thread_Disruptor
转自 知乎 https://zhuanlan.zhihu.com/p/21355046
order从client端传入,decode后进行matching,一旦存在可成交的价格,就要publish到time series,并且把trade存到local的database里。如何handle这么大数量的数据?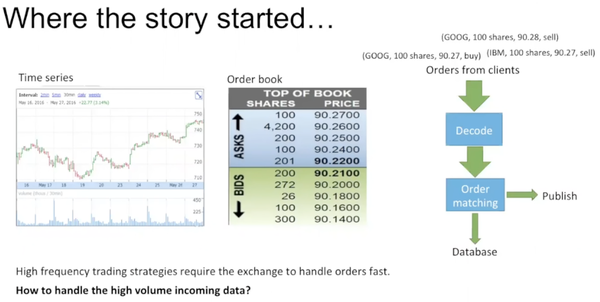
这并不是一个新生的问题。一个经常想到的模型是producer consumer model。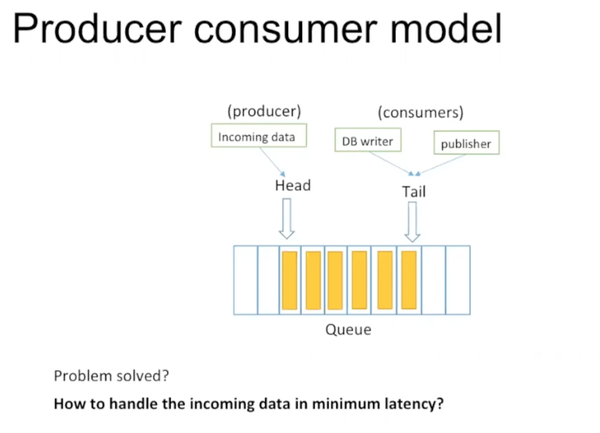
当系统的处理速度比不上导入数据的速度时,可以增加一个queue(buffer)暂存数据,等待consumer处理。数据在queue中被执行的顺序和交易策略有关。
除了handle大量数据,电子商务对数据延迟的要求也很高。首先定义一下什么是数据的延迟。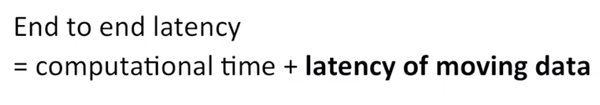
数据的延迟包括数据的处理时间和数据的移动时间。其中第二部分在编写代码时常被忽略,但在实际生产过程中常占有很大比重。
Blocking queue有两种,array-based和linked list based。array-based相对更优,这里我们先对它进行一些分析。
Producer和consumer处理速度往往是不同的,这样容易形成两种情况:一种是producer速度快,queue易全满,另一种是consumer速度快,queue易全空。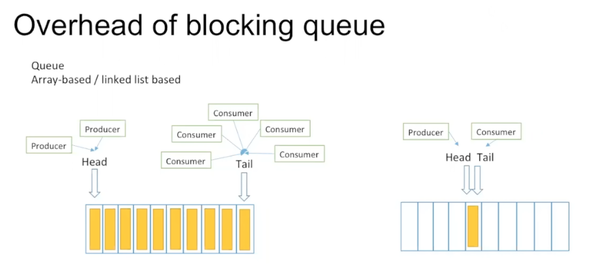
Blocking queue的缺点主要有两个:一个是producer只能从head放数据,producer之间会竞争head指针,存在写竞争。consumer之间会竞争tail指针,它们之间也存在写竞争。并且很多情况下,queue是处于全空状态,head/tail指针指向同一个entry,producer和consumer之间也存在写竞争。因此需要lock来实现synchronization。另一个缺点是heal/tail指针的false sharing。
在进行下面讲解前先下两个结论,理由后续会涉及。
现在的计算机构架往往是有CPU,memory,它们之间有多层的cache。这种构架产生的原因在于CPU速度远高于memory速度。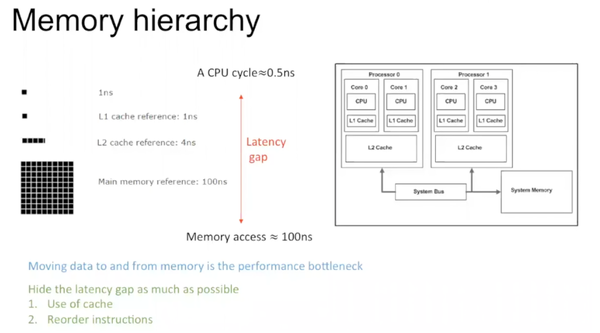
为了解决速度间不同步,可以使用cache。Cache是对历史数据的保存。如果数据之前没有读取,不存在于本层cache,则需要从上层cache里获取,存到本层cache里;若之前有读取,本层cache存有数据历史信息。有了cache,数据的移动路径变短。同时,写操作相对费时,CPU会在较优的时间进行写操作。
具体cache如何工作,见下图: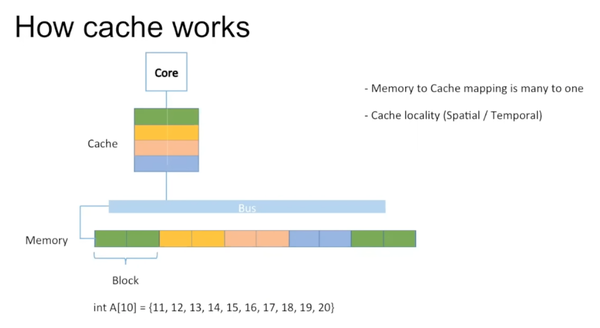
Memory的最小单位叫block,cache的最小单位叫cache line。Memory到cache存在多对一的mapping。图中用相同颜色表示它们之间的mapping。举例说明,如果有一个integer array,里面存有10个数据。它们一一映射到cache里。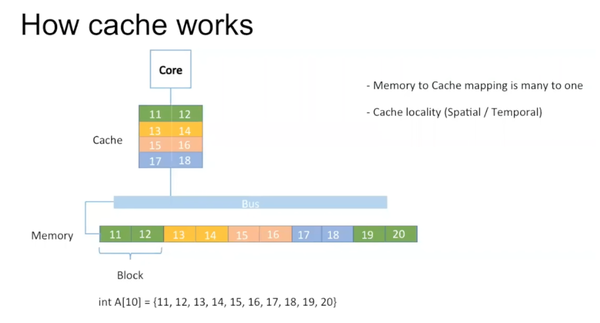
但往往cache的尺寸小于memory,19,20无法写入。对于多对一的这种mapping,存在对原有数据的eviction,19,20写在原来11,12处。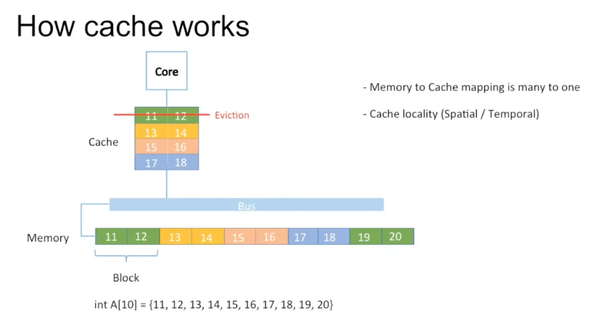
Memory的block往往大于一个integer。在读取A[0]时,实际上也把A[1]读取进去。所以在实际读取A[1]时,它已经存在于cache里。这是一种spatial cache locality。
如果A[9]变成35,只需要对cache里的数据进行更改。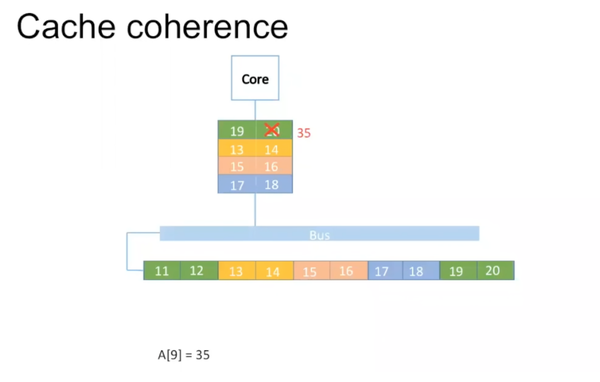
如果使用多个核,这种方法会出现问题。比如第二个核里的数据还是原来的20。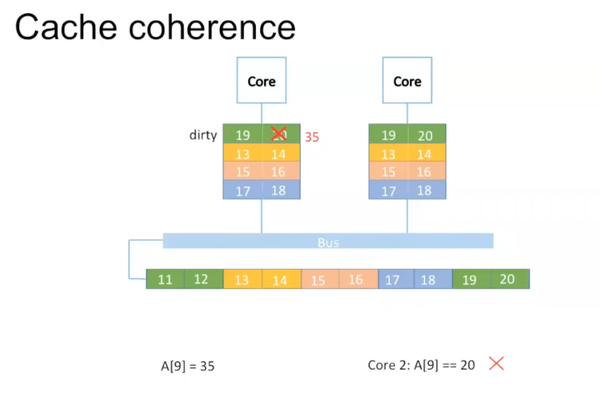
多核中对数据修改时,如果数据存在于多个核的cache里,要将其他核里数据设为invalid。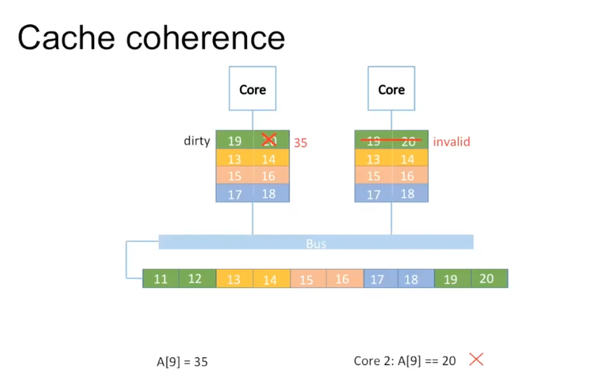
下面介绍false sharing。假设有两个integer a = 13和b = 14。如果第一个核在访问a,第二个核在访问b。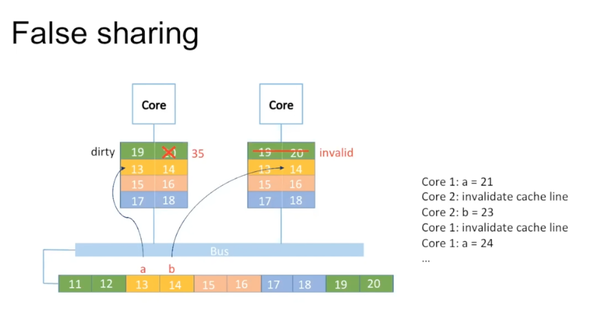
Core 1在访问a时让core 2中对应数据invalid,core 2修改时发现invalid,重新读取数据。但是core 2在读写时又把core 1对应数据invalid。Blocking queue里因为head/tail指针常是同一个,而producer和consumer在不同的core上运行,常会发生上述的false sharing,加大了数据移动的时间。
为什么使用lock会造成很多数据的移动?
以下图为例: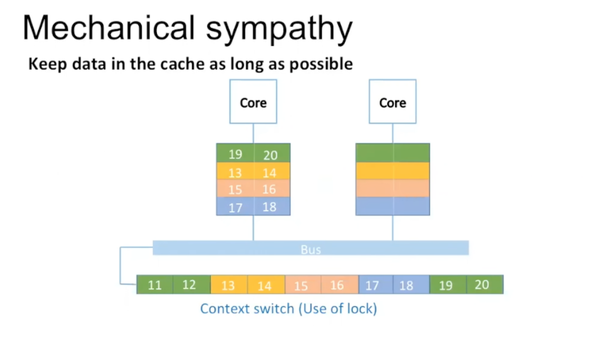
Core 1里有thread 1在运行,当遇到lock后,thread 1 sleep,core 1里运行thread 2。对于thread 2,core 1里cache的数据都是无用的。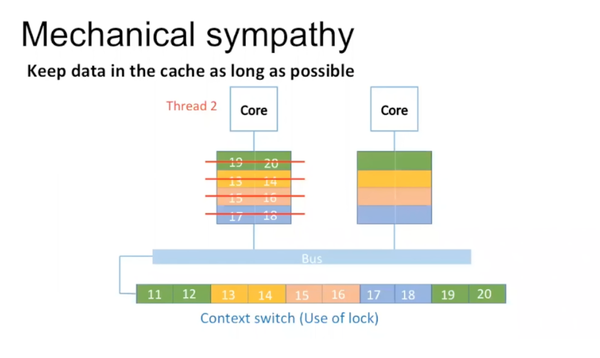
Thread 2重新加载数据运行。当thread 1醒来时,只能在core 2上运行,重新加载数据。所以当有lock的时候,出现了很多的cache miss,增加了数据移动的时间。
总结一下,blocking queue很慢的原因在于:写竞争造成的thread arbitrage以及false sharing导致的很多memory access。
Design of Disruptor
在设计Disruptor时要避免写竞争,让数据更久的留在cache里。
设计原则有:只有一个consumer,避免使用lock等等。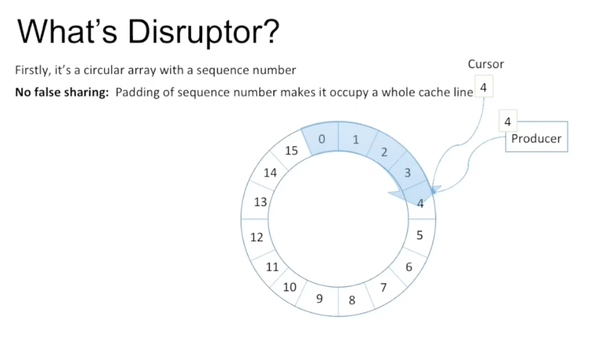
Disruptor的核心是一个circular array,有个cursor,里面有sequence number,数据类型是long。如果不考虑consumer,只有一个producer在写,就是不停的往entry里写东西,然后增加cursor上的sequence number。为了避免cursor里的sequence number和其他variable造作false sharing,disruptor定义了7个long型,并没有给它们赋值,然后再定义cursor。这样cursor就不会和其他variable同时出现在一个cache line里。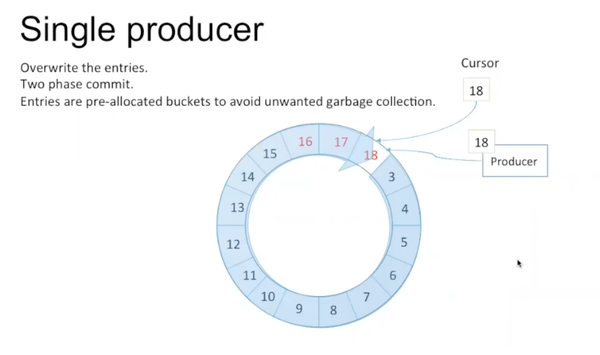
如果producer在写的过程中,超出了原来array的长度,就不停地overwrite原来的entry,增加cursor里的sequence number。bucket里的entry都是pre-allocated,避免每次都new一个object。因为disruptor是用java写的,这样可以避免garbage collection。producer写的过程是two phase commit。
如果加入了consumer,如下图: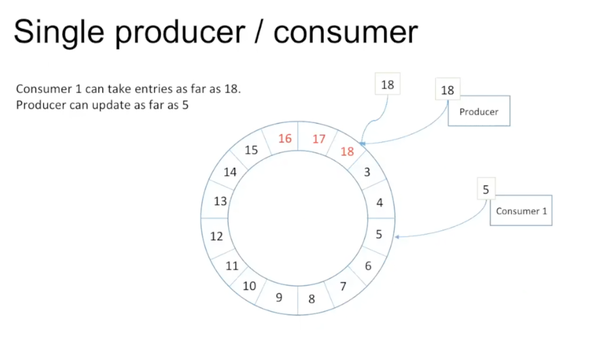
如果consumer当前访问的sequence number为5,producer当前访问到18。那么consumer可以一路访问到18,producer往前写不能超过5。
如果有多个consumer: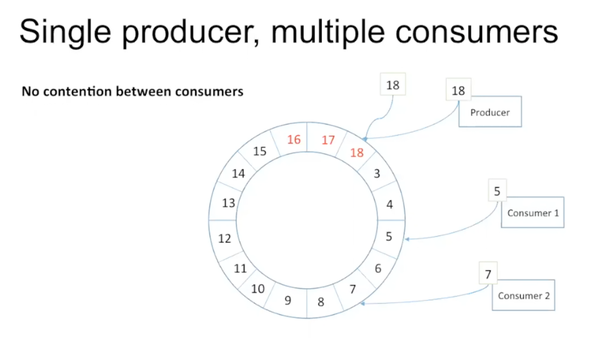
在disruptor里不同consumer之间没有contention。如上图中consumer 1可以从5读到18,consumer 2可以不用管consumer 1的存在,也一路读到18,consumer之间可以忽略对方的存在。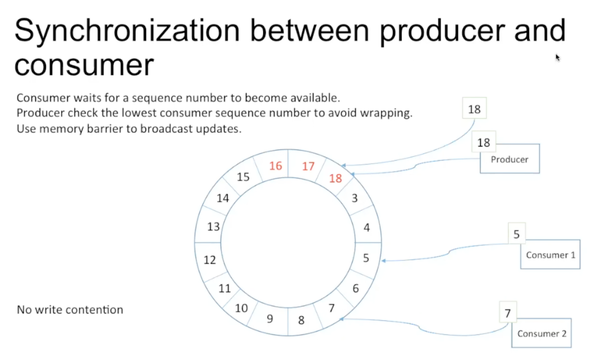
Consumer每次在访问时需要先检查sequence number是否available,如果不available,会有多种策略。latency最高的一种是盲等。producer在写的时候,需要检查最低的sequence number在哪儿。这里不需要lock的原因是sequence number是递增的。producer不需要赶在最低sequence number前面,因而没有write contention。此外,disruptor使用memory barrier通知数据的更新。
Memory barrier
CPU认为逻辑上没有冲突的instruction可以reorder。写操作需要花很多时间,可以在schedule pipeline比较方便的时候把instruction插进去。比如core 1需要写a,b,c,d。因为这四个variable之间没有关系,它们的顺序也是可以打乱的。在disruptor中并不直接把它们写入cache中,而是写入core和cache直接的一个store buffer里,在store buffer里四个variable是reorder的。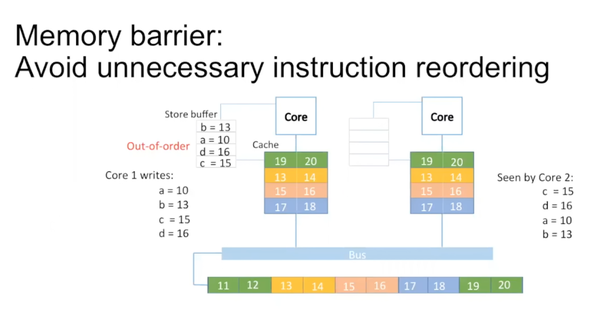
单线程下没有任何问题,但是多线程时,core 2角度来看,c先被写,然后是d,a,b。在disruptor里producer最后update cursor里的sequence number,告诉大家这个entry已经ready,所有的consumer可以读它。但是如果写entry的顺序和写sequence number的顺序不一致,会造成一种现象:sequence number的写已经完成,consumber可以去读对应数据,但是对应的entry的写还没有ready。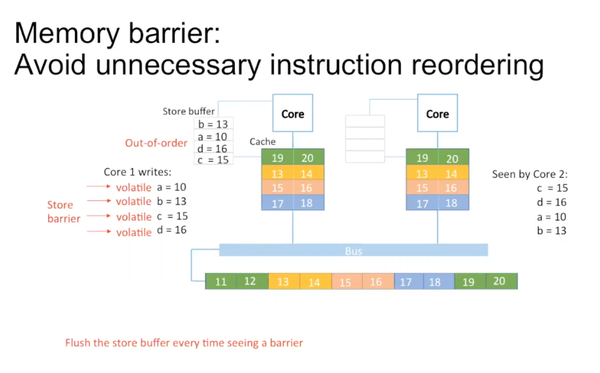
在java里用volatile字段修饰。CPU在执行时,遇到这个字段把store barrier里的数据清空。
在大部分情况下,consumer是跟在producer后面的。disruptor比较理想的情况就是一个producer,多个consumer。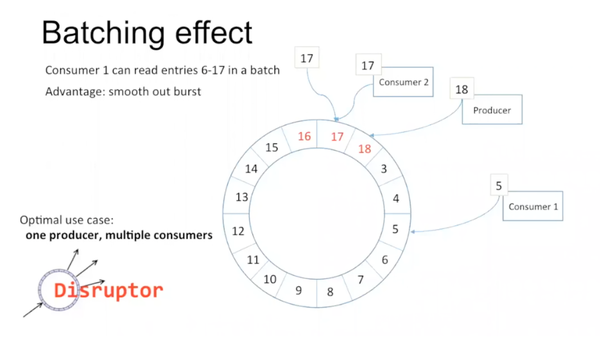
如果一个consumer处理的很慢,producer会被block,这是一个瓶颈。解决方法可以是把buffer变大。写较慢的一种操作是写往database中,这时可以写多个数据后再统一commit,这也是一种方法。还有很多其他方面的技巧,这里不再一一介绍。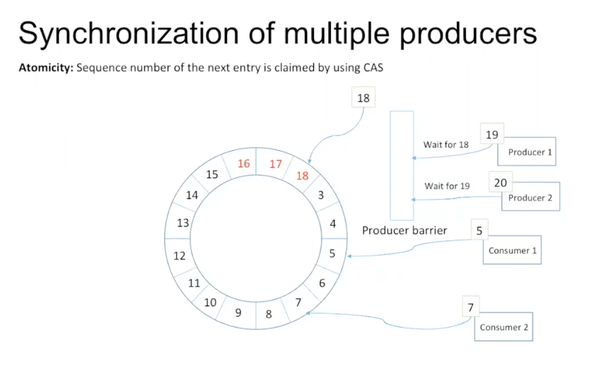
如果涉及到多个producer,也不需要lock。每个时刻只有一个thread可以increment这个数,保证只有一个producer能更新sequence number,实现atomicity。这里面使用了一个producer barrier类,里面有很多method做具体的实现。
前面所讲都是比较简单的情况,现实中依据dependence graph,disruptor可以构成很复杂的情形。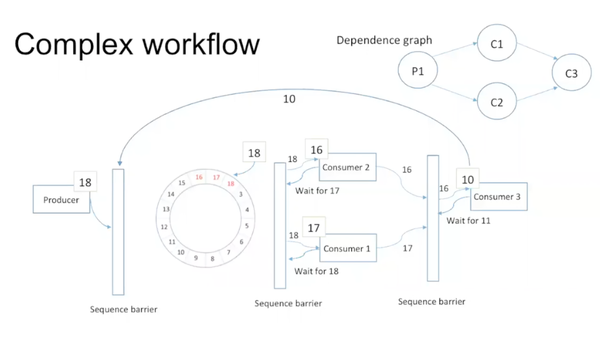
比如producer写入数据后被consumer 1和2处理,1,2处理完后consumer 3才能接着处理。这些可以通过设置不同的waiting strategy来实现。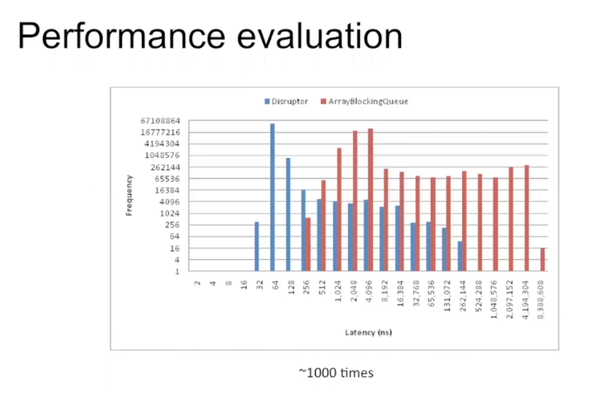
通过图表可以看出,disruptor的性能确实比blocking queue好很多。
最后回答一下常见的问题:
1. 如果buffer常常是满的怎么办?
一种是把buffer变大,另一种是从源头解决producer和consumer速度差异太大问题,比如试着把producer分流,或者用多个disruptor,使每个disruptor的load变小。
2. 什么时候使用disruptor?
如果对latency的需求很高,可以考虑使用。
Reference:
Source code
https://lmax-exchange.github.io/disruptor/
Technical paper
http://disruptor.googlecode.com/files/Disruptor-1/pdf
Blogs
http://bad-concurrency.blogspot.com/
http://mechanitis.blogspot.com/
Latency Numbers Every Programmer Should Know
http://www.eecs.berkeley.edu/~rcs/research/interactive_latency.html
thread_Disruptor的更多相关文章
随机推荐
- [Aaronyang] 写给自己的WPF4.5 笔记18[几何图形*Geometry图文并茂讲解]
为什么要掌握?因为WPF 3D知识很多与它Geometry对比,所以我要系统学一下. --学会用Geometry给Path的Data属性填充. 图形可以转换成路径,Path的值,当然你也可以直接使用R ...
- JAVA Builder模式构建MAP/LIST的示例
我们在构建一个MAP时,要不停的调用put,有时候看着觉得很麻烦,刚好,看了下builder模式,觉得这思路不错,于是乎,照着用builder模式写了一个构建MAP的示例,代码如下: import j ...
- mysql自动化安装
MySQL安装一般使用RPM或者源码安装的方式.RPM安装的优点是快速,方便.缺点是不能自定义安装目录.如果需要调整数据文件和日志文件的存放位置,还需要进行一些手动调整.源码安装的优点是可以自定义安装 ...
- Apache shiro之权限校验流程
从张开涛blog学习后整理:http://jinnianshilongnian.iteye.com/blog/2018398 图片原图比较大,建议将图片在新的选项卡打开后100%大小浏览 在权限校验中 ...
- session204 imessageApp sticker part I要点
session204 imessageApp sticker partI 工程文件:https://developer.apple.com/library/prerelease/content/sam ...
- 仿iReader切换皮肤进度条
仿iReader切换皮肤进度条 标签(空格分隔): 自定义View [TOC] 本以为使用paint.setXfermode(new PorterDuffXfermode(Mode.XOR));可以轻 ...
- Cocos2d-JS项目之一:环境(IDE 运行js-tests、IDE 和 studio 统一工程)
环境:cocos 引擎(包括 studio)2.2.1 for Mac.cocos2d-js-v3.5.Cocos Code IDE 1.2 for Mac,cocos 引擎指的是下面这个东西: 各种 ...
- java之数组
数组概述: 1.数组可以看成是多个相同数据类型数据的组合,对这些数据的统一管理. 2.数组变量属引用类型,数组也可以看成是对象,数组中的每个元素相当于该对象的成员变量. 3.数组中的元素可以是任何类型 ...
- Android ListView OnItemLongClick和OnItemClick事件内部细节分享以及几个比较特别的属性
本文转自 http://blog.sina.com.cn/s/blog_783ede030101bnm4.html 作者kiven 辞职3,4个月在家休息,本以为楼主要程序员逆袭,结果失败告终继续码农 ...
- How to debug Typescript in browser
How to debug typescript, In Chrome, we need to press F12, open settings, uncheck the Enable JavaScri ...