java集合 之 set 集合
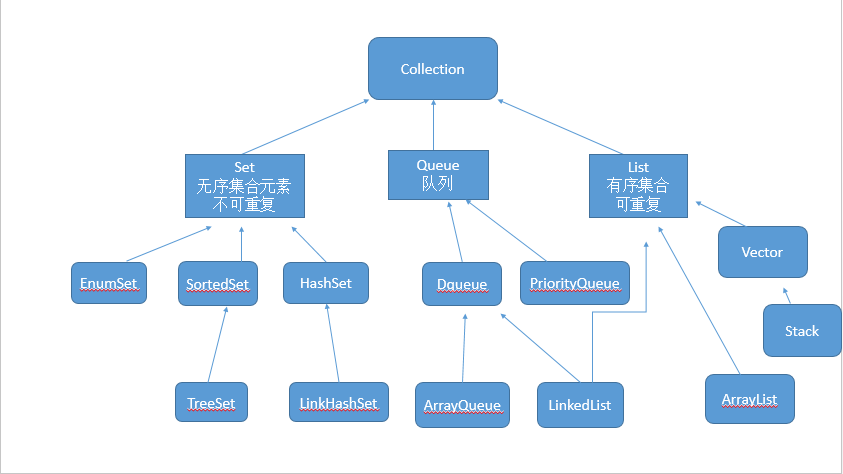
set集合可以存储多个对象,但并不会记住元素的存储顺序,也不允许集合中有重复元素(不同的set集合有不同的判断方法)。
1.HashSet类
HashSet按照Hash算法存储集合中的元素,具有很好的存取和查找性能。当向HashSet中添加一些元素时,HashSet会根据该对象的HashCode()方法来得到该对象的HashCode值,然后根据这些HashCode的值来决定元素的位置。
HashSet的特点:1.存储顺序和添加的顺序不同
2.HashSet不是同步的,如果多个线程同时访问一个HashSet,假设有两个或更多的线程修改了集合中的值,则必须通过代码使线程同步。
3.HastSet允许集合中的元素为null。
在HashSet集合中,判断两个元素相同的标准是:两个对象通过equals()方法相等,且HashCode()方法的返回值也相等。如果有两个元素通过equals()方法比较相等,而HashCode()的返回值不同,HashSet会将这两个对象保存在不同的地方。
注意:如果向HashSet中添加一个可变对象后,后面的对象修改了该可变对象的实例变量,则可能导致它与集合中的其他元素相同。
class R{
int count;
public R(int count){
this.count= count;
}
public String toString(){
return "R[count:" + count + "]";
}
public boolean equals(Object obj){
if (this == obj)
return true;
if (obj != null && obj.getClass() == R.class) {
R r = (R)obj;
return this.count == r.count;
}
return false;
}
public int HashCode(){
return this.count;
}
}
public class HashSetTest {
public static void main(String[] args){
HashSet hs = new HashSet();
hs.add(new R(5));
hs.add(new R(-3));
hs.add(new R(9));
hs.add(new R(-2));
//输出:[R[count:9], R[count:5], R[count:-3], R[count:-2]]
System.out.println(hs);
Iterator it = hs.iterator();
R first = (R)it.next();
first.count = -3;
//输出:[R[count:-3], R[count:5], R[count:-3], R[count:-2]]
System.out.println(hs);
//输出:是否包含count为-3的对象:false
System.out.println("是否包含count为-3的对象:" + hs.contains(new R(-3)));
//输出:是否包含count为-2的对象:false
System.out.println("是否包含count为-2的对象:" + hs.contains(new R(-2)));
}
}
这个例子中代码first.count=-3改变了集合中的实例变量,在应该count为9的地方放入了count为-3的元素,导致HashSet不能准确访问元素。在判断其他元素也会出错,比如判断集合是否包含-2,-3.
(上面这句话是我自己理解的,总感觉不太对,大家帮我看看)
2.LinkedHashSet类
LikedHashSet是HashSet的子类,它也是根据元素的HashCode值进来决定元素的存储位置,但它能够同时使用链表来维护元素的添加次序,使得元素能以插入顺序保存。
public class LinkHashSetTest {
public static void main(String[] args){
LinkedHashSet lh = new LinkedHashSet();
lh.add(1);
lh.add(2);
lh.add(3);
//输出:[1, 2, 3]
System.out.println(lh);
lh.remove(1);
lh.add(1);
//输出:[ 2, 3 ,1]
System.out.println(lh);
}
}
3.TreeSet
TreeSet是SortedSet接口的实现类,TreeSet可以保证了集合元素处于排序状态(所谓排序状态,就是元素按照一定的规则排序,比如升序排列,降序排列)。
与HashSet集合相比。
Comparator comparator():如果TreeSet采用了定制排序,则该方法返回定制排序所使用的Comparator,如果采用了自然排序,则返回null。
Object first(): 返回集合中的第一个元素。
Object last():返回集合中的最后一个元素。
Object lower(Object e):返回集合中位于指定元素e之前的元素(即小于指定元素的最大元素,参考元素e不必是集合中的元素)。
Object higher(Object e): 返回集合中位于指定元素e之后的元素(即大于指定元素的最小元素,参考元素e不必是集合中的元素)。
SortedSet subSet(Object fromElement, Object toElement): 返回集合中所有在fromElemt和toElement之间的元素(包含fromElent本身,不包含toElement本身)。
SortedSet headSet(Object toElement): 返回此set的子集,由小于toElement的元素组成。
SortedSet tailSet(Object fromElement):返回此set的子集,由大于或等于fromElement的元素组成。
public class TreeSetTest {
public static void main(String[] args){
TreeSet ts = new TreeSet();
ts.add(5);
ts.add(2);
ts.add(10);
ts.add(-9);
//输出:null 证明是自然排序
System.out.println(ts.comparator());
//输出:-9
System.out.println(ts.first());
//输出:10
System.out.println(ts.last());
//输出:2
System.out.println(ts.lower(3));
//输出:10
System.out.println(ts.higher(5));
//输出[5, 10]
System.out.println(ts.subSet(3, 12));
//输出:[-9, 2, 5]
System.out.println(ts.headSet(10));
//输出:[5, 10]
System.out.println(ts.tailSet(5));
}
}
TreeSet支持两种排序方法:自然排序和定制排序。在默认的情况下,TreeSet采用自然排序。
自然排序:TreeSet会调用集合元素的compareTo(Object obj)方法来比较元素之间的大小关系,然后让集合按照升序排列,这种方式叫做自然排序。
定制排序:定制排序是按照使用者的要求,需要自己设计的一种排序。如果需要定制排序,比如需要数据按照降序排列,则可以通过Comparator接口的帮助。
PS:
1.如果希望TreeSet能够正常运行,TreeSet只能添加同一种类型的对象。
2.TreeSet集合中判断元素相等的唯一标准是:两个对象通过comparator(Object obj)方法比较后,返回0;否则认为不相等。
3.EnumSet类
EnumSet类是一种专为枚举类设计的集合类,EnumSet中的所有元素都必须是指定枚举类型的枚举值,该枚举类型在创建EnumSe类时显式或隐式的指定。EnumSet的集合元素也是有序的,EnumSet以枚举值在Enum类内的定义顺序来决定集合元素的顺序。
EnumSet提供了如下常用的类方法来创建EnumSet对象:
EnumSet allOf(Class elementType): 创建一个包含指定枚举类中的所有枚举值的EnumSet集合。
EnumSet complement(EnumSet s):创建一个其元素类型与指定EnumSet里元素类型相同的EnumSet集合,新的EnumSet集合包含原来的EnumSet集合所不包含的,此枚举类剩下的枚举值(新的EnumSet集合加上原EnumSet集合中的集合元素就是该枚举类中所有的枚举值)。
EnumSet copyOf(Collection c): 使用一个普通集合来创建EnumSet集合。
EnumSet copyOf(EnumSet s): 创建一个和指定EnumSet集合,同类型同集合元素的EnumSet集合。
EnumSet noneOf(Class elementType): 创建一个元素类型是指定枚举类型的空EnumSet集合。
EnumSet of(E first, E... rest): 创建一个包含一个或者多个枚举值得EnumSet集合,传入的枚举值必须属于同一个枚举类。
EnumSet range(E from, E to):创建一个从from枚举值到to枚举值范围内所有枚举值的EnumSet集合。
enum Season{
SPRING,SUMMER,FALL,WINTER
}
public class EnumSetTest {
public static void main(String[] args){
EnumSet es1 = EnumSet.allOf(Season.class);
//输出:[SPRING, SUMMER, FALL, WINTER]
System.out.println(es1);
EnumSet es2 = EnumSet.noneOf(Season.class);
//输出:[]
System.out.println(es2);
es2.add(Season.WINTER);
es2.add(Season.SPRING);
//输出:[SPRING, WINTER]
System.out.println(es2);
EnumSet es3 = EnumSet.of(Season.SPRING, Season.WINTER);
//输出:[SPRING, WINTER]
System.out.println(es3);
EnumSet es4 = EnumSet.range(Season.SPRING, Season.WINTER);
//输出:[SPRING, SUMMER, FALL, WINTER]
System.out.println(es4);
EnumSet es5 = EnumSet.complementOf(es4);
//输出:[]
System.out.println(es5);
}
}
------------《疯狂java讲义》8.3set集合
java集合 之 set 集合的更多相关文章
- Java常用的几种集合, Map集合,Set集合,List集合
Java中 Object是所有类的根 Java集合常用的集合List集合.Set集合.Map集合 Map接口常用的一些方法 size() 获取集合中名值对的数量 put(key k, value v ...
- Java基础加强之集合篇(模块记忆、精要分析)
千里之行,始于足下.把别人的变成自己,再把自己的分享给别人,这也是一次提升的过程.本文的目的是以一篇文章从整体把握集合体系又不失一些细节上的实现,高手路过. 集合的作用与特点 Java是一门面向对象语 ...
- Java中如何克隆集合——ArrayList和HashSet深拷贝
编程人员经常误用各个集合类提供的拷贝构造函数作为克隆List,Set,ArrayList,HashSet或者其他集合实现的方法.需要记住的是,Java集合的拷贝构造函数只提供浅拷贝而不是深拷贝,这意味 ...
- Java多线程系列--“JUC集合”02之 CopyOnWriteArrayList
概要 本章是"JUC系列"的CopyOnWriteArrayList篇.接下来,会先对CopyOnWriteArrayList进行基本介绍,然后再说明它的原理,接着通过代码去分析, ...
- Java多线程系列--“JUC集合”03之 CopyOnWriteArraySet
概要 本章是JUC系列中的CopyOnWriteArraySet篇.接下来,会先对CopyOnWriteArraySet进行基本介绍,然后再说明它的原理,接着通过代码去分析,最后通过示例更进一步的了解 ...
- Java多线程系列--“JUC集合”04之 ConcurrentHashMap
概要 本章是JUC系列的ConcurrentHashMap篇.内容包括:ConcurrentHashMap介绍ConcurrentHashMap原理和数据结构ConcurrentHashMap函数列表 ...
- Java多线程系列--“JUC集合”05之 ConcurrentSkipListMap
概要 本章对Java.util.concurrent包中的ConcurrentSkipListMap类进行详细的介绍.内容包括:ConcurrentSkipListMap介绍ConcurrentSki ...
- Java多线程系列--“JUC集合”06之 ConcurrentSkipListSet
概要 本章对Java.util.concurrent包中的ConcurrentSkipListSet类进行详细的介绍.内容包括:ConcurrentSkipListSet介绍ConcurrentSki ...
- Java多线程系列--“JUC集合”07之 ArrayBlockingQueue
概要 本章对Java.util.concurrent包中的ArrayBlockingQueue类进行详细的介绍.内容包括:ArrayBlockingQueue介绍ArrayBlockingQueue原 ...
- Java多线程系列--“JUC集合”08之 LinkedBlockingQueue
概要 本章介绍JUC包中的LinkedBlockingQueue.内容包括:LinkedBlockingQueue介绍LinkedBlockingQueue原理和数据结构LinkedBlockingQ ...
随机推荐
- SQL Server里PIVOT运算符的”红颜祸水“
在今天的文章里我想讨论下SQL Server里一个特别的T-SQL语言结构——自SQL Server 2005引入的PIVOT运算符.我经常引用这个与语言结构是SQL Server里最危险的一个——很 ...
- 改造一下C# Substring()函数
C#的Substring()函数中,如果我们一不小心输入一个截取长度大于字符串的长时,就会收到一个异常:startIndex cannot be larger than length of strin ...
- Ext.GridPanel 用法总结(一)—— Grid基本用法
Ext.GridPanel 用法总结(一)—— Grid基本用法 摘自:http://www.cnblogs.com/luluping/archive/2009/08/01/1536645.html ...
- 【jQuery基础学习】05 jQuery与Ajax以及序列化
好吧,这章不像上章那么水了,总是炒剩饭也不好. 关于AJAX 所谓Ajax,全名Asynchronous JavaScript and XML.(也就异步的JS和XML) 简单点来讲就是不刷新页面来发 ...
- javascript类的理解和使用
距离上次写博客已经过去好几个月了,现在手里的项目正好都结束了,闲暇之后开始理一下开发中一些问题,这次说一下javascript当中的类,可能很多人对于写惯了前台页面效果的coder来说,对于javas ...
- 后缀数组---New Distinct Substrings
Description Given a string, we need to find the total number of its distinct substrings. Input T- nu ...
- mysql命令行备份数据库
MySQL数据库使用命令行备份|MySQL数据库备份命令 例如: 数据库地址:127.0.0.1 数据库用户名:root 数据库密码:pass 数据库名称:myweb 备份数据库到D盘跟目录 mysq ...
- [mysql] timestamp自动更新和初始化
1.概述 在我们设计表的时候,考虑将行数据的创建时间和最后更新时间记录下来是很好的实践.尤其是可能需要做数据同步或者对数据新鲜度有要求的表.举些应用场景,更新距上次更新超过2小时的行数据,或者是将一个 ...
- 关于IE中通过http-equiv="X-UA-Compatible指定文件兼容性模式
.csharpcode, .csharpcode pre { font-size: small; color: black; font-family: consolas, "Courier ...
- 【翻译】配置RSVP-signaled LSP
源地址: https://www.juniper.net/techpubs/software/junos-security/junos-security10.2/junos-security-swco ...