四、Doris物化视图
使用场景:
在实际的业务场景中,通常存在两种场景并存的分析需求:对固定维度的聚合分析 和 对原始明细数据任意维度的分析。
例如,在销售场景中,每条订单数据包含这几个维度信息(item_id, sold_time, customer_id, price)。在这种场景下,有两种分析需求并存:
- 业务方需要获取某个商品在某天的销售额是多少,那么仅需要在维度(item_id, sold_time)维度上对 price 进行聚合即可。
- 分析某个人在某天对某个商品的购买明细数据。
在现有的 DorisDB 数据模型中:
- 如果仅建立一个聚合模型的表,比如(item_id, sold_time, customer_id, sum(price))。由于聚合损失了数据的部分信息,无法满足用户对明细数据的分析需求。
- 如果仅建立一个 Duplicate 模型,虽可以满足任意维度的分析需求,但由于不支持 Rollup, 分析性能不佳,无法快速完成分析。
- 如果同时建立一个聚合模型和一个 Duplicate 模型,虽可以满足性能和任意维度分析,但两表之间本身无关联,需要业务方自行选择分析表。不灵活也不易用。
MVs使用
物化视图的出现主要是为了满足用户,既能对原始明细数据的任意维度分析,也能快速的对固定维度进行分析查询的需求。

从定义上来说,MVs就是包含了查询结果的数据库对象,可能是对远程数据的本地Copy;也可能是聚合后的结果。说白了,就是预先存储查询结果的一种数据库对象。
在Doris中的物化视图,就是查询结果预先存储起来的特殊的表。它的优势在于:
- 对于那些经常重复使用相同的子查询结果的查询性能大幅提升
- Doris自动更新物化视图的数据,保证Base 表和物化视图表的数据一致性。无需额外的维护成本
说明注意:
- 物化视图的创建当前为异步操作。创建物化视图的语法会立即返回结果,但物化视图的生成操作可能仍在运行。
- base表中的分区列,必须存在于创建物化视图的group by聚合列中
- 目前只支持对单表进行构建物化视图,不支持多表JOIN ?
- 聚合类型表(Aggregation),不支持对key列执行聚合算子操作,仅支持对value列进行聚合,且聚合算子类型不能改变。
- 物化视图中至少包含一个KEY列
- 不支持指定物化视图查询 ?
创建物化视图

首先你需要有一个Base表,基于这个Base表的数据提交一个创建物化视图的任务,任务中定义好物化视图如何构建。 然后Doris就会异步的执行创建物化视图的任务了。
如上图以一个销售记录表为例:比如我们有一张销售记录明细表,存储了每个销售记录的id,销售员,售卖时间,和金额。 提交完创建物化视图的任务后,Doris就会异步在后台生成物化视图的数据,构建物化视图。在构建期间,用户依然可以正常的查询和导入新的数据。创建任务会自动处理当前的存量数据和所有新到达的增量数据,从而保持和Base表的数据一致性。 用户无需担心一致性问题 。
Flag :
- 如上图:创建表时不指定模型类型时,默认的是按什么类型的模型创建?
- 物化视图支持增量更新,但明细的订单存在多次更新的场景,所以应该建立单一主键模型,搞不定聚合数据的正确性?
查询
物化视图创建完成后,用户的查询会根据规则自动匹配到最优的物化视图。
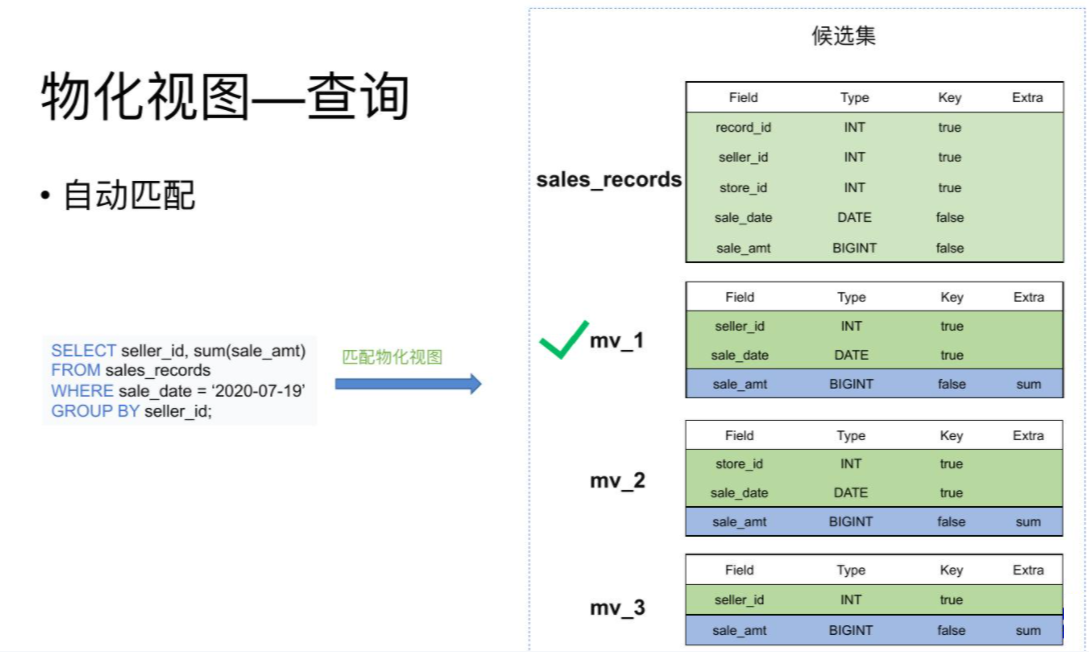
如上图:有一张销售记录明细表,并且在这个明细表上创建了三张物化视图。一个存储了不同时间不同销售员的售卖量,一个存储了不同时间不同门店的销售量,以及每个销售员的总销售量。 当查询7月19日各个销售员都买了多少钱时,我们 可以匹配mv_1物化视图, 直接对mv_1的数据进行查询。
自动匹配过程

自动匹配的过程分为两个步骤:
- 对候选集合进行一个过滤。只要是查询的结果能从物化视图数据计算(取部分行,部分列,或部分行列的聚合)出都可以留在候选集中,过滤完成后候选集合大小 >= 1
- 从候选集合中根据聚合程度,索引等条件选出一个最优的也就是查询花费最少物化视图。
过滤候选集执行过程
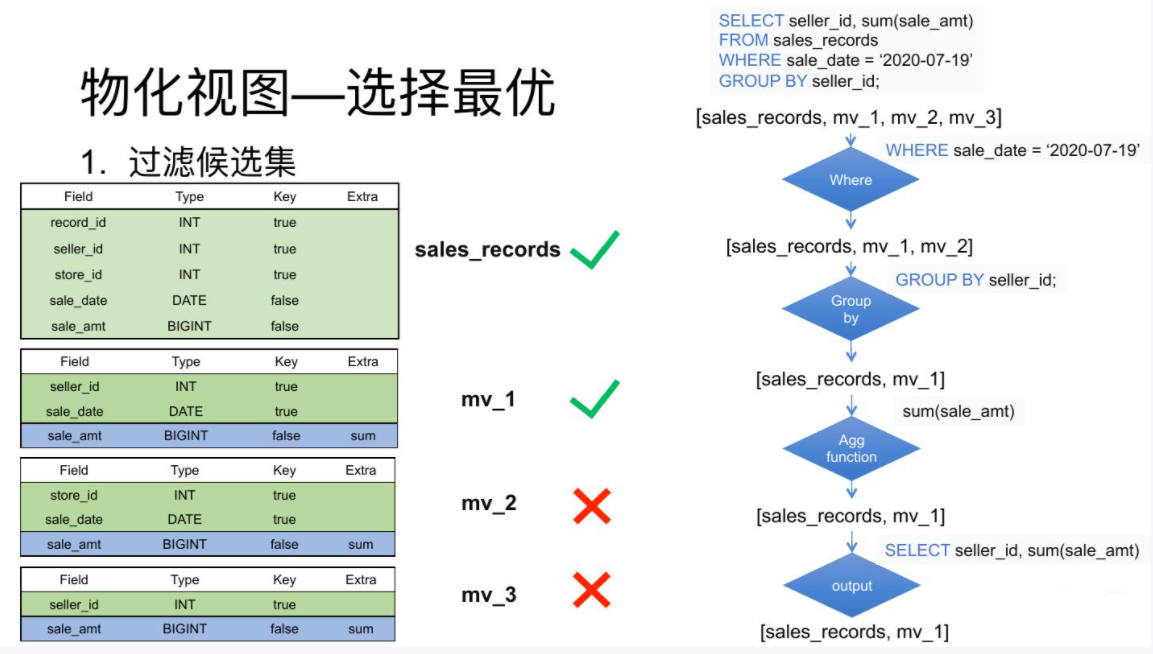
候选集过滤目前分为4层,每一层过滤后去除不满足条件的物化视图。(例如: 查询7月19日各个销售员都买了多少钱为例)
- 首先一开始候选集中包括所有的物化视图以及Base表共4个。
- 第一层 过滤先判断查询Where中的谓词涉及到的数据是否能从物化视图中得到,也就是销售时间列是否在表中存在。由于第三个物化视图中根本不存在销售时间列。所以在这一层过滤中,mv_3就被淘汰了。
- 第二层是过滤查询的分组列是否为候选集的分组列的子集,也就是 销售员id 是否为表中分组列的子集。由于第二个物化视图中的分组列并不涉及 销售员id 。所以在这一层过滤中,mv_2也被淘汰了。
- 第三层 过滤是看查询的聚合列是否为候选集中聚合列的子集,也就是对销售额求和是否能从候选集的表中聚合得出。这里Base表和物化视图表均满足标准。
- 最后一层 是过滤看查询需要的列是否存在于候选集合的列中。由于候选集合中的表均满足标准,所以最终候选集合中的表为 销售明细表 ,以及 mv_1 这两张。
选择最优
候选集过滤完后输出一个集合,这个集合中的所有表都能满足查询的需求,但每张表的查询效率都不同。
这时候就需要在这个集合根据前缀索引是否能匹配到,以及聚合程度的高低来选出一个最优的物化视图。
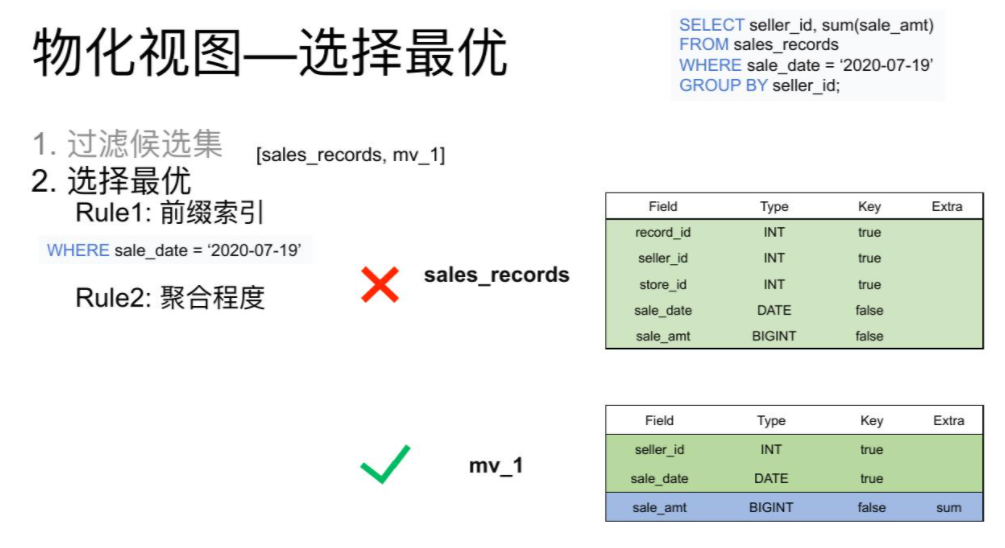
例如: 从 表结构中可以看出,Base表的销售日期列是一个非排序列,而物化视图表的日期是一个排序列,同时聚合程度上mv_1表明显比Base表高,所以最后选择出mv_1作为该查询的最优匹配。
查询改写
最后再根据选择出的最优解,改写查询
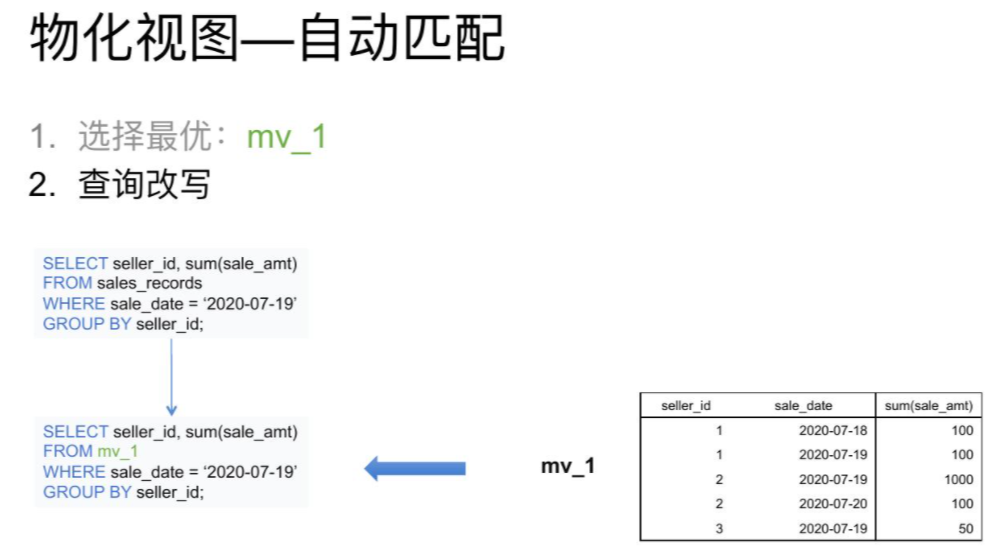
例如: 刚才的查询选中mv_1后,将查询改写为从mv_1中读取数据,过滤出日志为7月19日的mv_1中的数据然后返回即可。
特殊改写
有些情况下的查询改写还会涉及到查询中的聚合函数的改写。 比如业务方经常会用到Count、Distinct对PV、UV进行计算。

例如上图: 广告点 击明细记录表中存放 哪个用户点击了什么广告,从什么渠道点击的,以及点击的时间。 并且在这个Base表基础上构建了一个物化视图表,存储了不同广告不同渠道的用户Bitmap值。
由于bitmap_union这种聚合方式本身会对相同的用户 user_id 进行一个去重聚合。当用户查询广告在Web端的UV的时候,就可以匹配到这个物化视图。 匹配到这个物化视图表后就需要对查询进行改写,将之前的对用户id求 count(distinct) 改为对物化视图中bitmap_union列求count。
所以最后查询取物化视图的第一和第三行求B itmap聚合中有几个值。
物化视图聚合函数

未包含及部分函数解释
- PERCENTILE_APPROX: 统计学中常用的分位数函数
- HLL_UNION: 适用于快速进行非精确去重计算。对明细数据使用HLL_UNION聚合,需要先调用hll_hash函数,对原数据进行转换
查看物化视图:
1、查看该database下的所有物化视图
- SHOW MATERIALIZED VIEW [IN|FROM db_name]
2、查看指定物化视图的表结构
- DESC table_name all
3、查看物化视图处理进度
- SHOW ALTER MATERIALIZED VIEW FROM db_name
4、取消正在创建的物化视图
- CANCEL ALTER MATERIALIZED VIEW FROM db_name.table_name
5、如何确定查询命中了哪个物化视图
参考资料
- https://www.kancloud.cn/dorisdb/dorisdb/2142137
- https://www.slidestalk.com/DolphinScheduler/Doris_Core_Features_Introduction_Pre_Aggregated_Engine_and_Materialized_View
- https://ai.baidu.com/forum/topic/show/987485
四、Doris物化视图的更多相关文章
- Oracle之物化视图
来源于:http://www.cnblogs.com/Ronger/archive/2012/03/28/2420962.html 近期根据项目业务需要对oracle的物化视图有所接触,在网上搜寻关于 ...
- 《oracle每天一练》Oracle之物化视图
相关帖子思考和跟踪 本文转自Ronger 物化视图是一种特殊的物理表,“物化”(Materialized)视图是相对普通视图而言的.普通视图是虚拟表,应用的局限性大,任何对视图的查询,Oracle都实 ...
- oracle物化视图
物化视图是一种特殊的物理表,“物化”(Materialized)视图是相对普通视图而言的.普通视图是虚拟表,应用的局限性大,任何对视图的查询,Oracle都实际上转换为视图SQL语句的查询. 这样对整 ...
- Oracle数据库入门——物化视图日志结构
物化视图的快速刷新要求基本必须建立物化视图日志,这篇文章简单描述一下物化视图日志中各个字段的含义和用途. 物化视图日志的名称为MLOG$_后面跟基表的名称,如果表名的长度超过20位,则只取前20位,当 ...
- Oracle数据库入门——物化视图语法
一.Oracle物化视图语法 create materialized view [view_name]refresh [fast|complete|force][on [commit|demand] ...
- 【转】Oracle之物化视图
原文地址:http://www.cnblogs.com/Ronger/archive/2012/03/28/2420962.html 物化视图是一种特殊的物理表,“物化”(Materialized)视 ...
- 转: Oracle中的物化视图
物化视图创建语法:CREATE MATERIALIZED VIEW <schema.name>PCTFREE <integer>--存储参数PCTUSED <intege ...
- [terry笔记]物化视图 materialized view基础学习
一.物化视图定义摘录: 物化视图是包括一个查询结果的数据库对像(由系统实现定期刷新数据),物化视图不是在使用时才读取,而是预先计算并保存表连接或聚集等耗时较多的操作结果,这样在查询时大大提高了 ...
- oracle 物化视图及创建索引
物化视图是一种特殊的物理表,“物化”(Materialized)视图是相对普通视图而言的.普通视图是虚拟表,应用的局限性大,任何对视图的查询,Oracle都实际上转换为视图SQL语句的查询.这样对整体 ...
- .Net程序员学用Oracle系列(23):视图理论、物化视图
1.视图理论 1.1.视图的存储 1.2.视图的作用 1.3.视图的工作机制 1.4.视图的依赖性 1.5.可更新的连接视图 1.6.内联视图 2.物化视图 2.1.刷新物化视图 2.2.物化视图日志 ...
随机推荐
- KingbaseES 避免表的重写与数据类型二进制兼容
一.关于KingbaseES变更表结构表的重写: 1.修改表结构可能会导致表进行重写(表OID发生变化). 2.修改表结构带有索引或者字段类型长度或者精度操作时,会触发索引重建. 3.不修改列内容且旧 ...
- 如何拿到接口返回的消耗token
SemanticKernel 以下引用自官方案例 Text模型 使用Kernel FunctionResult functionResult = await kernel.InvokePromptAs ...
- #01背包#洛谷 2340 [USACO03FALL]Cow Exhibition G
题目 有\(n\)个物品,对于第\(i\)个物品, 有两种属性,第一种属性为\(x_i\),第二种属性为\(y_i\) 问选择若干个物品使得\(\sum{x_j}\geq 0\)且\(\sum{y_j ...
- 【直播回顾】OpenHarmony知识赋能五期第六课——子系统相机解读
5月26日晚上19点,知识赋能第五期第六节课 <OpenHarmony标准系统多媒体子系统之相机解读> ,在OpenHarmony开发者成长计划社群内成功举行. 本期课程,由深开鸿资 ...
- 掌握 C# 变量:在代码中声明、初始化和使用不同类型的综合指南
C# 变量 变量是用于存储数据值的容器. 在 C# 中,有不同类型的变量(用不同的关键字定义),例如: int - 存储整数(没有小数点的整数),如 123 或 -123 double - 存储浮点数 ...
- C#中base关键字的几种用法 (base可以对派生类(子类)实例中调用基类(父类)的构造函数方法或者基类上已经被重写的虚方法)
base最大的使用就是"面向对象"开发的多态中.base可以对派生类(子类)实例中调用基类(父类)的构造函数方法或者基类上已经被重写的虚方法. 首先声明两个类 A B public ...
- HarmonyOS Connect “Device Partner”专场FAQ来啦!
原文链接:https://mp.weixin.qq.com/s/mQJlAso293qgPlA1paxv5g,点击链接查看更多技术内容: Device Partner平台是面向AIoT产业链 ...
- .NET Emit 入门教程:第六部分:IL 指令:7:详解 ILGenerator 指令方法:分支条件指令
前言: 经过前面几篇的学习,我们了解到指令的大概分类,如: 参数加载指令,该加载指令以 Ld 开头,将参数加载到栈中,以便于后续执行操作命令. 参数存储指令,其指令以 St 开头,将栈中的数据,存储到 ...
- ASP.NET 部署常见问题及解决方案
ASP.NET 部署部署过程中常见问题及解决方案 Could not load file or assembly 'XXXXX' or one of its dependencies. Access ...
- UML 哲学之道——类图[三]
前言 简单整理一些uml中的类图. 正文 类的基本表示法: 名称.属性(类型.可见性).方法(参数.返回值.可见性) 想上面这样,第一行是名称,第二行是属性,第三行是方法 可见性: 表示public ...