Stable diffusion采样器详解
在我们使用SD web UI的过程中,有很多采样器可以选择,那么什么是采样器?它们是如何工作的?它们之间有什么区别?你应该使用哪一个?这篇文章将会给你想要的答案。
什么是采样?
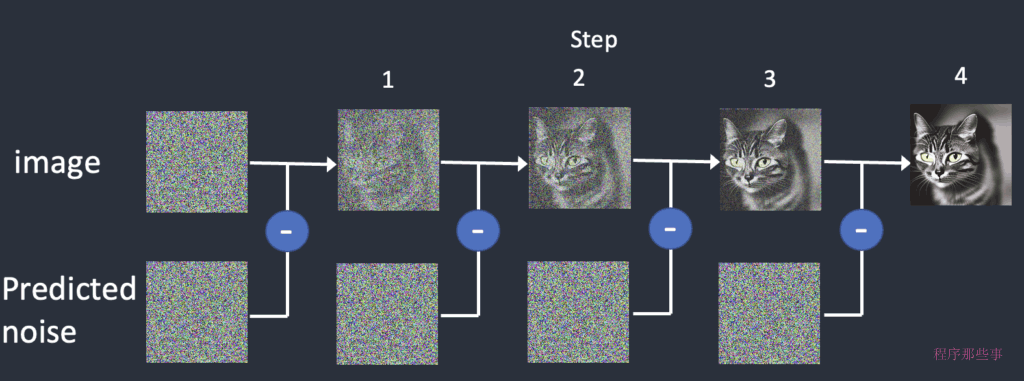
Stable Diffusion模型通过一种称为“去噪”的过程来生成图像,这个过程涉及到在潜在空间中逐步从随机噪声中提取出有意义的图像特征。
- 模型首先在潜在空间中生成一个完全随机的噪声图像。这个图像是随机的,不包含任何有意义的信息。
- 噪声预测器(也称为去噪函数)估计这个随机图像中的噪声。这个预测器是模型的一部分,它学习如何从噪声中恢复出清晰的图像。
- 模型从初始的随机噪声图像中减去预测的噪声,以便逐步揭示出隐藏在噪声下的图像内容。
- 这个过程会重复多次(通常是十几次),每一步都会生成一个新的采样图像。这些采样图像逐渐从随机噪声转变为越来越清晰的图像。
- 经过多次迭代后,最终得到的图像是一个干净的、去噪后的图像,它反映了文本提示中描述的内容。
下面是一个实际的采样过程。采样器逐渐产生越来越干净的图像。

Noise schedule
在Stable Diffusion模型的去噪过程中,噪声表(noise schedule)扮演着至关重要的角色。
噪声表是一个预先定义的计划,它决定了在每一步采样过程中应用的噪声水平。
- 在去噪过程的第一步,图像充满了高噪声,这是因为初始图像是完全随机的噪声图像。在这个阶段,噪声水平最高,图像看起来是不连贯和随机的。
- 随着去噪过程的进行,噪声表会逐步降低每个采样步骤中的噪声水平。这种降低是按照预定的计划进行的,旨在逐渐从噪声中提取出有意义的图像特征。
- 在去噪过程的最后一步,噪声水平降低到零,此时图像应该是清晰且与文本提示相匹配的。理想情况下,最终图像应该几乎没有噪声,且细节丰富,准确地反映了文本描述的内容。
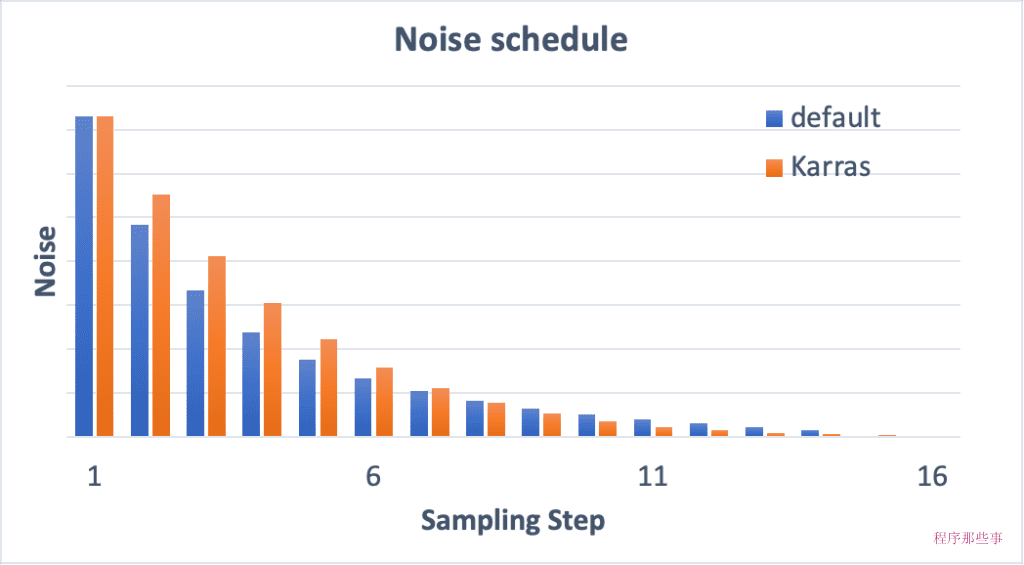
下面是一个Noise schedule的基本工作原理:
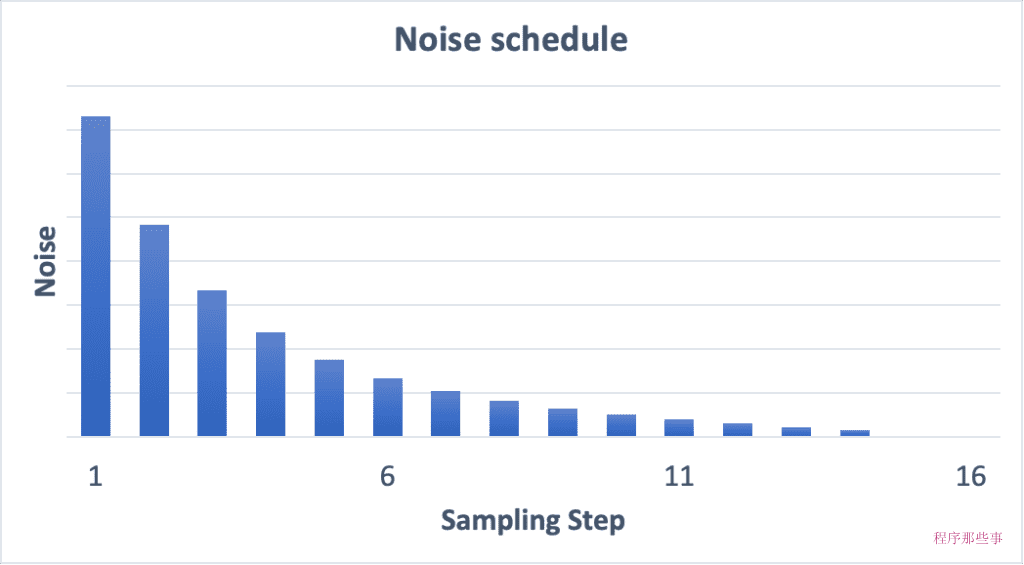
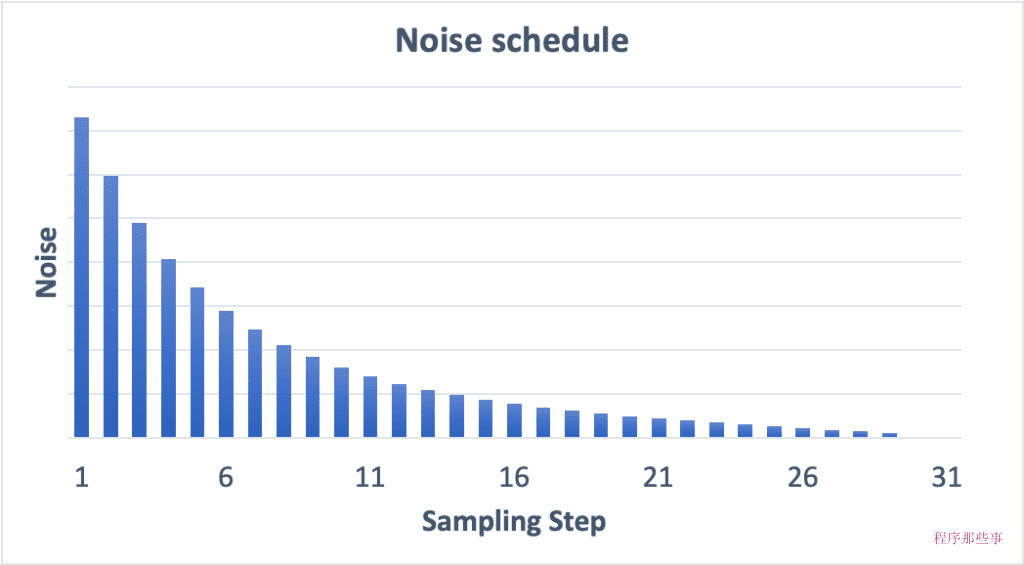
如果我们增加采样步骤数,那么每个步骤之间的降噪幅将会变小。这有助于减少采样的截断误差。
可以比较一下 15 个步骤和 30 个步骤的噪音时间表。
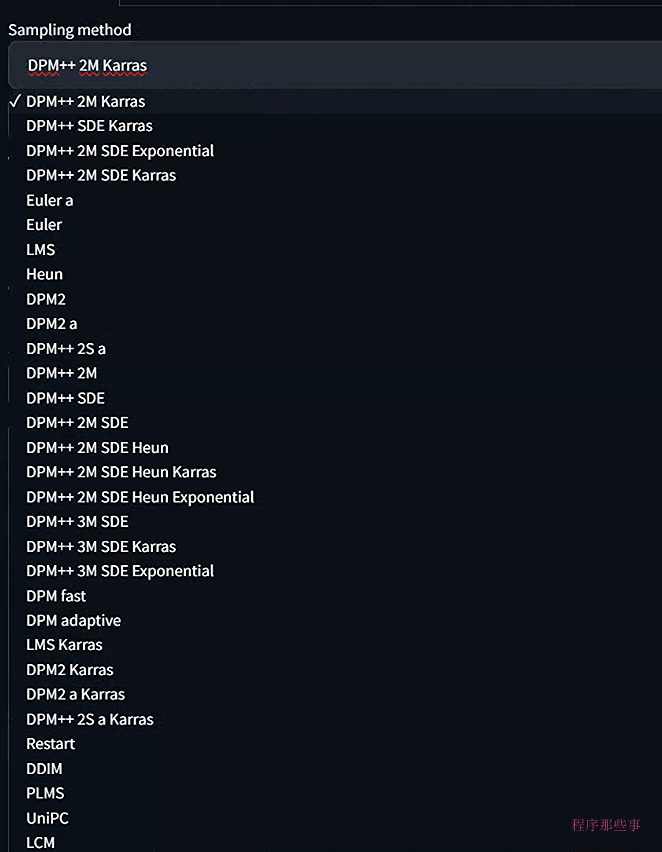
不同的采样器
webUI自带了很多不同的采样器,并且这个采样器的个数还在不停的增加,那么这些采样器都有些什么不同呢?
老式ODE solvers
让我们看一下最简单采样器。这些采样器算法已经被发明很久很久了。它们是常微分方程 (ODE) 的老式采样器。
Euler– 最简单的采样器。
Heun– 更准确但更慢的 Euler 版本。
LMS(线性多步法) – 与 Euler 的速度相同,但(据说)更准确。
Ancestral采样器
如果你注意观察的话,可以看到某些采样器的名称上带有一个字母'a'。 比如:
Euler a
DPM2 a
DPM++ 2S a
DPM++ 2S a Karras
他们是Ancestral采样器。Ancestral采样器在每个采样步骤中都会向图像添加噪声。它们是随机采样器,因为采样结果具有一定的随机性。
当然也有很多随机采样器的名字上是不带a的。
使用Ancestral采样器的缺点是图像不会收敛。也就是说你有可能不会得到相同的结果。
还是刚刚的例子,我们比较一下使用 Euler a 和 Euler 生成的图像。(为了便于对比,我们加入了另外一个收敛的采样器)

可以看到Euler和DMP++ 2M Karras最终生成的图片其实是大致一样的,但是他们两个跟Euler a的结果不太相同。
所以为了可重复性,那就用收敛采样器。如果要生成细微的变化,那么可以考虑使用随机采样器。
Karras noise schedule
带有“Karras”标签的采样器使用 Karras 文章中推荐的 noise schedule。和传统的采样器相比,你会发现噪声步长在接近尾声时变小了。这样的变化据说可以提高图像的质量。
DDIM 和 PLMS
DDIM(去噪扩散隐式模型)和 PLMS(伪线性多步法)是原始 Stable Diffusion v1 附带的采样器。DDIM是首批为扩散模型设计的采样器之一。PLMS 是 DDIM 的更新、更快的替代方案。
这两个采样器已经过时了,我们通常不会使用他们。
DPM 和 DPM++
DPM(扩散概率模型求解器)和 DPM++ 是专为 2022 年发布的扩散模型设计的新采样器。它们表示具有类似体系结构的求解器系列。DPM 和 DPM2 相似,但 DPM2 是二阶的(更准确但更慢)。DPM++ 是对 DPM 的改进。
DPM adaptive是自适应调整步长。所以它可能很慢,并且不能保证在采样步骤数内完成。
UniPC
UniPC(统一预测器校正器)是 2023 年发布的新采样器。受常微分方程求解器中预测变量-校正器方法的启发,它可以在 5-10 个步骤内实现高质量的图像生成。
怎么选择采样器
那么这么多的采样器,我们应该如何选择呢?我想我们可以从采样算法是否收敛,采样的速度和最终生成图片的质量这几个方面来具体考量需要使用什么样的采样器。
是否收敛
首先,对Euler、DDIM、PLMS、LMS Karras 和 Heun这些老式的常微分方程求解器或原始扩散求解器来说,PLMS和LMS Karras收敛效果不佳。Heun收敛得更快。
对于所有的Ancestral采样器来说,都是不收敛的。这些采样器有:Euler a, DPM2 a, DPM++ 2S a, DPM2 a Karras, DPM++ 2S a Karras。
DPM++ SDE 和 DPM++ SDE Karras 与Ancestral采样器存在相同的缺点。它们不仅不会收敛,而且图像也会随着步数的变化而显着波动。
DPM++ 2M 和 DPM++ 2M Karras 表现良好。当步数足够高时,karras变体收敛得更快。
UniPC 收敛速度比 Euler 慢一点,但还不错。
采样速度
下图是使用不同采样器的采样速度:
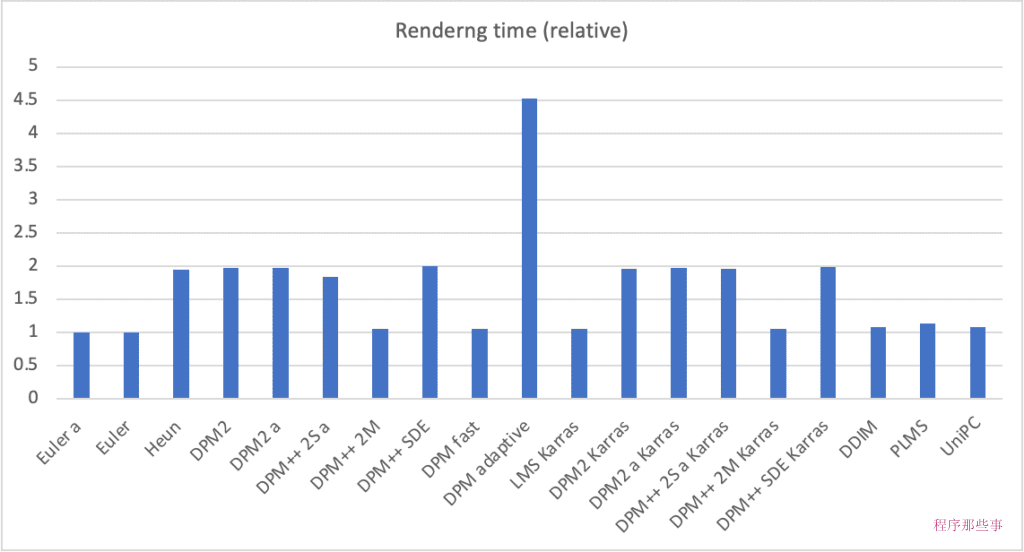
虽然 DPM adaptive在收敛方面表现良好,但它也是最慢的。
其余的渲染时间可以分为两组,第一组花费的时间大致相同(约 1 倍),另一组花费的时间大约是两倍(约 2 倍)。时间花费2倍的是因为他们用的是2阶求解器。
二阶求解器虽然更准确,但需要对去U-Net进行两次评估,所以它们花费的时间大概是2倍。
质量
当然,前面讲的收敛和速度都是次要的,如果最终生成的图片质量不好,那么收敛和速度也就无从谈起了。
我们比较一下常用的一些采样器的最终图片效果:



大家觉得哪幅图更好?事实上,哪幅图更好是一个主观上的标准,每个人的审美观点不同,最后可能选出来不同的结果。
所以......哪一个是最好的?
我不能说哪个是最好的,但是我可以给点我的建议。
如果您想快速、有创造力并且质量不错,那么可以这样选择:
- DPM++ 2M Karras,20-30 步
- UniPC,20-30 步。
如果您想要高质量的图像并且不关心收敛性,那么可以这样选择:
DPM++ SDE Karras,10-15 步(注意:这是一个较慢的采样器)
DDIM,10-15 步。
如果您喜欢稳定、可重现的图像,请避免使用任何Ancestral采样器。
Euler和Heun也是不错的选择.
Stable diffusion采样器详解的更多相关文章
- 详解Linux交互式shell脚本中创建对话框实例教程_linux服务器
本教程我们通过实现来讲讲Linux交互式shell脚本中创建各种各样对话框,对话框在Linux中可以友好的提示操作者,感兴趣的朋友可以参考学习一下. 当你在终端环境下安装新的软件时,你可以经常看到信息 ...
- CentOS Yum 命令详解
总所周知,Redhat和Fedora的软件安装命令是rpm,但是用rpm安 装软件最大的麻烦就是需要手动寻找安装该软件所需要的一系列依赖关系,超级麻烦不说,要是软件不用了需要卸载的话由于卸载掉了某个依 ...
- redis配置详解
##redis配置详解 # Redis configuration file example. # # Note that in order to read the configuration fil ...
- 【大数据】Linux下安装Hadoop(2.7.1)详解及WordCount运行
一.引言 在完成了Storm的环境配置之后,想着鼓捣一下Hadoop的安装,网上面的教程好多,但是没有一个特别切合的,所以在安装的过程中还是遇到了很多的麻烦,并且最后不断的查阅资料,终于解决了问题,感 ...
- 【OpenStack】OpenStack系列4之Glance详解
下载安装 参考:http://www.linuxidc.com/Linux/2012-08/68964.htm http://www.it165.net/os/html/201402/7246.htm ...
- SVN组成中trunk,branches and tags功能用法详解
SVN组成中trunk,branches and tags功能用法详解 我相信初学开发在SVN作为版本管理时,都估计没可能考虑到如何灵活的运用SVN来管理开发代码的版本,下面我就摘录一篇文章来简单说 ...
- [r]Ubuntu Linux系统下apt-get命令详解
Ubuntu Linux系统下apt-get命令详解(via|via) 常用的APT命令参数: apt-cache search package 搜索包 apt-cache show package ...
- Python数据类型及其方法详解
Python数据类型及其方法详解 我们在学习编程语言的时候,都会遇到数据类型,这种看着很基础也不显眼的东西,却是很重要,本文介绍了python的数据类型,并就每种数据类型的方法作出了详细的描述,可供知 ...
- 有了Openvswitch和Docker,终于可以做《TCP/IP详解》的实验了!
所有做过网络编程的程序员,想必都会看<TCP/IP详解>卷一:协议 后来出了第二版,但是由于第一版才是Rechard Stevens的原版,本人还是多次看了第一版. 对这一版印象最深的就是 ...
- kubernetes系列07—Pod控制器详解
本文收录在容器技术学习系列文章总目录 1.Pod控制器 1.1 介绍 Pod控制器是用于实现管理pod的中间层,确保pod资源符合预期的状态,pod的资源出现故障时,会尝试 进行重启,当根据重启策略无 ...
随机推荐
- redis 面试题整理
前言 前天面试了一家公司,平时看一本redis书的也使用redis,对里面的东西也基本了解,结果回答的时候居然回答了只是使用了(因为认为是redis是运维的东西,做的东西多,所以忘了,好吧这是借口), ...
- 力扣554(java&python)-砖墙(中等)
题目: 你的面前有一堵矩形的.由 n 行砖块组成的砖墙.这些砖块高度相同(也就是一个单位高)但是宽度不同.每一行砖块的宽度之和相等. 你现在要画一条 自顶向下 的.穿过 最少 砖块的垂线.如果你画的线 ...
- MaxCompute Spark 使用和常见问题
简介: 本文将就MaxCompute Spark开发环境搭建.常用配置.作业迁移注意事项以及常见问题进行深入介绍. 一. MaxCompute Spark 介绍 MaxCompute Spark是Ma ...
- 基于WASM的无侵入式全链路A/B Test实践
简介: 我们都知道,服务网格(ServiceMesh)可以为运行其上的微服务提供无侵入式的流量治理能力.通过配置VirtualService和DestinationRule,即可实现流量管理.超时重试 ...
- [Linux] 日志管理: 日志轮替 logrotate
日志轮替包含了 "日志切割" 和 "删除旧的保留新的" 功能. 后缀 xx.1 xx.2 这种规则的一般出现的也比较多,目的系统是防止日志被覆盖. 查看详细配置 ...
- [Blockchain] Cosmos Starport 安装的三种方式
官方二进制包方式: # 下载 starport 二进制到 /usr/local/bin $ curl https://get.starport.network/starport! | bash # ...
- [FAQ] wechaty 与 wechaty-puppet-padplus 生态安全吗
答案是肯定有风险. 非技术角度讲,使用这种方式登录微信存在被微信官方风控的可能性,需要特别注意. 另外,以下是 wechaty 项目说明文件中截取的内容: 我们可以看到,除了微信官方方面的风险,我们的 ...
- WPF 优化 EnsureHandle 启动性能
本文将记录一个在 WPF 应用程序启动过程中的性能优化点.如果一个窗口需要设置 WindowStyle 属性,那么在窗口 EnsureHandle 之前,设置 WindowStyle 属性将会比在 E ...
- dotnet 调试应用启动闪退的方法
应用程序如果启动即闪退,那大部分时候日志模块还没初始化完成,很难通过应用自身的启动流程了解到应用启动失败的原因.本文来告诉几个不同的方法用来调查应用启动失败的原因 应用启动失败的原因可能有很多,例如系 ...
- dotnet 启动进程传入不存在的文件夹作为工作目录行为变更
本文记录在 dotnet 下,启动进程,传入不存在的文件夹作为进程的工作目录,分别在 .NET Framework 和 .NET Core 的行为 在 dotnet 6 下,可以使用 ProcessS ...