Hadoop_HDFS文件读写代码流程解析和副本存放机制
Hadoop学习笔记总结
01.RPC(远程过程调用)
1. RPC概念
远程过程指的不是同一个进程的调用。它是一种通过网络从远程计算机程序上请求服务,而不需要了解底层网络技术的协议。
不能直接拿到远程机器的服务实例:比如loginController拿不到另一台主机loginService的实例,需要远程调用。一种实现:如Soap(http+xml)
- RPC至少有两个过程。调用方(client),被调用方(server)。
- client主动发起请求,调用指定ip和port的server中的方法,把调用结果返回给client。
- 客户端调用服务端的方法,意味着调用服务端的对象中的方法。
- 如果服务端的对象允许客户端调用,那么这个对象必须实现接口。
- 如果客户端能够调用到服务端对象的方法,那么这些方法一定位于对象的接口中。
- RPC是hadoop构建的基础。
2. 在Hadoop上的应用例子
NameNode和DataNode之间通信,进程间的远程调用。
- 客户端获取NameNode的文件信息。(如客户端获取元数据信息,就是客户端通过RPC获得代理对象,调用NameNode的方法)
- 客户端写副本到DataNode,只写一个,其余的副本都是NameNode告诉DataNode去复制。
- DataNode和NameNode之间的心跳机制;DataNode定期汇报给NameNode自身的block信息(主要是当某个block损坏时,NameNode需要在元数据中更新副本信息)
hadoop和hbase中的大部分服务都是通过hadoop.ipc.RPC这个类来实现的。hadoop.ipc.RPC类中有两个重要的函数RPC.Builder和getProxy。RPC.Builder通过接口协议实现的实体来获取真正的server,getProxy获取远程访问的本地代理。
02.FileSystem数据流
1. 剖析文件读取
从HDFS读取到本地代码
Configuration conf = new Configuration();
conf.set("fs.defaultFS", "hdfs://master:9000/");
FileSystem fs = FileSystem.get(conf);
FSDataInputStream is = fs.open(new Path(……));
FileOutputStream os = new FileInputStream("D:/test.txt");

FileSystem.get()方法
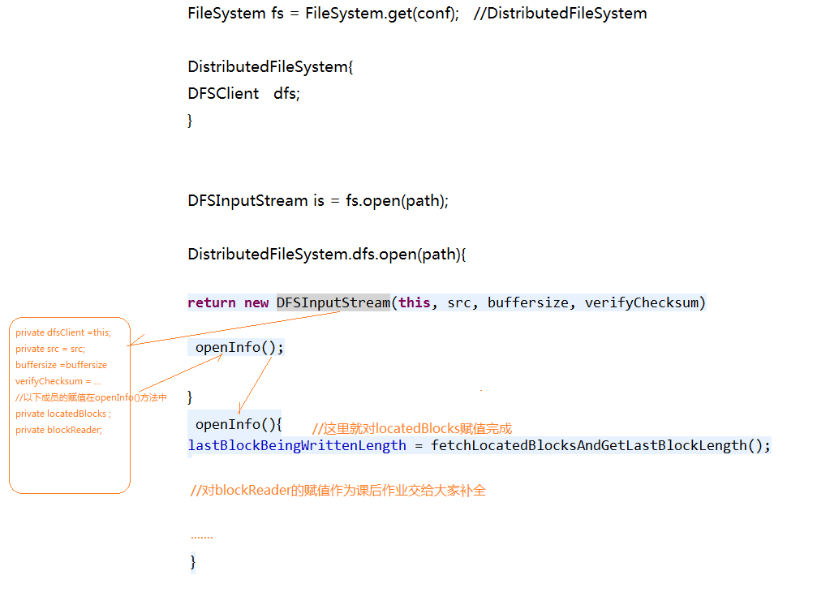
- FileSystem.get(conf)获取文件对象的实例对象。通过配置文件的conf信息判断,返回一个DistributedFileSystem的class,再通过反射DistributedFileSystem的实例并返回。
- DistributedFileSystem中有一个成员DFSClient,这个成员在初始化时,就是初始化自己的ClientProtocal代理对象(名称就是namenode),ClientProtocal是使用RPC框架和NN通信的客户端代理对象。
FileSystem.open(path)过程
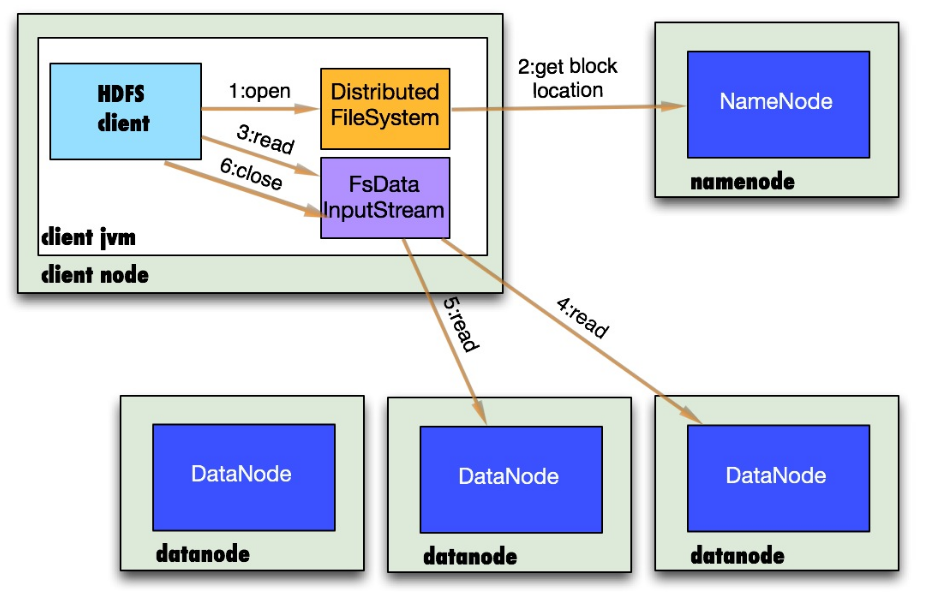
- 首先调用FileSystem对象的open方法,其实DistributedFileSystem实例的DFSClient成员在调用open().
- DistributedFileSystem通过rpc(上述:DFSClient中的namenode代理)获得文件的第一批个block的locations,同一block按照重复数会返回多个locations,这些locations按照hadoop拓扑结构排序,距离客户端近的排在前面.
- fs.open()方法,返回文件系统输入流FSDataInputStream,该对象会被封装成DFSInputStream对象,这个类管理着DataNode和NameNode的I/O。客户端调用read方法,DFSInputStream最会找出离客户端最近的datanode并连接。
- 数据从datanode源源不断的流向客户端。
- 如果第一块的数据读完了,就会关闭指向第一块的datanode连接,接着读取下一块。这些操作对客户端来说是透明的,客户端的角度看来只是读一个持续不断的流。
- 如果第一批block都读完了,DFSInputStream就会去namenode拿下一批blocks的location,然后继续读,如果所有的块都读完,这时就会关闭掉所有的流。
以下是代码实现过程
Ps:客户端直接连接datanode来读取数据,namenode来负责为每一个block提供最优的datanode,namenode仅仅处理block location的请求,这些元数据都加载在namenode的内存中,hdfs通过datanode集群可以承受大量客户端的并发访问。
2. 剖析文件写入
步骤
新建一个文件,把数据从客户端写入,最后关闭文件。
- 过程和读取类似,通过FileSystem的实例对象DistributedFileSystem.create()返回FSDataOutputStream,其中的ClientProtocal代理对象就是对NameNode的RPC调用.
- 在文件系统命名空间创建一个文件,NameNode通过各项检查确保这个文件不存在和客户端创建权限。和之前相似,FSDataOutputStream封装着一个DFSOutputStream,负责DataNode和NameNode的通信。
- DFSOutputStream会将数据分成一个个数据包,写入内部队列,DataStream处理数据队列,它的责任是根据DataNode列表来要求NameNode分配合适的新块来存储数据副本。dataStream将数据包流式传输到一个DataNode中,这个DataNode会传输到别的DataNode中。
详细过程参考博客《http://blog.csdn.net/lastsweetop/article/details/9065667》
03.复本的存放
NameNode节点选择一个datanode节点去存储block副本得过程就叫做副本存放,这个过程的策略其实就是在可靠性和读写带宽间得权衡。
《Hadoop权威指南》中的默认方式:
- 第一个复本会随机选择,但是不会选择存储过满的节点。
- 第二个复本放在和第一个复本不同且随机选择的机架上。
- 第三个和第二个放在同一个机架上的不同节点上。
- 剩余的副本就完全随机节点了。
复本为3的系统管线:

可以看出这个方案比较合理:
1.可靠性:block存储在两个机架上
2.写带宽:写操作仅仅穿过一个网络交换机
3.读操作:选择其中得一个机架去读
4.block分布在整个集群上。
参考《Hadoop权威指南》和博客《http://blog.csdn.net/lastsweetop/article/details/9065667》
初接触,记下学习笔记,还有很多问题,望指导,谢谢。
Hadoop_HDFS文件读写代码流程解析和副本存放机制的更多相关文章
- 02-测试、文件读写、xml解析
测试 黑盒测试 测试逻辑业务 白盒测试 测试逻辑方法 根据测试粒度 方法测试:function test 单元测试:unit test 集成测试:integration test 系统测试:syste ...
- (转)linux文件读写的流程
转自http://hi.baidu.com/_kouu/item/4e9db87580328244ef1e53d0 在<linux内核虚拟文件系统浅析>这篇文章中,我们看到文件是如何被打开 ...
- bluetooth(蓝牙) AVRCP协议概念及代码流程解析
一 概念 AVRCP全称:The Audio/Video Remote Control Profile (AVRCP) 翻译成中文就是:音视频远程控制协议.概念:AVRCP定义了蓝牙设备之间的音视频传 ...
- Hbase flusher源码解析(flush全代码流程解析)
版权声明:本文为博主原创文章,遵循版权协议,转载请附上原文出处链接和本声明. 在介绍HBASE flush源码之前,我们先在逻辑上大体梳理一下,便于后续看代码.flush的整体流程分三个阶段 1.第一 ...
- Android多线程断点下载的代码流程解析
Step 1:创建一个用来记录线程下载信息的表 创建数据库表,于是乎我们创建一个数据库的管理器类,继承SQLiteOpenHelper类 重写onCreate()与onUpgrade()方法 DBOp ...
- HDFS API 文件读写代码演示
一:准备工作 1.新建class类 2.开启HDFS服务 3.将配置文件拷贝进resources路径 方便了Configuration的读取配置. 二:读出HDFS文件系统中的文件到控制台 4.读出在 ...
- 012 HDFS API 文件读写代码演示
一:准备工作 1.新建class类 2.开启HDFS服务 3.将配置文件拷贝进resources路径 方便了Configuration的读取配置. 二:读出HDFS文件系统中的文件到控制台 4.读出在 ...
- Python基础(十六):文件读写,靠这一篇就够了!
文件读写的流程 类比windows中手动操作txt文档,说明python中如何操作txt文件? 什么是文件的内存对象(文件句柄)? 演示怎么读取文件 ① 演示如下 f = open(r"D: ...
- 【Hadoop】二、HDFS文件读写流程
(二)HDFS数据流 作为一个文件系统,文件的读和写是最基本的需求,这一部分我们来了解客户端是如何与HDFS进行交互的,也就是客户端与HDFS,以及构成HDFS的两类节点(namenode和dat ...
随机推荐
- 重新想象 Windows 8.1 Store Apps (79) - 控件增强: MediaElement, Frame
[源码下载] 重新想象 Windows 8.1 Store Apps (79) - 控件增强: MediaElement, Frame 作者:webabcd 介绍重新想象 Windows 8.1 St ...
- 解决死锁SQL
USE [master]GO/****** Object: StoredProcedure [dbo].[p_lockinfo] Script Date: 04/03/2014 15:12:40 ** ...
- fibonacci封闭公式
Description 2007年到来了.经过2006年一年的修炼,数学神童zouyu终于把0到100000000的Fibonacci数列 (f[0]=0,f[1]=1;f[i] = f[i-1]+f ...
- windows下使用makecert命令生成自签名证书
1.makecert命令路径 C:\Program Files (x86)\Windows Kits\8.1\bin\x64 2.生成一个自签名证书 makecert -r -pe -n " ...
- 通过一个小问题来学习SQL关联查询
原话题: 是关于一个left join的,没有技术难度,但不想清楚不一定能回答出正确答案来: TabA表有三个字段Id,Col1,Col2 且里面有一条数据1,1,2 TabB表有两个字段Id,Col ...
- ThoughtWorks西邮暑期特训营 -- JavaScript在线笔试题
ThoughtWorks 公司在西邮正式开办的只教女生前端开发的女子卓越实验室已经几个月过去了,这次计划于暑期在西邮内部开展面向所有性别所有专业的前端培训. 具体官方安排请戳:ThoughtWorks ...
- 【GOF23设计模式】建造者模式
来源:http://www.bjsxt.com/ 一.[GOF23设计模式]建造者模式详解类图关系 建造飞船 package com.test.Builder; public class AirShi ...
- COMMIT WORK AND WAIT 是在WAIT什么
wait 还是不wait,这是个问题. 这是同步更新还是异步更新的问题:如果是只commit work,是异步更新,触发注册在当前SAP LUW中所有数据更新动作,数据更新动作由SAP的更 ...
- Office2016体验
Microsoft又迎来了更新的季节.对于我来说,win10就算了,不太稳定,特别是遇到一些专业的程序,因为很多行业软件开发.测试环境都是winxp或win7等:VS2015也安上了,但还没用,一直用 ...
- 通过源码理解UST(用户栈回溯)
UST原理:如果gflags标志中包含了UST标志,堆管理器会为当前进程分配一块内存,这个内存区域就是UST数据库(user-mode stack trace database),并建立一个STACK ...