Hadoop面试题总结(二)——HDFS
1、 HDFS 中的 block 默认保存几份?
默认保存3份
2、HDFS 默认 BlockSize 是多大?
默认64MB
3、负责HDFS数据存储的是哪一部分?
DataNode负责数据存储
4、SecondaryNameNode的目的是什么?
他的目的使帮助NameNode合并编辑日志,减少NameNode 启动时间
5、文件大小设置,增大有什么影响?
HDFS中的文件在物理上是分块存储(block),块的大小可以通过配置参数( dfs.blocksize)来规定,默认大小在hadoop2.x版本中是128M,老版本中是64M。
思考:为什么块的大小不能设置的太小,也不能设置的太大?
HDFS的块比磁盘的块大,其目的是为了最小化寻址开销。如果块设置得足够大,从磁盘传输数据的时间会明显大于定位这个块开始位置所需的时间。
因而,传输一个由多个块组成的文件的时间取决于磁盘传输速率。
如果寻址时间约为10ms,而传输速率为100MB/s,为了使寻址时间仅占传输时间的1%,我们要将块大小设置约为100MB。默认的块大小128MB。
块的大小:10ms×100×100M/s = 100M,如图
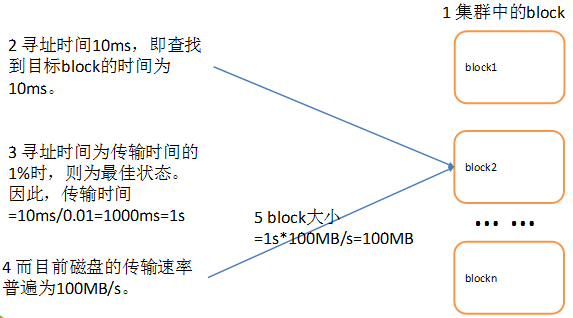
增加文件块大小,需要增加磁盘的传输速率。
6、hadoop的块大小,从哪个版本开始是128M
Hadoop1.x都是64M,hadoop2.x开始都是128M。
7、HDFS的存储机制(☆☆☆☆☆)
HDFS存储机制,包括HDFS的写入数据过程和读取数据过程两部分
HDFS写数据过程
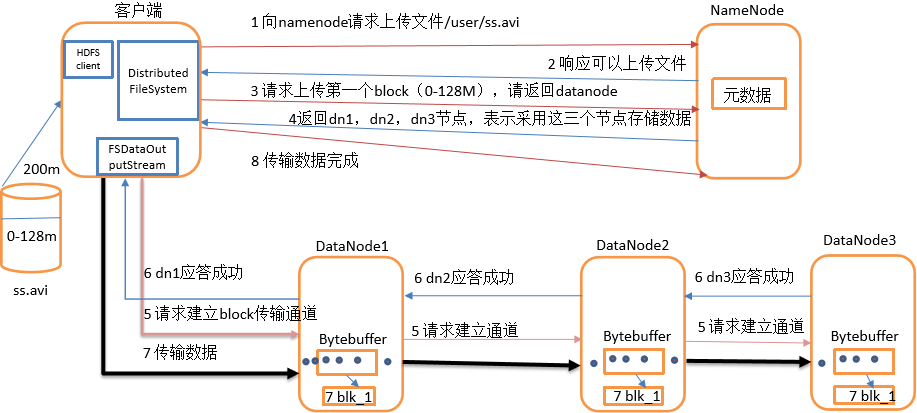
1)客户端通过Distributed FileSystem模块向NameNode请求上传文件,NameNode检查目标文件是否已存在,父目录是否存在。
2)NameNode返回是否可以上传。
3)客户端请求第一个 block上传到哪几个datanode服务器上。
4)NameNode返回3个datanode节点,分别为dn1、dn2、dn3。
5)客户端通过FSDataOutputStream模块请求dn1上传数据,dn1收到请求会继续调用dn2,然后dn2调用dn3,将这个通信管道建立完成。
6)dn1、dn2、dn3逐级应答客户端。
7)客户端开始往dn1上传第一个block(先从磁盘读取数据放到一个本地内存缓存),以packet为单位,dn1收到一个packet就会传给dn2,dn2传给dn3;
dn1每传一个packet会放入一个应答队列等待应答。
8)当一个block传输完成之后,客户端再次请求NameNode上传第二个block的服务器。(重复执行3-7步)。
HDFS读数据过程
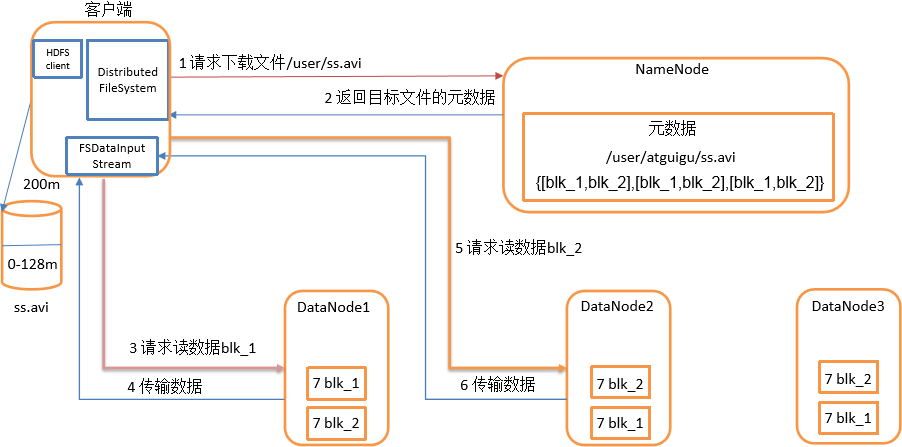
1)客户端通过Distributed FileSystem向NameNode请求下载文件,NameNode通过查询元数据,找到文件块所在的DataNode地址。
2)挑选一台DataNode(就近原则,然后随机)服务器,请求读取数据。
3)DataNode开始传输数据给客户端(从磁盘里面读取数据输入流,以packet为单位来做校验)。
4)客户端以packet为单位接收,先在本地缓存,然后写入目标文件。
8、secondary namenode工作机制(☆☆☆☆☆)
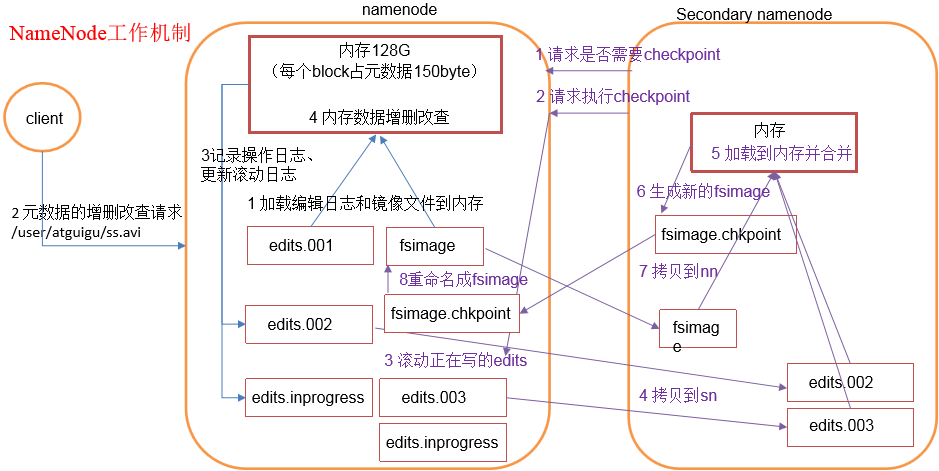
1)第一阶段:NameNode启动
(1)第一次启动NameNode格式化后,创建fsimage和edits文件。如果不是第一次启动,直接加载编辑日志和镜像文件到内存。
(2)客户端对元数据进行增删改的请求。
(3)NameNode记录操作日志,更新滚动日志。
(4)NameNode在内存中对数据进行增删改查。
2)第二阶段:Secondary NameNode工作
(1)Secondary NameNode询问NameNode是否需要checkpoint。直接带回NameNode是否检查结果。
(2)Secondary NameNode请求执行checkpoint。
(3)NameNode滚动正在写的edits日志。
(4)将滚动前的编辑日志和镜像文件拷贝到Secondary NameNode。
(5)Secondary NameNode加载编辑日志和镜像文件到内存,并合并。
(6)生成新的镜像文件fsimage.chkpoint。
(7)拷贝fsimage.chkpoint到NameNode。
(8)NameNode将fsimage.chkpoint重新命名成fsimage。
9、NameNode与SecondaryNameNode 的区别与联系?(☆☆☆☆☆)
机制流程看第7题
1)区别
(1)NameNode负责管理整个文件系统的元数据,以及每一个路径(文件)所对应的数据块信息。
(2)SecondaryNameNode主要用于定期合并命名空间镜像和命名空间镜像的编辑日志。
2)联系:
(1)SecondaryNameNode中保存了一份和namenode一致的镜像文件(fsimage)和编辑日志(edits)。
(2)在主namenode发生故障时(假设没有及时备份数据),可以从SecondaryNameNode恢复数据。
10、HDFS组成架构(☆☆☆☆☆)
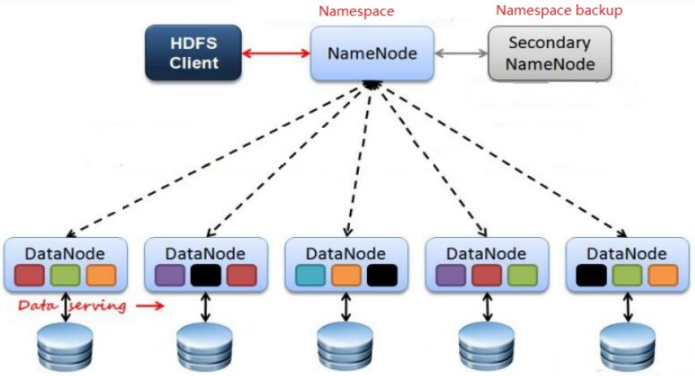
架构主要由四个部分组成,分别为HDFS Client、NameNode、DataNode和Secondary NameNode。下面我们分别介绍这四个组成部分。
1)Client:就是客户端。
(1)文件切分。文件上传HDFS的时候,Client将文件切分成一个一个的Block,然后进行存储;
(2)与NameNode交互,获取文件的位置信息;
(3)与DataNode交互,读取或者写入数据;
(4)Client提供一些命令来管理HDFS,比如启动或者关闭HDFS;
(5)Client可以通过一些命令来访问HDFS;
2)NameNode:就是Master,它是一个主管、管理者。
(1)管理HDFS的名称空间;
(2)管理数据块(Block)映射信息;
(3)配置副本策略;
(4)处理客户端读写请求。
3)DataNode:就是Slave。NameNode下达命令,DataNode执行实际的操作。
(1)存储实际的数据块;
(2)执行数据块的读/写操作。
4)Secondary NameNode:并非NameNode的热备。当NameNode挂掉的时候,它并不能马上替换NameNode并提供服务。
(1)辅助NameNode,分担其工作量;
(2)定期合并Fsimage和Edits,并推送给NameNode;
(3)在紧急情况下,可辅助恢复NameNode。
11、HAnamenode 是如何工作的? (☆☆☆☆☆)
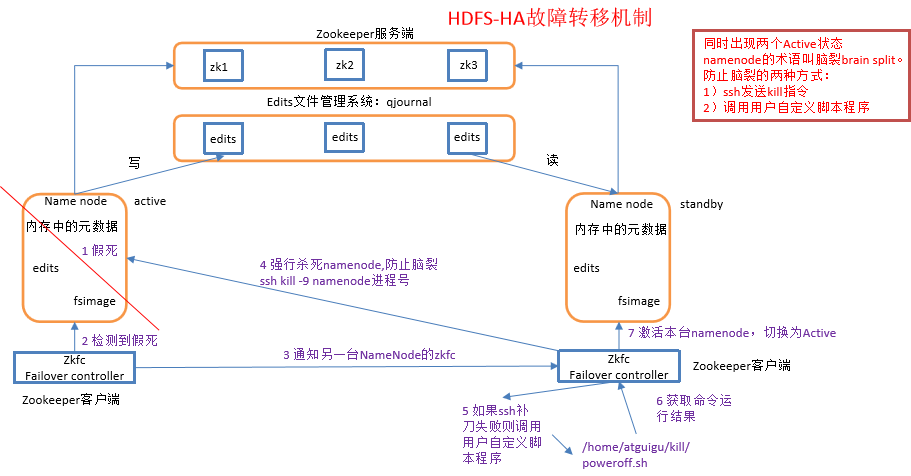
ZKFailoverController主要职责
1)健康监测:周期性的向它监控的NN发送健康探测命令,从而来确定某个NameNode是否处于健康状态,如果机器宕机,心跳失败,那么zkfc就会标记它处于一个不健康的状态。
2)会话管理:如果NN是健康的,zkfc就会在zookeeper中保持一个打开的会话,如果NameNode同时还是Active状态的,那么zkfc还会在Zookeeper中占有一个类型为短暂类型的znode,当这个NN挂掉时,这个znode将会被删除,然后备用的NN,将会得到这把锁,升级为主NN,同时标记状态为Active。
3)当宕机的NN新启动时,它会再次注册zookeper,发现已经有znode锁了,便会自动变为Standby状态,如此往复循环,保证高可靠,需要注意,目前仅仅支持最多配置2个NN。
4)master选举:如上所述,通过在zookeeper中维持一个短暂类型的znode,来实现抢占式的锁机制,从而判断那个NameNode为Active状态
Hadoop面试题总结(二)——HDFS的更多相关文章
- Hadoop学习之旅二:HDFS
本文基于Hadoop1.X 概述 分布式文件系统主要用来解决如下几个问题: 读写大文件 加速运算 对于某些体积巨大的文件,比如其大小超过了计算机文件系统所能存放的最大限制或者是其大小甚至超过了计算机整 ...
- hadoop(二):hdfs HA原理及安装
早期的hadoop版本,NN是HDFS集群的单点故障点,每一个集群只有一个NN,如果这个机器或进程不可用,整个集群就无法使用.为了解决这个问题,出现了一堆针对HDFS HA的解决方案(如:Linux ...
- 【Todo】找出共同好友 & Spark & Hadoop面试题
找了这篇文章看了一下面试题<Spark 和hadoop的一些面试题(准备)> http://blog.csdn.net/qiezikuaichuan/article/details/515 ...
- Spark面试题(二)
首发于我的个人博客:Spark面试题(二) 1.Spark有哪两种算子? Transformation(转化)算子和Action(执行)算子. 2.Spark有哪些聚合类的算子,我们应该尽量避免什么类 ...
- Hadoop阅读笔记(二)——利用MapReduce求平均数和去重
前言:圣诞节来了,我怎么能虚度光阴呢?!依稀记得,那一年,大家互赠贺卡,短短几行字,字字融化在心里:那一年,大家在水果市场,寻找那些最能代表自己心意的苹果香蕉梨,摸着冰冷的水果外皮,内心早已滚烫.这一 ...
- Hadoop 面试题之Hbase
Hadoop 面试题之九 16.Hbase 的rowkey 怎么创建比较好?列族怎么创建比较好? 答: 19.Hbase 内部是什么机制? 答: 73.hbase 写数据的原理是什么? 答: 75.h ...
- hadoop面试题答案
Hadoop 面试题,看看书找答案,看看你能答对多少(2) 1. 下面哪个程序负责 HDFS 数据存储.a)NameNode b)Jobtracker c)Datanode d)secondary ...
- Apache Hadoop 2.9.2 的HDFS High Available模式部署
Apache Hadoop 2.9.2 的HDFS High Available 模式部署 作者:尹正杰 版权声明:原创作品,谢绝转载!否则将追究法律责任. 我们知道,当NameNode进程挂掉后,可 ...
- Hadoop生态集群之HDFS
一.HDFS是什么 HDFS是hadoop集群中的一个分布式的我文件存储系统.他将多台集群组建成一个集群,进行海量数据的存储.为超大数据集的应用处理带来了很多便利. 和其他的分布式文件存储系统相比他有 ...
- Hadoop开发第6期---HDFS的shell操作
一.HDFS的shell命令简介 我们都知道HDFS 是存取数据的分布式文件系统,那么对HDFS 的操作,就是文件系统的基本操作,比如文件的创建.修改.删除.修改权限等,文件夹的创建.删除.重命名等. ...
随机推荐
- 邮差之死--python源代码
"""sth imported""" import time import os '''2 flags''' flag = 0 tmp = ...
- Net 高级调试之八:代码审查及杂项命令
一.简介 今天是<Net 高级调试>的第八篇文章.这篇文章设计的内容挺多的,比如:如何查看方法的汇编代码,如何获取方法的描述符,对象同步块的转储,对象方法表的转储,托管堆和垃圾回收器信息的 ...
- 【Javaweb】五(Service类)
一般Spring项目中处理业务的层为Service层,称为业务层.目前常见的风格有: 写法:Service层=Service接口+ServiceImpl实现类 AdminServiceImpl.jav ...
- ABAP 生产订单长文本增强 <销售计划 、物料独立需求 长文本带入 计划订单-生产订单 >
计划订单长文本带入生产订单 尝试在生产订单保存后 用 creat_text 函数 去创建长文本,发现前台不显示,查看 文本抬头底表 STXL 发现有值 ,用READ 函数 读取 能读. DATA:td ...
- HttpClient报错Timeout waiting for connection from pool
报错现象 线上项目使用HttpClient请求第三方的HTTP资源,并发量高的时候,日志框报Timeout waiting for connection from pool 客户端的现象是有时正常,有 ...
- springBoot——整合mybatis
spring整合mybatis springBoot整合mybaits 配置文件 spring: datasource: url: jdbc:mysql://localhost:3306/test d ...
- CompletableFuture入门
CompletableFuture入门 1.Future vs CompletableFuture 1.1 准备工作 先定义一个工具类 import java.nio.file.Files; impo ...
- 探索 ECMAScript 2023 中的新数组方法
前言 ECMAScript 2023 引入了一些新功能,以改进语言并使其更加强大和无缝.这个新版本带来了令人兴奋的功能和新的 JavaScript 数组方法,使使用 JavaScript 编程更加愉快 ...
- Charles对Android手机Https请求的抓包
Charles对Android手机Https请求的抓包 • 前情提要: 本文只是对android手机进行抓包的描述,由于android手机系统原因,android7.0系统及以上需要在app中配置证书 ...
- ElasticSearch之Exists API
检查指定名称的索引是否存在. 命令样例如下: curl -I "https://localhost:9200/testindex_002?pretty" --cacert $ES_ ...