python-去掉写入csv文件的多余的一行空白行
如执行下面的代码:
1 import csv
2
3 if __name__ == "__main__":
4
5 content1 = ['hello']
6 content2 = ['world']
7
8 with open('test.csv', 'w') as f:
9 writer = csv.writer(f)
10 writer.writerow(content1)
11 writer.writerow(content2)
打开test.csv文件查看,如下图:
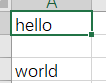
可以看到,多了一行空白行,解决方式如下:
如果使用的python3:
1 import csv
2
3 if __name__ == "__main__":
4
5 content1 = ['hello']
6 content2 = ['world']
7
8 with open('test.csv', 'w', newline='', encoding='utf-8-sig') as f:
9 writer = csv.writer(f)
10 writer.writerow(content1)
11 writer.writerow(content2)
如果使用的python2:
1 import csv
2
3 if __name__ == "__main__":
4
5 content1 = ['hello']
6 content2 = ['world']
7
8 with open('test.csv', 'wb') as f:
9 writer = csv.writer(f)
10 writer.writerow(content1)
11 writer.writerow(content2)
python-去掉写入csv文件的多余的一行空白行的更多相关文章
- python读取和写入csv文件
读取csv文件: def readCsv(): rows=[] with file(r'E:\py\py01\Data\system.csv','rb') as f: reads=csv.reader ...
- Python数据写入csv格式文件
(只是传递,基础知识也是根基) Python读取数据,并存入Excel打开的CSV格式文件内! 这里需要用到bs4,csv,codecs,os模块. 废话不多说,直接写代码!该重要的内容都已经注释了, ...
- 利用Python写入CSV文件的方法
第一种:CSV写入中文 #! /usr/bin/env python # _*_ coding:utf- _*_ import csv csvfile = file('test.csv', 'wb') ...
- python在处理CSV文件时,字符串和列表写入的区别
概述 Python在处理CSV文件时,如果writerow的对象是<type 'unicode'>字符串时,写入到CSV文件时将会出现一个字符占一个单元格的情况: 但是将字符串转换为列表类 ...
- python在不同情况下写入csv文件
情况一(解法一):将列表存储为csv文件.列表的每一项代表csv文件的一行. 列表中的每一项包含多个属性.list=[[属性1,属性2,属性3,……],[属性1,属性2,属性3,……],[属性1,属性 ...
- python写入csv文件时的乱码问题
今天在使用python的csv库将数据写入csv文件时候,出现了中文乱码问题,解决方法是在写入文件前,先指定utf-8编码,如下: import csv import codecs if __name ...
- python之读取和写入csv文件
写入csv文件源码: #输出数据写入CSV文件 import csv data = [ ("Mike", "male", 24), ("Lee&quo ...
- Python爬取酷狗飙升榜前十首(100)首,写入CSV文件
酷狗飙升榜,写入CSV文件 爬取酷狗音乐飙升榜的前十首歌名.歌手.时间,是一个很好的爬取网页内容的例子,对爬虫不熟悉的读者可以根据这个例子熟悉爬虫是如何爬取网页内容的. 需要用到的库:requests ...
- [Python Study Notes]csv文件操作
''''''''''''''''''''''''''''''''''''''''''''''''''''''''''''''''''''''''''''''''''''''''''''''''''' ...
- python爬虫之csv文件
一.二维数据写入csv文件 题目要求: 读入price2016.csv文件,将其中的数据读出,将数字部分计算百分比后输出到price2016out.csv文件中 知识点: 对于列表中存储的二维数据, ...
随机推荐
- 我们为什么需要操作系统(Operating System)?
我们为什么需要操作系统(Operating System)? a) 从计算机体系的角度,OS向下统筹了所有硬件资源(1),向上为所有软件提供API调用(2),使得软件程序员不必知晓硬件的具体细节,实现 ...
- 当服务器间通讯出现No route to host(Host unreachable)
服务器间通讯出现No route to host(Host unreachable) 背景:因为某些原因,主机房服务器集体重启,其中部署的系统也需要重启,负责的系统是五台服务器,两台用来作为应用的应用 ...
- 【Oracle】Oracle数据库,第N大数据取值
Oracle数据库,第N大数据取值 没想到力扣还有数据库的练习,正好本菜鸡跑过来练手 要显示第二大的数据可以使用order by进行排序,然后用limit对显示的数据进行限制,limit1,1,以此来 ...
- word文档怎么让封面没有页码,页码从正文开始(word 2019)
1.打开需要插入页码的文档,光标放在正文处的开头,然后点击word窗口中的 [布局] ---> 选择[分隔符] -->选择 [分节符] 下面的 [连续]; 2.然后选择word功能区 ...
- [ARC174B] Bought Review 题解
[题目描述] 你开了一家店,有 \(A_i\) 个 \(i\) 星级评论,你可以花费 \(P_i\) 元买到一个 \(i\) 星评论,问使得这家店评论的星星平均值不小于 \(3\),最少要花多少钱. ...
- 快速界定故障:Socket Tracer网络监控实践
简介: Socket Tracer定位是传输层(Socket&TCP)的指标采集工具,通过补齐网络监控的这部分盲区,来达到快速界定网络问题的目标. 作者 | 四忌 来源 | 阿里技术公 ...
- EMR on ACK 全新发布,助力企业高效构建大数据平台
简介: 阿里云 EMR on ACK 为用户提供了全新的构建大数据平台的方式,用户可以将开源大数据服务部署在阿里云容器服务(ACK)上.利用 ACK 在服务部署和对高性能可伸缩的容器应用管理的能力优 ...
- Git 工具下载慢问题 & 图像化界面工具
Git 命令行淘宝镜像:git-for-windows Mirror (taobao.org) Git 图形客户端:Download – TortoiseGit – Windows Shell Int ...
- [Blockchain] 开发完真实的 DApp 后才能得出的结论与看法
1. 最近经常看到地方新闻有关 区块链在追踪溯源方面被实际应用,但是我本人认为这很大程度上可能是伪命题. 因为,是不是区块链.或者说有没有办法更改数据,这都很难说,本质上这个链还是由机构控制,所以对此 ...
- Rancher管理K8s集群(14)
一.Rancher介绍 1.1 Rancher简介 Rancher 是一个开源的企业级多集群 Kubernetes 管理平台,实现了 Kubernetes 集群在混合云+本地 数据中心的集中部署与管理 ...