字节跳动基于ClickHouse优化实践之“高可用”
更多技术交流、求职机会,欢迎关注字节跳动数据平台微信公众号,回复【1】进入官方交流群
相信大家都对大名鼎鼎的ClickHouse有一定的了解了,它强大的数据分析性能让人印象深刻。但在字节大量生产使用中,发现了ClickHouse依然存在了一定的限制。本篇将详细介绍我们是如何为ClickHouse增强高可用能力的。
字节遇到的ClickHouse可用性问题
随着字节业务的快速发展,产品快速扩张,承载业务的ClickHouse集群节点数也快速增加。另一方面,按照天进行的数据分区也快速增加,一个集群管理的库表特别多,开始出现元数据不一致的情况。两方面结合,导致集群的可用性极速下降,以至于到了业务难以接受的程度。直观的问题有三类:
1、故障变多
典型的例子如硬件故障,几乎每天都会出现。另外,当集群达到一定的规模,Zookeeper会成为瓶颈,增加故障发生频率。
2、故障恢复时间长
因为数据分区变多,导致一旦发生故障,恢复时间经常会需要1个小时以上,这是业务方完全不能接受的。
3、运维复杂度提升
以往只需要一个人负责运维的集群,由于节点增加和分区变多,运维复杂度和难度成倍的增加,目前运维人数增加了几人也依然拙荆见肘,依然难保证集群的稳定运行。
可用性问题已经成为制约业务发展的重要问题,因此我们决定将影响高可用的问题一一拆解,并逐个解决。
提升高可用能力的方案
一、降低Zookeeper压力
问题所在:
原生ClickHouse 使用 ReplicatedMergeTree 引擎来实现数据同步。原理上,ReplicatedMergeTree 基于 ZooKeeper 完成多副本的选主、数据同步、故障恢复等功能。由于 ReplicatedMergeTree 对 ZooKeeper 的使用比较重,除了每组副本一些表级别的元信息,还存储了逻辑日志、part 信息等潜在数量级较大的信息。Zookeeper并不是一个能做到良好线性扩展的系统,当ZooKeeper 在相对较高的负载情况下运行时,往往性能表现并不佳,甚至会出现副本无法写入,数据也无法同步的情况。在字节内部实际使用和运维 ClickHouse 的过程中,ZooKeeper 也是非常容易成为一个瓶颈的组件。
改造思路:
ReplicatedMergeTree 支持 insert_quorum,insert_quorum 是指如果副本数为3,insert_quorum=2,要成功写入至少两个副本才会返回写入成功。
新分区在副本之间复制的流程如下:
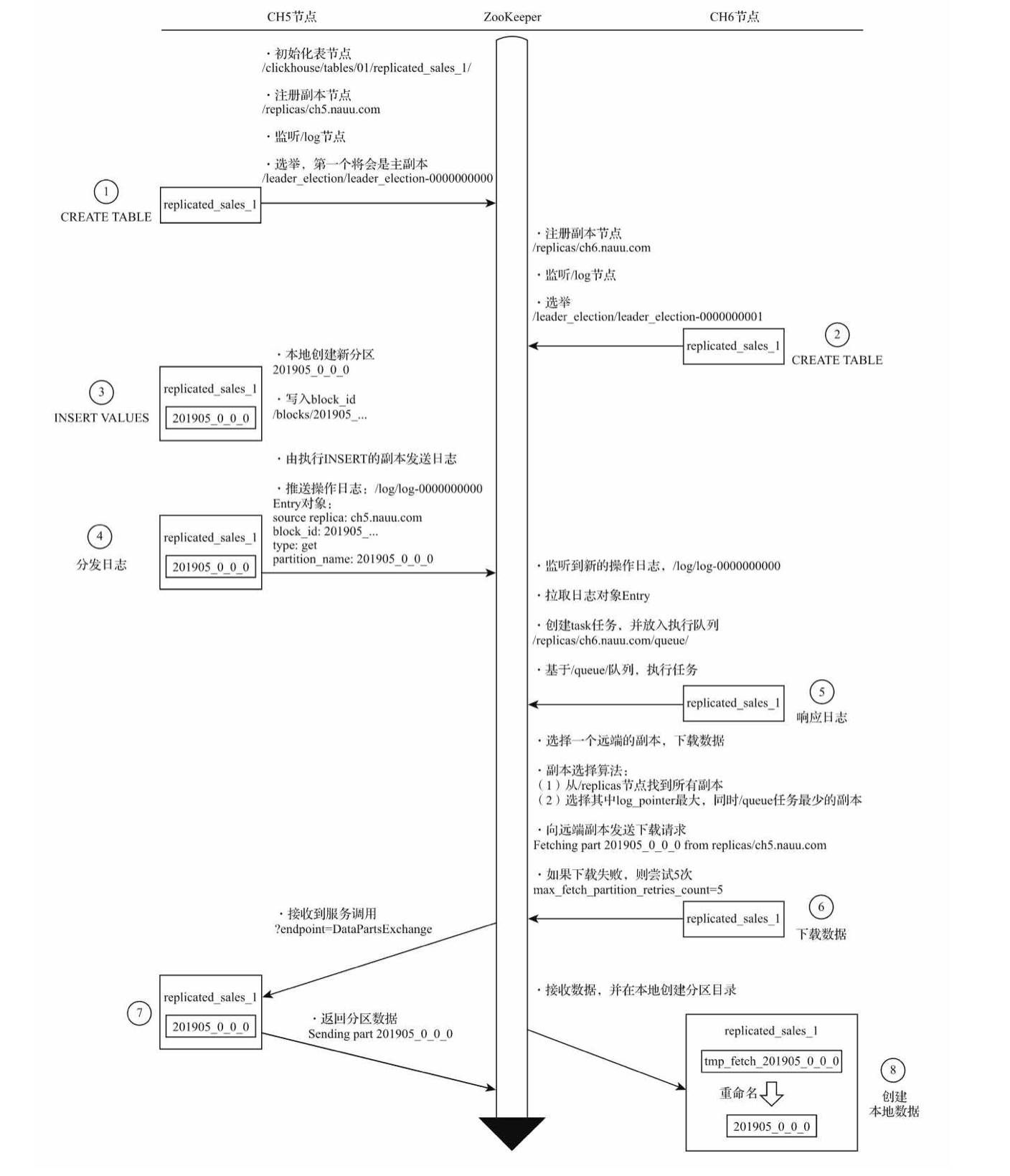
可以看到,反复在 zookeeper 中进行分发日志、数据交换等步骤,这正是引起瓶颈的原因之一。
为了降低对 ZooKeeper 的负载,在ByteHouse中重新实现了一套 HaMergeTree 引擎。通过HaMergeTree降低对 ZooKeeper 的请求次数,减少在 ZooKeeper 上存储的数据量,新的 HaMergeTree 同步引擎:
1)保留ZooKeeper上表级别的元信息;
2)简化逻辑日志的分配;
3)将 part 信息从 ZooKeeper 日志移除。
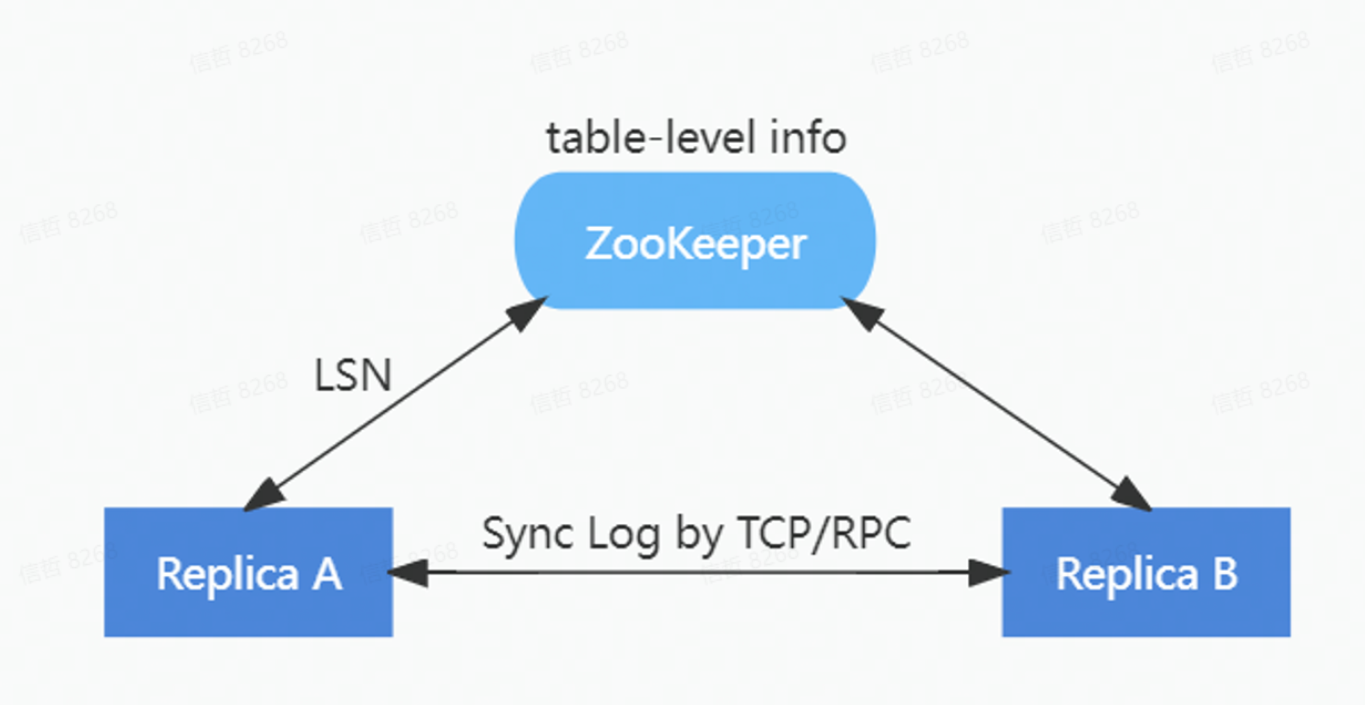
HaMergeTree 减少了操作日志等信息在zookeeper里面的存放,来减少zookeeper的负载,zookeeper里面只是存放log LSN, 具体日志在副本之间通过gossip协议同步回放。
在保持和ReplicatedMergeTree完全兼容的前提下,新的 HaMergeTree 极大减轻了对 ZooKeeper 的负载,实现了 ZooKeeper 集群的压力与数据量不相关。上线后,因Zookeeper导致的异常大量减少。无论是单集群几百甚至上千节点,还是单节点上万张表,都能保障良好的稳定性。
二、提升故障恢复能力
问题所在:
虽然所有数据从业者都在做各种努力,想要保证线上生产环境不出故障,但是现实中还是难以避免会遇到各式各样的问题。主要是由下面这几种因素引起的:
软件缺陷:软件设计本身的Bug引起的系统非正常终止,或依赖的组件兼容引发的问题。
硬件故障:常见的有磁盘损坏、内容故障、CPU故障等,当集群规模扩大后发生的频率也线性增加。
内存溢出导致进程被停止:在OLAP数据库中经常发生。
意外因素:如断电、误操作等引发的问题。
由于原生ClickHouse希望达到极致性能的初衷,所以在ClickHouse系统中元数据常驻于内存中,这导致了ClickHouse server重启时间非常长。因而当故障发生后,恢复的时间也很长,动辄一到两个小时,相当于业务也要中断一到两个小时。当故障频繁出现,造成的业务损失是无法估量的。
改造思路:
为了解决上述问题,在ByteHouse中采用了元数据持久化的方案,将元数据持久化到RocksDB, Server启动时直接从RocksDB加载元数据,内存中也仅仅存放必要的Part信息。因此可以减少元数据对内存的占用,以及加速集群的启动以及故障恢复时间。
如下图所示,元数据持久化整体上采用了RocksDB+Meta in Memory的方式,每个Table都会对应一个RocksDB数据库存放该表所有Part的元信息。Table首次启动时,从文件系统中加载的Part元数据将被持久化到RocksDB中;之后重启时就可以直接从RocksDB中加载Part。每个表从RocksDB或者文件系统加载的Part将只在内存中存放必要的Part信息。在实际使用Part时,将通过内存中存放的Part元信息去RocksDB中读取并加载对应Part。
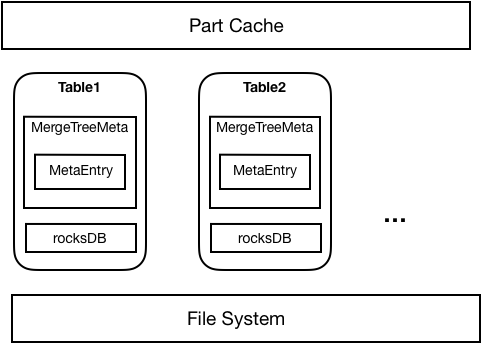
完成元数据持久化后,在性能基本无损失的情况下,单机支持的part不再受内存容量的限制,可以达到100万以上。最重要的是,故障恢复的时间显著缩短,只需要此前的几十分之一的时间就可以完成。例如在原生ClickHouse中需要一到两个小时的恢复时间,在ByteHouse中只需要3分钟,大大提高的系统的高可用能力,为业务提供了坚实保障。
三、其他方面
除了以上两点,在ByteHouse中在其他很多方面都为高可用能力做了增强,如通过HaKafka引擎提升了数据写入的高可用性,提升实时数据写入的容错率,可自动切换主备写入;增加了监控运维平台,实现对关键指标的监控、告警;增加多种问题诊断工具,能实现故障的快速定位。
对于数据分析平台来说,稳定性是重中之重。我们对ByteHouse的高可用能力的提升是不会停止的,在极致性能的背后,力图为用户提供最强有力的稳定性保障。
立即跳转火山引擎ByteHouse官网了解详情
字节跳动基于ClickHouse优化实践之“高可用”的更多相关文章
- 字节跳动基于ClickHouse优化实践之“多表关联查询”
更多技术交流.求职机会.试用福利,欢迎关注字节跳动数据平台微信公众号,回复[1]进入官方交流群 相信大家都对大名鼎鼎的ClickHouse有一定的了解了,它强大的数据分析性能让人印象深刻.但在字节大量 ...
- 字节跳动基于Apache Hudi构建EB级数据湖实践
来自字节跳动的管梓越同学一篇关于Apache Hudi在字节跳动推荐系统中EB级数据量实践的分享. 接下来将分为场景需求.设计选型.功能支持.性能调优.未来展望五部分介绍Hudi在字节跳动推荐系统中的 ...
- 实现基于Haproxy+Keepalived负载均衡高可用架构
1.项目介绍: 上上期我们实现了keepalived主从高可用集群网站架构,随着公司业务的发展,公司负载均衡服务已经实现四层负载均衡,但业务的复杂程度提升,公司要求把mobile手机站点作为单独的服务 ...
- (转)基于keepalived搭建MySQL的高可用集群
基于keepalived搭建MySQL的高可用集群 原文:http://www.cnblogs.com/ivictor/p/5522383.html MySQL的高可用方案一般有如下几种: keep ...
- 亚马逊AWS在线系列讲座——基于AWS云平台的高可用应用设计
设计高可用的应用是架构师的一个重要目标,可是基于云计算平台设计高可用应用与基于传统平台的设计有很多不同.云计算在给架构师带来了很多新的设计挑战的时候,也给带来了很多新的设计理念和可用的服务.怎样在设计 ...
- 轻松构建基于 Serverless 架构的弹性高可用音视频处理系统
前言 随着计算机技术和 Internet 的日新月异,视频点播技术因其良好的人机交互性和流媒体传输技术倍受教育.娱乐等行业青睐,而在当前, 云计算平台厂商的产品线不断成熟完善, 如果想要搭建视频点播类 ...
- 基于keepalived搭建MySQL的高可用集群
MySQL的高可用方案一般有如下几种: keepalived+双主,MHA,MMM,Heartbeat+DRBD,PXC,Galera Cluster 比较常用的是keepalived+双主,MHA和 ...
- 基于Harbor和CephFS搭建高可用Private Registry
我们有给客户搭建私有容器仓库的需求.开源的私有容器registry可供选择的不多,除了docker官方的distribution之外,比较知名的是VMware China出品的Harbor,我们选择了 ...
- 基于 Azure 托管磁盘配置高可用共享文件系统
背景介绍 在当下,共享这个概念融入到了人们的生活中,共享单车,共享宝马,共享床铺等等.其实在 IT 界,共享这个概念很早就出现了,通过 SMB 协议的 Windows 共享目录,NFS 协议的网络文件 ...
- 基于keepalived对redis做高可用配置---转载
关于keepalived的详细介绍,请移步本人相关博客:http://wangfeng7399.blog.51cto.com/3518031/1405785 功能 ip地址 安装软件 主redis 1 ...
随机推荐
- nginx、rabbitmq、redis、zookeeper、zkui安装脚本
nginx安装脚本 #!/bin/bash yum install -y wget pcre-devel openssl openssl-devel gcc ###安装perl### cd /usr/ ...
- ChatGPT提示词迭代
openAI CEO 除了上一篇讲的:限定,排除,示例,生成,扩展了其他方法,包括:关键词.调教和其他使用方法 关键词 像应用搜索引擎一样,在描述的句子开头给一些关键词,比如: 问题 代码 解释 分析 ...
- [转]深入HBase架构解析
HBase架构讲解非常清晰的一篇文章,转自 http://www.blogjava.net/DLevin/archive/2015/08/22/426877.htmlhttp://www.blogja ...
- Codeforces Round #702 (Div. 3) 题解
写在前边 链接:Codeforces Round #702 (Div. 3) 比较简单,但是总是感觉脑子有点转不过弯来. A. Dense Array 链接:A题链接 题目大意: 在数组中插入若干个数 ...
- 微信小程序敏感内容检测
获取access_token access_token是公众号的全局唯一接口调用凭据,公众号调用各接口时都需使用access_token.开发者需要进行妥善保存.access_token的存储至少要保 ...
- Rong晔大佬教程学习(2):取指
1.rvseed_defines.v(定义了一些参数,没有实际意义) 该文件定义了一些基本参数,在后续的代码中都会调用该文件 // simulation clock period `define SI ...
- SpringBoot-Validate优雅的实现参数校验,详细示例~
1.是什么? 它简化了 Java Bean Validation 的集成.Java Bean Validation 通过 JSR 380,也称为 Bean Validation 2.0,是一种标准化的 ...
- 2023年国家基地“楚慧杯”网络安全实践能力竞赛初赛-Crypto+Misc WP
Misc ez_zip 题目 4096个压缩包套娃 我的解答: 写个脚本直接解压即可: import zipfile name = '附件路径\\题目附件.zip' for i in range(40 ...
- MySQL InnoDB加锁规则分析
1. 基础知识回顾 1.索引的有序性,索引本身就是有序的 2.InnoDB中间隙锁的唯一目的是防止其他事务插入间隙.间隙锁可以共存.一个事务取得的间隙锁并不会阻止另一个事务取得同一间隙上的间隙锁.共 ...
- Kernel Memory 入门系列:生成并获取文档摘要
Kernel Memory 入门系列:生成并获取文档摘要 前面在RAG和文档预处理的流程中,我们得到一个解决方案,可以让用户直接获取最终的问题答案. 但是实际的业务场景中,仍然存在一些基础的场景,不需 ...