GaussDB(for Influx)与开源企业版性能对比
摘要:相比于企业版InfluxDB,GaussDB(for Influx)能为客户提供更高的写入能力、更稳定的查询能力、更高的数据压缩率,高效满足各大时序应用场景需求。
本文分享自华为云社区《华为云GaussDB(for Influx)揭秘第八期:GaussDB(for Influx)与开源企业版性能对比》,作者:高斯Influx官方博客 。
“你们的数据库性能怎么样?”
“能不能满足我们的业务?”
“和其他数据库对比性能有优势么?”
…
客户在使用数据库时常有这样的担心和疑问。
本文从测试方案、测试工具、测试场景、测试结果等方面详细介绍了GaussDB(for Influx)和开源InfluxDB集群在X86架构下的性能测试情况。测试结果显示,GaussDB(for Influx)较企业版InfluxDB集群能提供更高的写入性能、更低的访问延迟以及更高的数据压缩率。
1. 测试方案
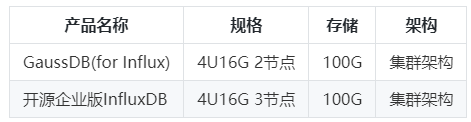
1.1 资源配置
服务端配置
1.2 测试工具
测试工具为开源性能工具TS-benchMark。
2. 测试设计
2.1 测试模型
本次测试采用风力发电数据模型,每个风场50个设备,每个设备50个传感器,1个风场1个线程,通过load数据的线程数来控制时间线的大小,通过收集时间的长短来控制数据量。
模型每条数据大小约为24字节,具体的类型如下:
Timestamp | farm | device |sensor | value
2.2 测试数据量
测试数据分为两个场景,大数据量和小数据量,具体数据量如下:

注:企业版InfluxDB在插入到47亿数据时OOM,以下性能对比都基于此数据量。
2.3 测试场景
2.3.1 数据写入场景
- batch_size(每个批次写入的数据量) 固定为50,线程数分别从1、2、4、8、16、32、64、128、256、512 递增;
- 线程数(客户端并发请求的连接数)固定为8, batch_size分别从50、100、150、200、250、300 递增。
2.3.2 数据查询场景
单线程进行不同语句的查询,并统计其时延信息。
第一类查询: 所有TAG查询
select *
from sensor
where f='f1' and d='d2' and s='s1' and time>=1514768400000000000 and time<=1514772000000000000
第二类查询: TAG + VALUE查询
select *
from sensor
where f='f1' and s='d2' and value>=3.0 and time>=1514768400000000000 and time<1514854800000000000
第三类查询: 聚合查询
select mean(value)
from sensor
where f='f1' and s='s1' and time>=1514768400000000000 and time<=1514854800000000000 group by f,d,s,time(1h)
第四类查询: 或条件查询
select *
from sensor
where f='f1' and (s='s1' or s='s2' or s='s3' or s='s4' or s='s5') and time>=1514768400000000000 and time<=1514769150000000000
第五类查询: 单个TAG查询
select *
from sensor
where f='f1' and time>=1514768400000000000 and time<=1514769150000000000
3. 测试结果分析
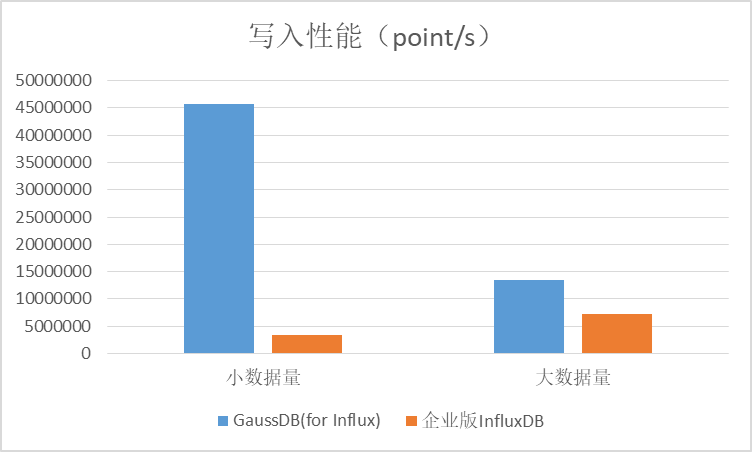
3.1 写入吞性能比对
在小数据量场景下,GaussDB(for Influx)的写入性能是企业版InfluxDB的13倍左右,在大数据量的场景下可以达到1.8倍左右。
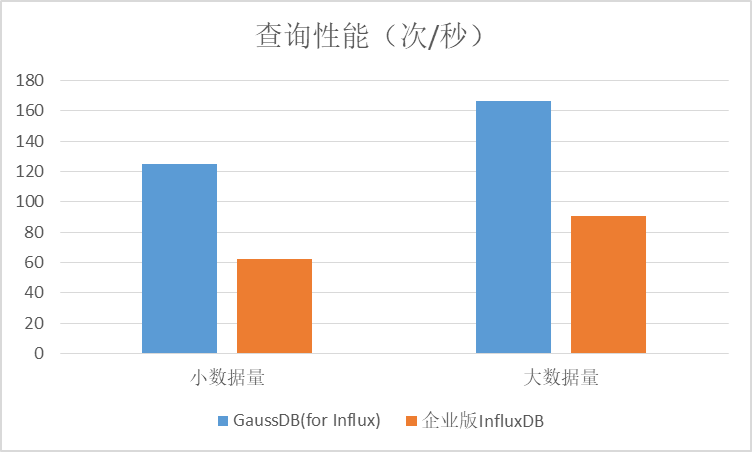
3.2 查询性能对比
1)第一类查询(所有TAG查询):无论是大数据量还是小数据量场景下,GaussDB(for Influx)的吞吐量是开源InfluxDB企业版的2倍左右。
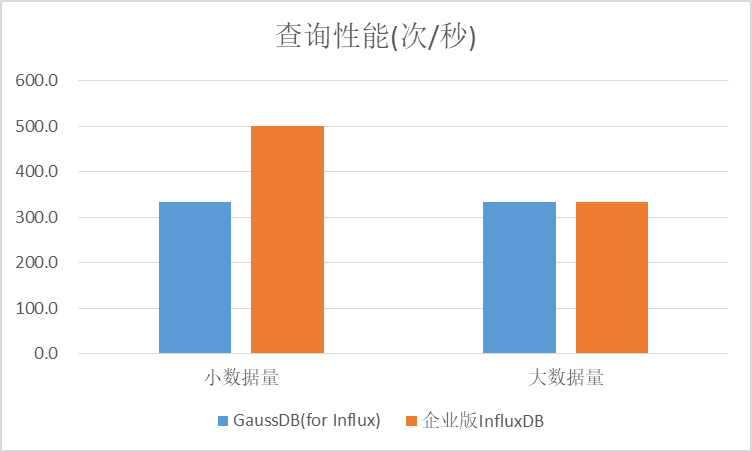
2)第二类查询(TAG + VALUE查询):在小数据量场景下,开源InfluxDB企业版性能高于GaussDB(for Influx),GaussDB(for Influx)在大数据量和小数据量场景下性能基本持平。
3)第三类查询(聚合查询):GaussDB(for Influx)查询性能明显优于开源InfluxDB企业版,在小数据量场景下是开源版本的14倍,大数据量下也是开源版本的8倍左右。
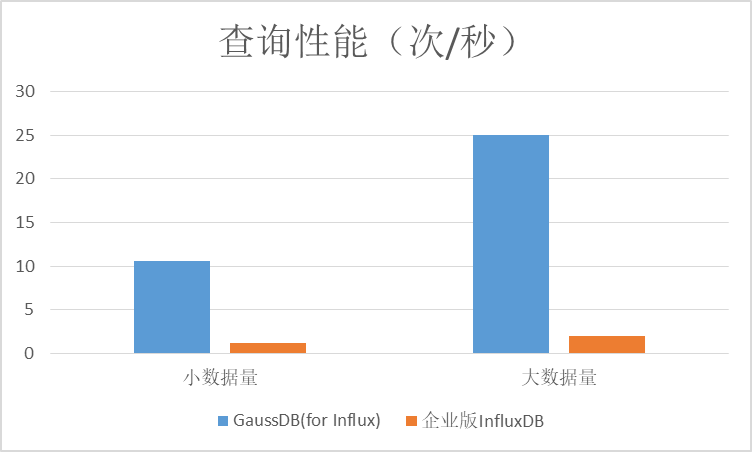
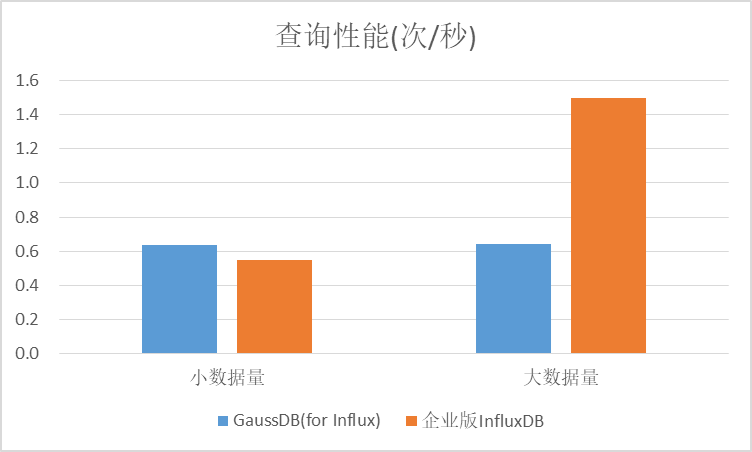
4)第四类查询(或条件查询):GaussDB(for Influx)查询性能在两种场景下比较稳定,开源企业版InfluxDB在两种场景下差异较大;GaussDB(for Influx)在小数据量场景下表现优于开源版,在大数据量场景下低于开源版。

5)第五类查询(单个TAG查询):GaussDB(for Influx)查询性能在两种场景下比较稳定,在大数据量场景下低于开源版。
3.3 数据压缩率对比
在250万时间线场景下,GaussDB(for Influx)导入了151亿条数据,导入前数据大小为337.5G,导入后为49.8G,压缩率为6.8;开源企业版导入了47亿条数据,导入前105G,导入后21.3G,压缩率为4.9。GaussDB(for Influx)压缩率是开源企业版的1.4倍左右。
Influx引擎采用LSM tree架构,随着后台compaction的进行,压缩率会进一步提升,当前数据对比是数据刚导入时的结果。
4. 总结
在GaussDB(for Influx)2节点对比开源版3节点场景下,GaussDB(for Influx)给客户带来了更高的写入能力、更稳定的查询能力、更高的压缩率。GaussDB(for Influx)写入能力在小数据量场景下是开源企业版的13倍,在大数据量场景下是开源企业版的1.8倍;查询能力在两种场景下表现稳定,在大部分查询场景下优于开源企业版;在压缩率方面,同样数据模型下,高出开源版本40%。
除了以上优势外,GaussDB(for Influx)还在集群化、冷热分级存储、高可用方面也做了深度优化,能更好地满足时序应用的各种场景。
5. 结束
本文作者:华为 云数据库创新Lab & 华为云时空数据库团队
更多技术文章,关注GaussDB(for Influx)官方博客:
https://bbs.huaweicloud.com/community/usersnew/id_1586596796288328
Lab官网:https://www.huaweicloud.com/lab/clouddb/home.html
产品首页:https://www.huaweicloud.com/product/gaussdbforinflux.html
欢迎加入我们!
云数据库创新Lab(成都、北京)简历投递邮箱:xiangyu9@huawei.com
华为云时空数据库团队(西安、深圳)简历投递邮箱:yujiandong@huawei.com
GaussDB(for Influx)与开源企业版性能对比的更多相关文章
- 相关 Excel 开源类库性能对比
性能数据 · Excelize 中文文档https://xuri.me/excelize/zh-hans/performance.html Golang library for reading and ...
- 揭秘华为云GaussDB(for Influx)最佳实践:hint查询
摘要:GaussDB(for Influx)通过提供hint功能,在单时间线的查询场景下,性能有大幅度的提升,能有效满足客户某些特定场景的查询需求. 本文分享自华为云社区<华为云GaussDB( ...
- 不同Framework下StringBuilder和String的性能对比,及不同Framework性能比(附Demo)
本文版权归mephisto和博客园共有,欢迎转载,但须保留此段声明,并给出原文链接,谢谢合作. 文章是哥(mephisto)写的,SourceLink 阅读目录 介绍 环境搭建 测试用例 MSDN说明 ...
- iOS中保证线程安全的几种方式与性能对比
来源:景铭巴巴 链接:http://www.jianshu.com/p/938d68ed832c 一.前言 前段时间看了几个开源项目,发现他们保持线程同步的方式各不相同,有@synchronized. ...
- 2017年的golang、python、php、c++、c、java、Nodejs性能对比(golang python php c++ java Nodejs Performance)
2017年的golang.python.php.c++.c.java.Nodejs性能对比 本人在PHP/C++/Go/Py时,突发奇想,想把最近主流的编程语言性能作个简单的比较, 至于怎么比,还是不 ...
- Net Core下多种ORM框架特性及性能对比
在.NET Framework下有许多ORM框架,最著名的无外乎是Entity Framework,它拥有悠久的历史以及便捷的语法,在占有率上一路领先.但随着Dapper的出现,它的地位受到了威胁,本 ...
- Ceph与Gluster之开源存储的对比
一.Ceph与Gluster之开源存储的对比 一.Ceph与Gluster的原理对比 Ceph和Gluster是Red Hat旗下的成熟的开源存储产品,Ceph与Gluster在原理上有着本质上的不同 ...
- MyISAM与InnoDB两者之间区别与选择,详细总结,性能对比
1.MyISAM:默认表类型,它是基于传统的ISAM类型,ISAM是Indexed Sequential Access Method (有索引的顺序访问方法) 的缩写,它是存储记录和文件的标准方法.不 ...
- Elasticsearch的几种架构(ELK,EL,EF)性能对比测试报告
Elasticsearch的几种架构性能对比测试报告 1.前言 选定了Elasticsearch作为存储的数据库,但是还需要对Elasticsearch的基础架构做一定测试,所以,将研究测试报告输出如 ...
- 两大主流开源分布式存储的对比:GlusterFS vs. Ceph
两大主流开源分布式存储的对比:GlusterFS vs. Ceph 存储世界最近发生了很大变化.十年前,光纤通道SAN管理器是企业存储的绝对标准,但现在的存储必须足够敏捷,才能适应在新的基础架构即服务 ...
随机推荐
- Jenkins相关概念
1,Jenkins相关工具概念: 要熟练掌握Jenkins持续集成的配置.使用和管理,需要了解相关的概念.例如代码开发.编译.打包.构建等名称,常见的代码相关概念包括:JDK.JAVA.MAKE.AN ...
- seed 随机种子的作用
在随机数生成中,种子(seed)是一个起始值,用于确定随机数生成器的初始状态.通过设置相同的种子,可以确保每次运行程序时生成的随机数序列都是相同的.这种确定性的随机数生成可以带来以下几个好处: 可复现 ...
- 大一下c语言课程设计
// // main.c // 高级语言课程设计图书管理系统 // // Created by 蔡星旖 on 2022/8/1. // #include <iostream> #inclu ...
- 手撕Vuex-实现mutations方法
经过上一篇章介绍,完成了实现 getters 的功能,那么接下来本篇将会实现 mutations 的功能. 在实现之前我们先来回顾一下 mutations 的使用. 将官方的 Vuex 导入进来,因为 ...
- 51单片机控制w5500实现udp组播通信
51单片机控制w5500实现udp组播通信 在socket打开之前,向Sn_MR (Socket n 模式寄存器)寄存中写入 0x82(1000 0010),将W5500加入组播组 对Sn_DIPR ...
- UML学习入门就这一篇文章(转)
1.1 UML基础知识扫盲 UML这三个字母的全称是Unified Modeling Language,直接翻译就是统一建模语言,简单地说就是一种有特殊用途的语言. 你可能会问:这明明是一种图形,为什 ...
- ReverseMe-120
一道好题,没解出来但是收获很多 贴两位大牛的题解 [精选]攻防世界逆向高手题之ReverseMe-120-CSDN博客 攻防世界ReverseMe-120详解_攻防世界reverseme基本思路-CS ...
- 前端本地导出文件 导出txt sql (简版版的字符串案例)
1.首页明确要导出的根据 一般有图片 excel 文字.针对不同的文件类型 配置不同的参数 2.知识点 Blob URL.createObjectUrl new Blob( arr ...
- JavaScript高级程序设计笔记12 BOM
BOM BOM的核心--window对象 窗口和弹窗 location对象--页面信息 navigator对象--浏览器信息 history对象--浏览器历史记录 BOM是使用JavaScript开发 ...
- C语言计算并输出华氏温度为80F所对应的摄氏温度C。转换公式为:C=5*(F-32)/9
#include <stdio.h> int main() { double F = 80.0, C;//定义摄氏温度变量,赋值华氏温度 C = 5 * (F - 32) / 9.0;// ...