Python学习笔记-Day5
冒泡算法:
实现1:
a = [,,,,,,,,,,,,,,]
def bubble(badlist):
sort = False
while not sort:
sort = True
for i in range(len(badlist)-):
if badlist[i]>badlist[i+]:
sort = False
badlist[i],badlist[i+] = badlist[i+],badlist[i]
bubble(a)
print(a)
实现2
data = [10,4,33,21,54,3,8,11,5,22,2,1,17,13,6] for j in range(len(data)):
for i in range(len(data)-1): if data[i] > data[i+1]:
data[i+1],data[i] = data[i],data[i+1]
# tmp=data[i]
#
# data[i] = data[i+1]
#
# data[i+1] = tmp
print(data)
(1)时间频度 一个算法执行所耗费的时间,从理论上是不能算出来的,必须上机运行测试才能知道。但我们不可能也没有必要对每个算法都上机测试,只需知道哪个算法花费的时间多,哪个算法花费的时间少就可以了。并且一个算法花费的时间与算法中语句的执行次数成正比例,哪个算法中语句执行次数多,它花费时间就多。一个算法中的语句执行次数称为语句频度或时间频度。记为T(n)。
 而呈
而呈for (i=1; i<=n; i++)
x++;
for (i=1; i<=n; i++)
for (j=1; j<=n; j++)
x++;
第一个for循环的时间复杂度为Ο(n),第二个for循环的时间复杂度为Ο(n2),则整个算法的时间复杂度为Ο(n+n2)=Ο(n2)。
常数时间
若对于一个算法, 的上界与输入大小无关,则称其具有常数时间,记作
的上界与输入大小无关,则称其具有常数时间,记作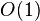 时间。一个例子是访问数组中的单个元素,因为访问它只需要一条指令。但是,找到无序数组中的最小元素则不是,因为这需要遍历所有元素来找出最小值。这是一项线性时间的操作,或称
时间。一个例子是访问数组中的单个元素,因为访问它只需要一条指令。但是,找到无序数组中的最小元素则不是,因为这需要遍历所有元素来找出最小值。这是一项线性时间的操作,或称 时间。但如果预先知道元素的数量并假设数量保持不变,则该操作也可被称为具有常数时间。
时间。但如果预先知道元素的数量并假设数量保持不变,则该操作也可被称为具有常数时间。
对数时间
若算法的T(n) = O(log n),则称其具有对数时间
对数时间的算法是非常有效的,因为每增加一个输入,其所需要的额外计算时间会变小。
递归地将字符串砍半并且输出是这个类别函数的一个简单例子。它需要O(log n)的时间因为每次输出之前我们都将字符串砍半。 这意味着,如果我们想增加输出的次数,我们需要将字符串长度加倍。
线性时间
如果一个算法的时间复杂度为O(n),则称这个算法具有线性时间,或O(n)时间。非正式地说,这意味着对于足够大的输入,运行时间增加的大小与输入成线性关系。例如,一个计算列表所有元素的和的程序,需要的时间与列表的长度成正比。
随机数
>>> import random
>>> print(random.random())
0.6153296567923066
>>> print (random.randint(1,20))
16
>>> print (random.randint(1,20))
11
>>> print (random.randrange(1,20))
13
>>> print (random.randrange(1,20))
3
>>> print (random.randrange(1,20))
13
>>>
验证码实例:
import random check_code = ""
for i in range(6):
current = random.randint(0,4)
if current != i:
tmp = chr(random.randint(65,90))
else:
tmp = random.randint(0,9)
check_code += str(tmp)
print(check_code)
OS模块
提供对操作系统进行调用的接口
os.getcwd() 获取当前工作目录,即当前python脚本工作的目录路径
os.chdir("dirname") 改变当前脚本工作目录;相当于shell下cd
os.curdir 返回当前目录: ('.')
os.pardir 获取当前目录的父目录字符串名:('..')
os.makedirs('dirname1/dirname2') 可生成多层递归目录
os.removedirs('dirname1') 若目录为空,则删除,并递归到上一级目录,如若也为空,则删除,依此类推
os.mkdir('dirname') 生成单级目录;相当于shell中mkdir dirname
os.rmdir('dirname') 删除单级空目录,若目录不为空则无法删除,报错;相当于shell中rmdir dirname
os.listdir('dirname') 列出指定目录下的所有文件和子目录,包括隐藏文件,并以列表方式打印
os.remove() 删除一个文件
os.rename("oldname","newname") 重命名文件/目录
os.stat('path/filename') 获取文件/目录信息
os.sep 输出操作系统特定的路径分隔符,win下为"\\",Linux下为"/"
os.linesep 输出当前平台使用的行终止符,win下为"\t\n",Linux下为"\n"
os.pathsep 输出用于分割文件路径的字符串
os.name 输出字符串指示当前使用平台。win->'nt'; Linux->'posix'
os.system("bash command") 运行shell命令,直接显示
os.environ 获取系统环境变量
os.path.abspath(path) 返回path规范化的绝对路径
os.path.split(path) 将path分割成目录和文件名二元组返回
os.path.dirname(path) 返回path的目录。其实就是os.path.split(path)的第一个元素
os.path.basename(path) 返回path最后的文件名。如何path以/或\结尾,那么就会返回空值。即os.path.split(path)的第二个元素
os.path.exists(path) 如果path存在,返回True;如果path不存在,返回False
os.path.isabs(path) 如果path是绝对路径,返回True
os.path.isfile(path) 如果path是一个存在的文件,返回True。否则返回False
os.path.isdir(path) 如果path是一个存在的目录,则返回True。否则返回False
os.path.join(path1[, path2[, ...]]) 将多个路径组合后返回,第一个绝对路径之前的参数将被忽略
os.path.getatime(path) 返回path所指向的文件或者目录的最后存取时间
os.path.getmtime(path) 返回path所指向的文件或者目录的最后修改时间
os.popen(bash command).read() 返回命令执行结果,可以赋值保存
sys模块
sys.argv 命令行参数List,第一个元素是程序本身路径
sys.exit(n) 退出程序,正常退出时exit(0)
sys.version 获取Python解释程序的版本信息
sys.maxint 最大的Int值
sys.path 返回模块的搜索路径,初始化时使用PYTHONPATH环境变量的值
sys.platform 返回操作系统平台名称
sys.stdout.write('please:')
val = sys.stdin.readline()[:-1]
序列化模块
用于序列化的两个模块
- json,用于字符串 和 python数据类型间进行转换
- pickle,用于python特有的类型 和 python的数据类型间进行转换
Json模块提供了四个功能:dumps、dump、loads、load
pickle模块提供了四个功能:dumps、dump、loads、load
import pickle,json # pickle只有python支持 它可以序列化函数
f = open('user_acc.txt',"wb") #json只支持序列化字符串
user_info = {
"name":"alex",
"jack":"3333",
}
f.write(pickle.dumps(user_info))
f.close() f = open("user_acc.txt","rb") data = pickle.loads(f.read())
for i in data:
print(i,data)
Python学习笔记-Day5的更多相关文章
- Python学习笔记——Day5(转载)
python 编码转换 主要介绍了python的编码机制,unicode, utf-8, utf-16, GBK, GB2312,ISO-8859-1 等编码之间的转换. 常见的编码转换分为以下几种情 ...
- Python学习笔记day5
模块 1.自定义模块 自定义模块就是在当前目录下创建__init__.py这个空文件,这样外面的程序才能识别此目录为模块包并导入 上图中libs目录下有__init__.py文件,index.py程序 ...
- Python学习笔记 - day5 - 文件操作
Python文件操作 读写文件是最常见的IO操作,在磁盘上读写文件的功能都是由操作系统提供的,操作系统不允许普通的程序直接操作磁盘(大部分程序都需要间接的通过操作系统来完成对硬件的操作),所以,读写文 ...
- 【目录】Python学习笔记
目录:Python学习笔记 目标:坚持每天学习,每周一篇博文 1. Python学习笔记 - day1 - 概述及安装 2.Python学习笔记 - day2 - PyCharm的基本使用 3.Pyt ...
- Python学习笔记,day5
Python学习笔记,day5 一.time & datetime模块 import本质为将要导入的模块,先解释一遍 #_*_coding:utf-8_*_ __author__ = 'Ale ...
- Python学习记录day5
title: Python学习记录day5 tags: python author: Chinge Yang date: 2016-11-26 --- 1.多层装饰器 多层装饰器的原理是,装饰器装饰函 ...
- python学习笔记整理——字典
python学习笔记整理 数据结构--字典 无序的 {键:值} 对集合 用于查询的方法 len(d) Return the number of items in the dictionary d. 返 ...
- VS2013中Python学习笔记[Django Web的第一个网页]
前言 前面我简单介绍了Python的Hello World.看到有人问我搞搞Python的Web,一时兴起,就来试试看. 第一篇 VS2013中Python学习笔记[环境搭建] 简单介绍Python环 ...
- python学习笔记之module && package
个人总结: import module,module就是文件名,导入那个python文件 import package,package就是一个文件夹,导入的文件夹下有一个__init__.py的文件, ...
随机推荐
- My Package
一.新建一文件夹,名称为MyBase,存放Java的基本类. 二.在MyBase包中创建基本类Base.java. package MyBase; public class Base { public ...
- OAF_文件系列3_实现OAF多行表中附件功能AttachmentImage(案例)
20150727 Created By BaoXinjian
- ADF_Controller系列1_绑定TasksFlow、Region和Routers(Part1)
2015-02-14 Created By BaoXinjian
- MSSQL导入导出数据
/******* 导出到excel */ EXEC master..xp_cmdshell 'bcp SettleDB.dbo.shanghu out c:\temp1.xls -c -q -S&qu ...
- FMDB最简单的教程-3 清空数据表并将自增字段清零
[db executeUpdate:@"DELETE FROM MemberInfo"]; [db executeUpdate:@"UPDATE sqlite_seque ...
- http的header参数有关
1.读文件 a.如果经过php处理:变成mime:text/html,在浏览器可以打开.否则是下载 b.phpui如果加上参数resid=01,那么返回的数据的Content-Type:applica ...
- Java反射得到属性的值和设置属性的值(转)
package com.whbs.bean; public class UserBean { private Integer id; private int age; private String n ...
- SBT 构建scala eclipse开发
scala eclipse sbt 应用程序开发 搭建Eclipse开发Scala应用程序的一般步骤 一.环境准备: 1.Scala : http://www.scala-lang.org/ 2.Sc ...
- Cadence UVM基础视频介绍(UVM SV Basics)
Cadence关于UVM的简单介绍,包括UVM的各个方面.有中文和英文两种版本. UVM SV Basics 1 – Introduction UVM SV Basics 2 – DUT Exampl ...
- CentOS 安装 chrome 浏览器
安装 google-chrome 浏览器,由于众所周知的原因,一直安装不了,下面介绍一种新方法. cd 到 /etc/yum.repos.d 创建一个yum新源 vi chromium-el6.rep ...