一个模块.正则表达式模式被编译成一系列的字节码,然后由用C编写的匹配引擎执行. #正则表达式: ...
- 尚学python课程---15、python进阶语法
尚学python课程---15.python进阶语法 一.总结 一句话总结: python使用东西要引入库,比如 json 1.python如何创建类? class ClassName: :以冒号结尾 ...
- [python] 常用正则表达式爬取网页信息及分析HTML标签总结【转】
[python] 常用正则表达式爬取网页信息及分析HTML标签总结 转http://blog.csdn.net/Eastmount/article/details/51082253 标签: pytho ...
- python study - 正则表达式
第 7 章 正则表达式 7.1. 概览 7.2. 个案研究:街道地址 7.3. 个案研究:罗马字母 7.3.1. 校验千位数 7.3.2. 校验百位数 7.4. 使用 {n,m} 语法 7.4.1. ...
随机推荐
- 用PHP链接mysql数据库
PHP提供了两套数据库可用于访问mysql数据库 1)MySQL扩展函数数据库 2)MySQLI扩展数据库(improved) 使用MySQLI函数访问MySQL数据库步骤 1)链接数据库管理系统 m ...
- host_network_interfaces_slow_mode_thresholds
CDH报集群异常: host_network_interfaces_slow_mode_thresholds 警告置为从不-- 主要是我没有查到发生这种情况的原因是什么--
- loopback 02
数据库连接操作,以mongodb为例 安装loopback-connector-mongodb 修改datasources.json //例子 { "db": { "na ...
- 为什么使用BeagleBoneBeagleBone的优点
为什么使用BeagleBone BeagleBone的优点 当前,一个典型的基于微控制器板的售价在120元左右,而BeagleBone Black的售价在330元左右.除了更强大的处理器之外,你额外的 ...
- 伪Acmer的推理(dfs/bfs)
时间限制:1000MS 内存限制:65535K 提交次数:12 通过次数:9 收入:32 题型: 编程题 语言: C++;C Description 现在正是期末,在复习离散数学的Acmer遇到 ...
- 最火的.NET开源项目
综合类 微软企业库 微软官方出品,是为了协助开发商解决企业级应用开发过程中所面临的一系列共性的问题, 如安全(Security).日志(Logging).数据访问(Data Access).配置管理( ...
- 矩阵快速幂 UVA 10870 Recurrences
题目传送门 题意:f(n) = a1f(n − 1) + a2f(n − 2) + a3f(n − 3) + . . . + adf(n − d), for n > d,求f (n) % m.训 ...
- iOS 初学UITableView、UITableViewCell、Xib
注意事项: 1.一个.xib里面最多设置一个cell 2.要仔细调整自动布局,其实它不太好用 3.记得设置<UITableViewDataSource>委托 4.记得在ViewContro ...
- Jquery和JS获取ul中li标签
js 获取元素下面所有的li var content=document.getElementById("content"); var items=content.getElemen ...
- 图解Storm
问题导读:1.你认为什么图形可以显示hadoop与storm的区别?(电梯)2.本文是如何形象讲解hadoop与storm的?(离线批量处理.实时流式处理)3.hadoop map/reduce对应s ...