ETL工具-nifi干货系列 第六讲 处理器JoltTransformJSON
1、处理器作用
使用Jolt转换JSON数据为其他结构的JSON,成功的路由到'success',失败的'failure'。处理JSON的实用程序不是基于流的,因此大型JSON文档转换可能会消耗大量内存。
Jolt:JSON 到 JSON 转换库,用 Java 编写,其中转换的 "规范" 或者描述文件本身就是一个 JSON 文档。
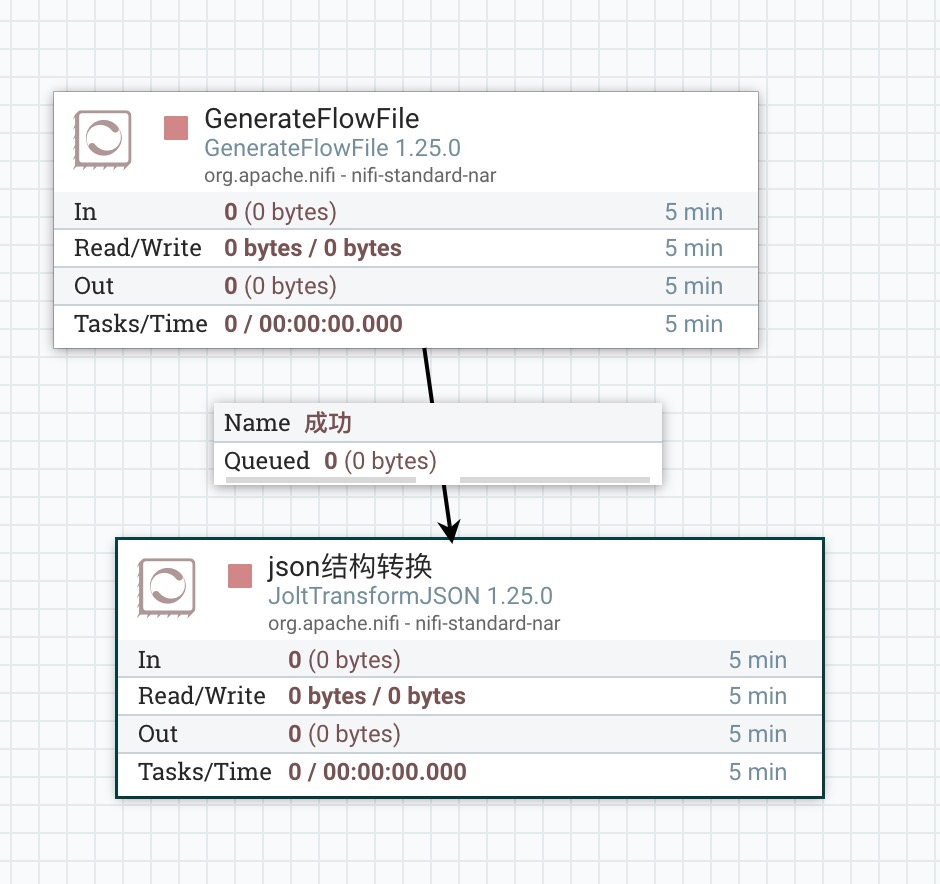
2、属性配置
(Jolt Transformation DSL)指定应该使用哪种Jolt转换模式,目前有如下10种转换模式:
Cardinality:更改了输入JSON数据元素的基数,如json中的string 类型的字段变更为list
Chain:按顺序应用多个转换规则。
Default:如果输入中不存在指定的字段,则添加默认值。
Modify -Default:修改字段的值,如果字段不存在则添加默认值。
Modify - Define:修改字段的值,如果字段不存在则创建该字段并赋值。
Modify - Overwrite:修改字段的值,如果字段不存在则忽略。
Remove:移除指定的字段。
Shift:将字段的值移动到另一个字段下。
Sort:对对象中的字段进行排序。
Custom:自定义转换规则。
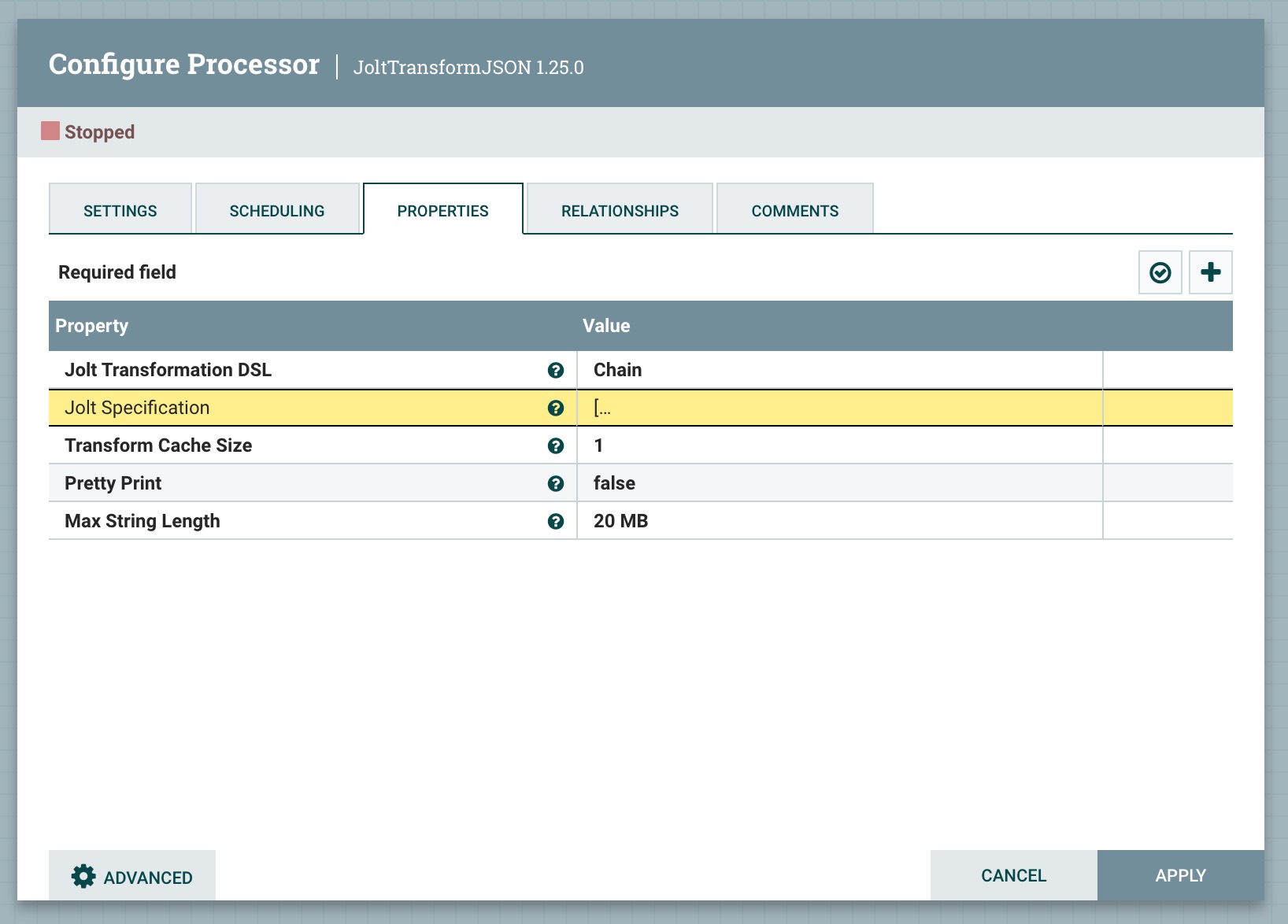
(Jolt Specification)JSON数据转换Spec。如果选择了Sort转换,则忽略此值。
支持表达式语言:true(将使用流文件属性和变量注册表进行计算)
(Transform Cache Size)转换缓存大小:
编译 Jolt 转换可能会相当昂贵。理想情况下,这只会执行一次。然而,如果在转换中使用表达式语言,我们可能需要为每个 FlowFile 使用新的转换。该值控制我们在内存中缓存多少个这些转换,以避免每次都需要编译转换。
(Pretty Print)json是否美化输出
(Max String Length)最大字符串长度
3、示例演示
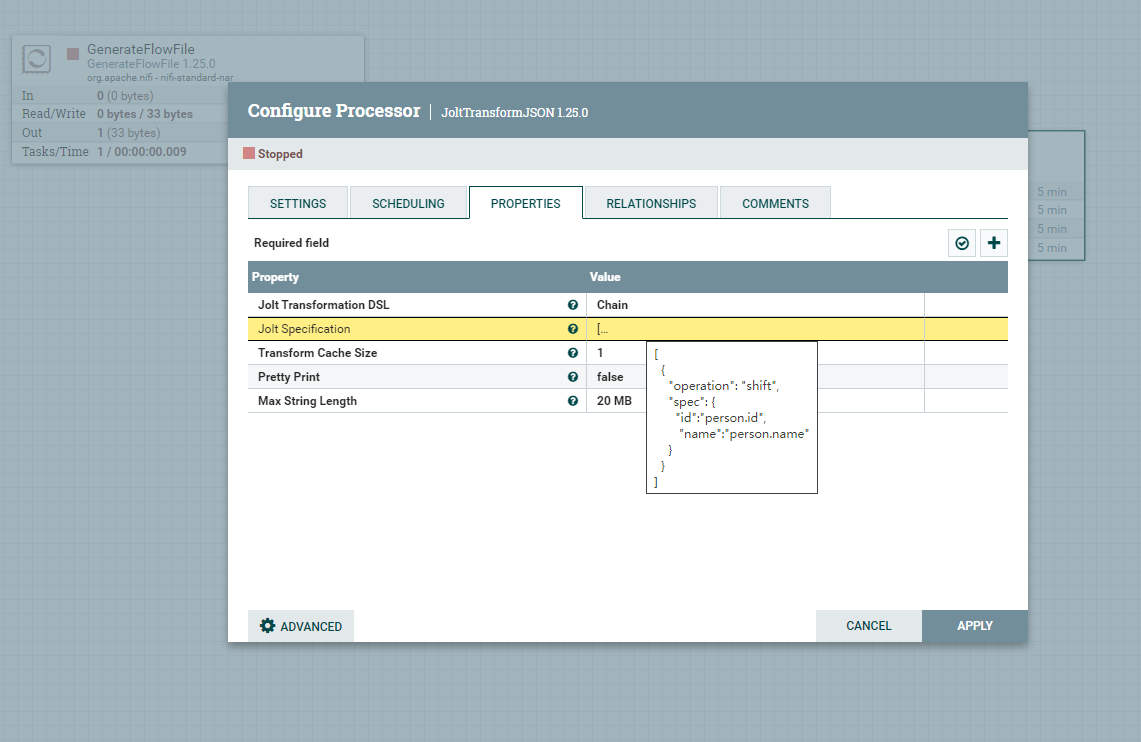
处理器GenerateFlowFile 产生json字符串{"id":"1","name":"Java小金刚"}
Jolt Transformation DSL 设置为chain
Jolt Specification 设置为[{"operation":"shift","spec":{"id":"person.id","name":"person.name"}}]
输出结果如下:
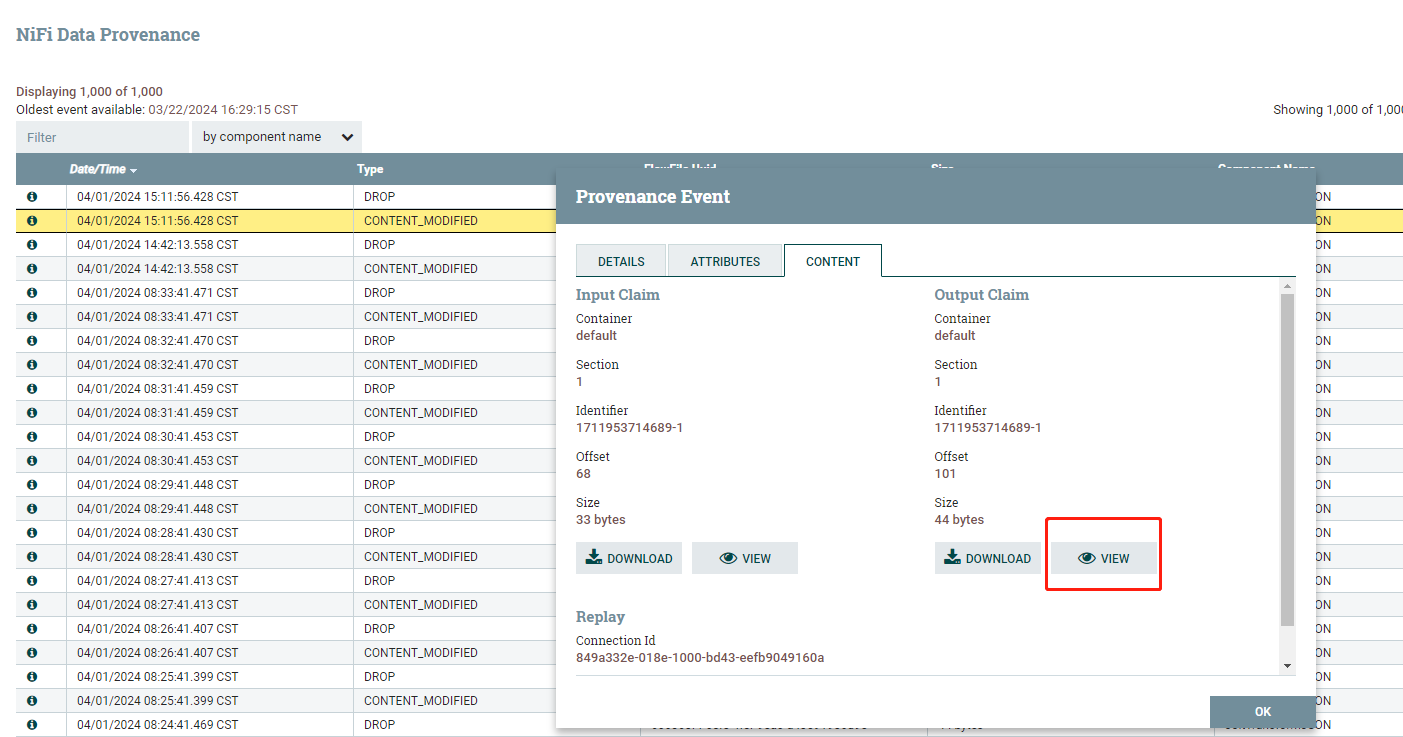
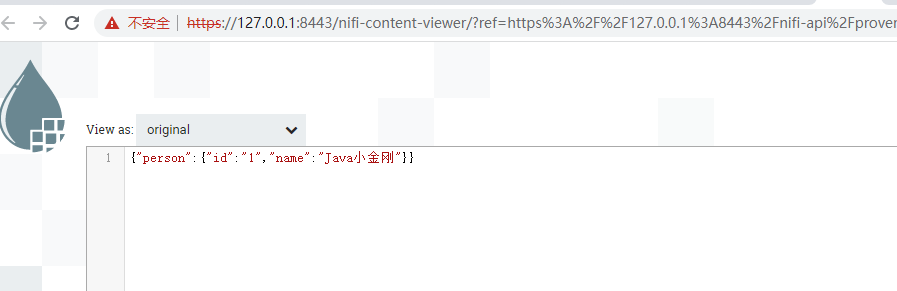

ETL工具-nifi干货系列 第六讲 处理器JoltTransformJSON的更多相关文章
- 开源ETL工具kettle系列之常见问题
开源ETL工具kettle系列之常见问题 摘要:本文主要介绍使用kettle设计一些ETL任务时一些常见问题,这些问题大部分都不在官方FAQ上,你可以在kettle的论坛上找到一些问题的答案 1. J ...
- Spring Boot干货系列:(六)静态资源和拦截器处理
Spring Boot干货系列:(六)静态资源和拦截器处理 原创 2017-04-05 嘟嘟MD 嘟爷java超神学堂 前言 本章我们来介绍下SpringBoot对静态资源的支持以及很重要的一个类We ...
- 数据仓库系列之ETL过程和ETL工具
上周因为在处理很多数据源集成的事情一直没有更新系列文章,在这周后开始规律更新.在维度建模中我们已经了解数据仓库中的维度建模方法以及基本要素,在这篇文章中我们将学习了解数据仓库的ETL过程以及实用的ET ...
- etl学习系列1——etl工具安装
ETL(Extract-Transform-Load的缩写,即数据抽取.转换.装载的过程),对于企业或行业应用来说,我们经常会遇到各种数据的处理,转换,迁移,所以了解并掌握一种etl工具的使用,必不可 ...
- Wix打包系列 (六)制作升级和补丁包
原文:Wix打包系列 (六)制作升级和补丁包 前面我们已经知道怎么制作一个完整安装包了,但我们的软件往往不能一次性就满足客户的需要,当客户需要我们给软件进行升级的时候,我们应该怎么做呢? 在这之前,我 ...
- JVM基础系列第5讲:字节码文件结构
温馨提示:此篇文章长达两万字,图片50多张,内容非常多,建议收藏后再看. 前面我们说到 Java 虚拟机使用字节码实现了跨平台的愿景,无论什么系统,我们都可以使用 Java 虚拟机解释执行字节码文件. ...
- ETL工具的功能和kettle如何来提供这些功能
不多说,直接上干货! 大家会有一个疑惑,本系列博客是Kettle,那怎么扯上ETL呢? Kettle是一款国外开源的ETL工具,纯java编写,可以在Window.Linux.Unix上运行. 说白了 ...
- ETL工具Datax、sqoop、kettle 的区别
一.Sqoop主要特点: 1.可以将关系型数据库中的数据导入到hdfs,hive,hbase等hadoop组件中,也可以将hadoop组件中的数据导入到关系型数据库中: 2.sqoop在导入导出数据时 ...
- CRL快速开发框架系列教程六(分布式缓存解决方案)
本系列目录 CRL快速开发框架系列教程一(Code First数据表不需再关心) CRL快速开发框架系列教程二(基于Lambda表达式查询) CRL快速开发框架系列教程三(更新数据) CRL快速开发框 ...
- 【微信小程序开发•系列文章六】生命周期和路由
这篇文章理论的知识比较多一些,都是个人观点,描述有失妥当的地方希望读者指出. [微信小程序开发•系列文章一]入门 [微信小程序开发•系列文章二]视图层 [微信小程序开发•系列文章三]数据层 [微信小程 ...
随机推荐
- watch对比computed
总结: computed和watch之间的区别: 1.computed能完成的功能,Watch都可以实现 2.watch能完成的功能,comp ...
- 力扣162(java&python)-寻找峰值(中等)
题目: 峰值元素是指其值严格大于左右相邻值的元素. 给你一个整数数组 nums,找到峰值元素并返回其索引.数组可能包含多个峰值,在这种情况下,返回 任何一个峰值 所在位置即可. 你可以假设 nums[ ...
- 力扣696(java)-计数二进制子串(简单)
题目: 给定一个字符串 s,统计并返回具有相同数量 0 和 1 的非空(连续)子字符串的数量,并且这些子字符串中的所有 0 和所有 1 都是成组连续的. 重复出现(不同位置)的子串也要统计它们出现的次 ...
- Serverless 架构下的 AI 应用开发:入门、实战与性能优化
简介: 本章通过对 Serverless 架构概念的探索,对 Serverless 架构的优势与价值.挑战与困境进行分析,以及 Serverless 架构应用场景的分享,为读者介绍 Serverles ...
- MySQL实战—更新过程
和查询流程不同的是,更新流程涉及两个重要的日志模块:redo log(重做日志)和 binlog(二进制日志). redo log redo log通常是物理日志,记录的是数据页的物理修改,而不是某一 ...
- 数据的“敏捷制造”,DataWorks一站式数据开发治理范式演进
简介: 企业大数据技术发展至今,历经了两次蜕变.第一次蜕变从最初的"小作坊"解决大数据问题,到后来企业用各类大数据技术搭建起属于自己的"大平台",通过平台化的能 ...
- 如何使用 Kubernetes 监测定位慢调用
简介:本次课程主要分为三大部分,首先将介绍慢调用的危害以及常见的原因:其次介绍慢调用的分析方法以及最佳实践:最后将通过几个案例来去演示一下慢调用的分析过程. 作者:李煌东 大家好,我是阿里云的李煌东 ...
- 治理企业“数据悬河”,阿里云DataWorks全链路数据治理新品发布
简介: 10月19日,在2021年云栖大会上,阿里云重磅发布DataWorks全链路数据治理产品体系,基于数据仓库,数据湖.湖仓一体等多种大数据架构,DataWorks帮助企业治理内部不断上涨的&q ...
- 运行模型对比 gemma:7b, llama2, mistral, qwen:7b
[gemma:2b] total duration: 1m5.2381509sload duration: 530.9µsprompt eval duration: 110.304msprompt e ...
- dotnet 6 创建进程 Process.Start 时设置 UseShellExecute 在 Windows 下对性能的影响
本文将告诉大家,在 dotnet 6 或 dotnet 7 版本里,启动新的进程时,在 StartInfo 设置 UseShellExecute 为 true 和 false 时,对性能的影响 在 d ...