Hadoop下面WordCount运行详解
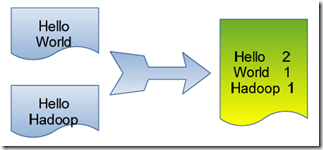
单词计数是最简单也是最能体现MapReduce思想的程序之一,可以称为MapReduce版"Hello World",该程序的完整代码可以在Hadoop安装包的"src/examples"目录下找到。单词计数主要完成功能是:统计一系列文本文件中每个单词出现的次数,如下图所示。
现在我们以"hadoop"用户登录"Master.Hadoop"服务器。
1. 创建本地的示例数据文件:
依次进入【Home】-【hadoop】-【hadoop-1.2.1】创建一个文件夹file用来存储本地原始数据。
并在这个目录下创建2个文件分别命名为【myTest1.txt】和【myTest2.txt】或者你想要的任何文件名。
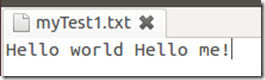
分别在这2个文件中输入下列示例语句:

2. 在HDFS上创建输入文件夹
呼出终端,输入下面指令:
bin/hadoop fs -mkdir hdfsInput
执行这个命令时可能会提示类似安全的问题,如果提示了,请使用
bin/hadoop dfsadmin -safemode leave
来退出安全模式。
当分布式文件系统处于安全模式的情况下,文件系统中的内容不允许修改也不允许删除,直到安全模式结 束。安全模式主要是为了系统启动的时候检查各个DataNode上数据块的有效性,同时根据策略必要的复制或者删除部分数据块。运行期通过命令也可以进入 安全模式。
意思是在HDFS远程创建一个输入目录,我们以后的文件需要上载到这个目录里面才能执行。
3. 上传本地file中文件到集群的hdfsInput目录下
在终端依次输入下面指令:
cd hadoop-1.2.1
bin/hadoop fs -put file/myTest*.txt hdfsInput

4. 运行例子:
在终端输入下面指令:
bin/hadoop jar hadoop-examples-1.2.1.jar wordcount hdfsInput hdfsOutput
注意,这里的示例程序是1.2.1版本的,可能每个机器有所不一致,那么请用*通配符代替版本号
bin/hadoop jar hadoop-examples-*.jar wordcount hdfsInput hdfsOutput
应该出现下面结果:
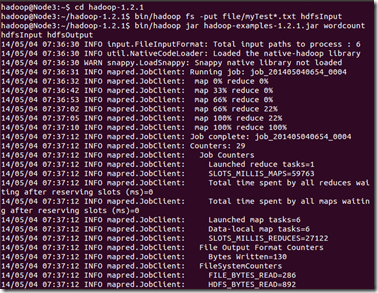
Hadoop命令会启动一个JVM来运行这个MapReduce程序,并自动获得Hadoop的配置,同时把类的路径(及其依赖关系)加入到Hadoop的库中。以上就是Hadoop Job的运行记录,从这里可以看到,这个Job被赋予了一个ID号:job_201202292213_0002,而且得知输入文件有两个(Total input paths to process : 2),同时还可以了解map的输入输出记录(record数及字节数),以及reduce输入输出记录。
查看HDFS上hdfsOutput目录内容:
在终端输入下面指令:
bin/hadoop fs -ls hdfsOutput

从上图中知道生成了三个文件,我们的结果在"part-r-00000"中。
使用下面指令查看结果输出文件内容
bin/hadoop fs -cat output/part-r-00000

(注意:请忽视截图指令中的3)
输出目录日志以及输入目录中的文件是永久存在的,如果不删除的话,如果出现结果不一致,请参考这个因素。
Hadoop下面WordCount运行详解的更多相关文章
- Hadoop集群WordCount运行详解(转)
原文链接:Hadoop集群(第6期)_WordCount运行详解 1.MapReduce理论简介 1.1 MapReduce编程模型 MapReduce采用"分而治之"的思想,把对 ...
- WordCount运行详解
1.MapReduce理论简介 1.1 MapReduce编程模型 MapReduce采用"分而治之"的思想,把对大规模数据集的操作,分发给一个主节点管理下的各个分节点共同完成,然 ...
- [转]Hadoop集群_WordCount运行详解--MapReduce编程模型
Hadoop集群_WordCount运行详解--MapReduce编程模型 下面这篇文章写得非常好,有利于初学mapreduce的入门 http://www.nosqldb.cn/1369099810 ...
- hadoop应用开发技术详解
<大 数据技术丛书:Hadoop应用开发技术详解>共12章.第1-2章详细地介绍了Hadoop的生态系统.关键技术以及安装和配置:第3章是 MapReduce的使用入门,让读者了解整个开发 ...
- 《Hadoop应用开发技术详解》
<Hadoop应用开发技术详解> 基本信息 作者: 刘刚 丛书名: 大数据技术丛书 出版社:机械工业出版社 ISBN:9787111452447 上架时间:2014-1-10 出版日期:2 ...
- Hadoop Hive sql语法详解
Hadoop Hive sql语法详解 Hive 是基于Hadoop 构建的一套数据仓库分析系统,它提供了丰富的SQL查询方式来分析存储在Hadoop 分布式文件系统中的数据,可以将结构 化的数据文件 ...
- Hadoop生态圈-Kafka配置文件详解
Hadoop生态圈-Kafka配置文件详解 作者:尹正杰 版权声明:原创作品,谢绝转载!否则将追究法律责任. 一.默认kafka配置文件内容([yinzhengjie@s101 ~]$ more /s ...
- Hadoop基础-Idea打包详解之手动添加依赖(SequenceFile的压缩编解码器案例)
Hadoop基础-Idea打包详解之手动添加依赖(SequenceFile的压缩编解码器案例) 作者:尹正杰 版权声明:原创作品,谢绝转载!否则将追究法律责任. 一.编辑配置文件(pml.xml)(我 ...
- Java程序在内存中运行详解
目录 Java程序在内存中运行详解 一.JVM的内存分布 二.程序执行的过程 三.只有一个对象时的内存图 四.两个对象使用同一个方法的内存图 五.两个引用指向同一个对象的内存图 六.使用对象类型作为方 ...
随机推荐
- 转:RTMPDump源代码分析
0: 主要函数调用分析 rtmpdump 是一个用来处理 RTMP 流媒体的开源工具包,支持 rtmp://, rtmpt://, rtmpe://, rtmpte://, and rtmps://. ...
- SCN试验之一
在数据库运行的时候,数据库系统的SCN不断地增长: SQL> select dbms_flashback.get_system_change_number from dual; GET_SYST ...
- spring发送邮件(多人接收或抄送多少带附件发送)
系统中的附件分享功能界面 抄送多个效果图 多个接收者效果图 抄送多人带附件源码 多个接收者带附件源码
- linux上nginx+apache 搭建 svn服务器
众所周知,nginx目前是不支持svn的,并且由于机房网络只开了80和22(ssh)端口,所以这时候就没法单独在服务器上搭建apache+svn .所以就产生了 nginx + apache + sv ...
- Ejabberd V.S Openfire
ejabberd Openfire homepage https://www.ejabberd.im/ http://www.igniterealtime.org/projects/openfire/ ...
- eclipse android logcat 只显示自己应用程序信息的设置方法
1 elcipse 中往往会在logcat中显示 all message ,而这里面的信息太多,根本没有办法进行区分.如图: 2 我们想显示自己项目的 logcat .下面开始设置. 3 首先点击上面 ...
- Centos单网卡配置多个IP的方法
网上好多介绍一个网卡多个IP的方法,都有些问题,下面是实践可行的方法 DEVICE="eth0" TYPE="Ethernet" BOOTPROTO=none ...
- Nodejs开源项目推荐
当我们学习一门新语言,不要用以前语言的习惯去使用新的语言,这样可能会导致走一些弯路.最好的办法就是去看一些写的比较好的开源项目,所以这里我推荐几个NodeJs的开源项目,花点时间去研究一下他们的实现, ...
- Aspose转PDF时乱码问题的解决
主要原因是服务器上一般安装的字体都是有限的,而我们日常生活工作中总是喜欢用一些比较特别的字体,比如宋体GB2312,这时候如果用Aspose转PDF就会出现乱码,解决方法也比较简单,把本地的特殊字体拷 ...
- Rxlifecycle(一):使用
Rxlifecycle使用非常方便简单,如下: 1.集成 build.gradle添加 //Rxlifecycle compile 'com.trello:rxlifecycle:0.3.1' com ...