神经网络优化篇:详解TensorFlow
TensorFlow
先提一个启发性的问题,假设有一个损失函数\(J\)需要最小化,在本例中,将使用这个高度简化的损失函数,\(Jw= w^{2}-10w+25\),这就是损失函数,也许已经注意到该函数其实就是\({(w -5)}^{2}\),如果把这个二次方式子展开就得到了上面的表达式,所以使它最小的\(w\)值是5,但假设不知道这点,只有这个函数,来看一下怎样用TensorFlow将其最小化,因为一个非常类似的程序结构可以用来训练神经网络。其中可以有一些复杂的损失函数\(J(w,b)\)取决于的神经网络的所有参数,然后类似的,就能用TensorFlow自动找到使损失函数最小的\(w\)和\(b\)的值。但让先从左边这个更简单的例子入手。
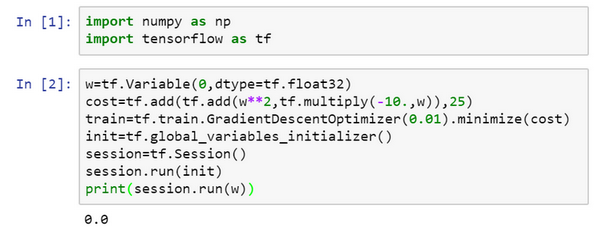
在的Jupyter notebook中运行Python,
import numpy as np
import tensorflow as tf
#导入TensorFlow
w = tf.Variable(0,dtype = tf.float32)
#接下来,让定义参数w,在TensorFlow中,要用tf.Variable()来定义参数
#然后定义损失函数:
cost = tf.add(tf.add(w**2,tf.multiply(- 10.,w)),25)
#然后定义损失函数J
然后再写:
train = tf.train.GradientDescentOptimizer(0.01).minimize(cost)
#(让用0.01的学习率,目标是最小化损失)。
#最后下面的几行是惯用表达式:
init = tf.global_variables_initializer()
session = tf.Session()#这样就开启了一个TensorFlow session。
session.run(init)#来初始化全局变量。
#然后让TensorFlow评估一个变量,要用到:
session.run(w)
#上面的这一行将w初始化为0,并定义损失函数,定义train为学习算法,它用梯度下降法优化器使损失函数最小化,但实际上还没有运行学习算法,所以#上面的这一行将w初始化为0,并定义损失函数,定义train为学习算法,它用梯度下降法优化器使损失函数最小化,但实际上还没有运行学习算法,所以session.run(w)评估了w,让::
print(session.run(w))
所以如果运行这个,它评估\(w\)等于0,因为什么都还没运行。
#现在让输入:
$session.run(train),它所做的就是运行一步梯度下降法。
#接下来在运行了一步梯度下降法后,让评估一下w的值,再print:
print(session.run(w))
#在一步梯度下降法之后,w现在是0.1。

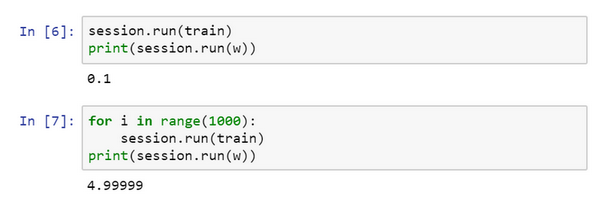
现在运行梯度下降1000次迭代:

这是运行了梯度下降的1000次迭代,最后\(w\)变成了4.99999,记不记得说\({(w -5)}^{2}\)最小化,因此\(w\)的最优值是5,这个结果已经很接近了。
希望这个让对TensorFlow程序的大致结构有了了解,当做编程练习,使用更多TensorFlow代码时,这里用到的一些函数会熟悉起来,这里有个地方要注意,\(w\)是想要优化的参数,因此将它称为变量,注意需要做的就是定义一个损失函数,使用这些add和multiply之类的函数。TensorFlow知道如何对add和mutiply,还有其它函数求导,这就是为什么只需基本实现前向传播,它能弄明白如何做反向传播和梯度计算,因为它已经内置在add,multiply和平方函数中。
对了,要是觉得这种写法不好看的话,TensorFlow其实还重载了一般的加减运算等等,因此也可以把\(cost\)写成更好看的形式,把之前的cost标成注释,重新运行,得到了同样的结果。
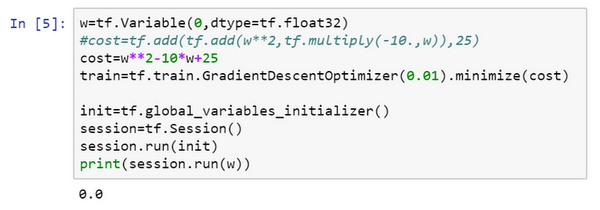
一旦\(w\)被称为TensorFlow变量,平方,乘法和加减运算都重载了,因此不必使用上面这种不好看的句法。
TensorFlow还有一个特点,想告诉,那就是这个例子将\(w\)的一个固定函数最小化了。如果想要最小化的函数是训练集函数又如何呢?不管有什么训练数据\(x\),当训练神经网络时,训练数据\(x\)会改变,那么如何把训练数据加入TensorFlow程序呢?
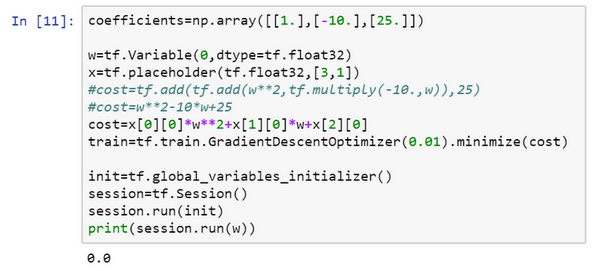
会定义\(x\),把它想做扮演训练数据的角色,事实上训练数据有\(x\)和\(y\),但这个例子中只有\(x\),把\(x\)定义为:
x = tf.placeholder(tf.float32,[3,1]),让它成为\([3,1]\)数组,要做的就是,因为\(cost\)这个二次方程的三项前有固定的系数,它是\(w^{2}+10w + 25\),可以把这些数字1,-10和25变成数据,要做的就是把\(cost\)替换成:
cost = x[0][0]*w**2 +x[1][0]*w + x[2][0],现在\(x\)变成了控制这个二次函数系数的数据,这个placeholder函数告诉TensorFlow,稍后会为\(x\)提供数值。
让再定义一个数组,coefficient = np.array([[1.],[-10.],[25.]]),这就是要接入\(x\)的数据。最后需要用某种方式把这个系数数组接入变量\(x\),做到这一点的句法是,在训练这一步中,要提供给\(x\)的数值,在这里设置:
feed_dict = {x:coefficients}
好了,希望没有语法错误,重新运行它,希望得到和之前一样的结果。
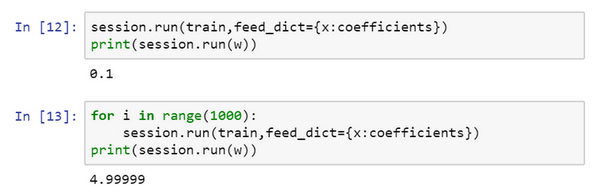
现在如果想改变这个二次函数的系数,假设把:
coefficient = np.array([[1.],[-10.],[25.]])
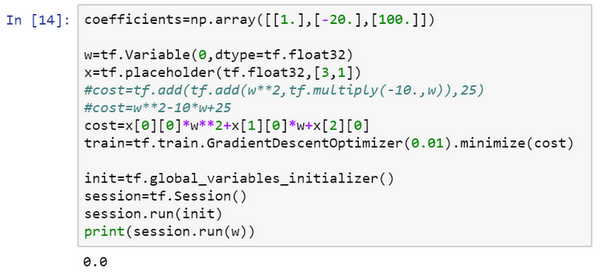
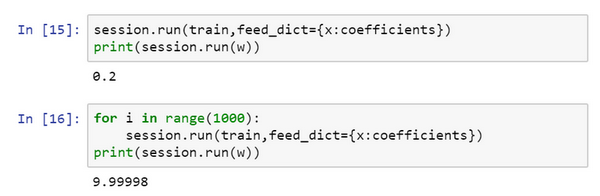
改为:coefficient = np.array([[1.],[-20.],[100.]])
现在这个函数就变成了\({(w -10)}^{2}\),如果重新运行,希望得到的使\({(w -10)}^{2}\)最小化的\(w\)值为10,让看一下,很好,在梯度下降1000次迭代之后,得到接近10的\(w\)。
在做编程练习时,见到更多的是,TensorFlow中的placeholder是一个之后会赋值的变量,这种方式便于把训练数据加入损失方程,把数据加入损失方程用的是这个句法,当运行训练迭代,用feed_dict来让x=coefficients。如果在做mini-batch梯度下降,在每次迭代时,需要插入不同的mini-batch,那么每次迭代,就用feed_dict来喂入训练集的不同子集,把不同的mini-batch喂入损失函数需要数据的地方。
希望这让了解了TensorFlow能做什么,让它如此强大的是,只需说明如何计算损失函数,它就能求导,而且用一两行代码就能运用梯度优化器,Adam优化器或者其他优化器。

这还是刚才的代码,稍微整理了一下,尽管这些函数或变量看上去有点神秘,但在做编程练习时多练习几次就会熟悉起来了。

还有最后一点想提一下,这三行(蓝色大括号部分)在TensorFlow里是符合表达习惯的,有些程序员会用这种形式来替代,作用基本上是一样的。
但这个with结构也会在很多TensorFlow程序中用到,它的意思基本上和左边的相同,但是Python中的with命令更方便清理,以防在执行这个内循环时出现错误或例外。所以也会在编程练习中看到这种写法。那么这个代码到底做了什么呢?让看这个等式:
cost =x[0][0]*w**2 +x[1][0]*w + x[2][0]#(w-5)**2
TensorFlow程序的核心是计算损失函数,然后TensorFlow自动计算出导数,以及如何最小化损失,因此这个等式或者这行代码所做的就是让TensorFlow建立计算图,计算图所做的就是取\(x[0][0]\),取\(w\),然后将它平方,然后\(x[0][0]\)和\(w^{2}\)相乘,就得到了\(x[0][0]*w^{2}\),以此类推,最终整个建立起来计算\(cost = [0][0]*w**2 + x[1][0]*w + x[2][0]\),最后得到了损失函数。

TensorFlow的优点在于,通过用这个计算损失,计算图基本实现前向传播,TensorFlow已经内置了所有必要的反向函数,回忆一下训练深度神经网络时的一组前向函数和一组反向函数,而像TensorFlow之类的编程框架已经内置了必要的反向函数,这也是为什么通过内置函数来计算前向函数,它也能自动用反向函数来实现反向传播,即便函数非常复杂,再帮计算导数,这就是为什么不需要明确实现反向传播,这是编程框架能帮变得高效的原因之一。

如果看TensorFlow的使用说明,只是指出TensorFlow的说明用了一套和不太一样的符号来画计算图,它用了\(x[0][0]\),\(w\),然后它不是写出值,想这里的\(w^{2}\),TensorFlow使用说明倾向于只写运算符,所以这里就是平方运算,而这两者一起指向乘法运算,以此类推,然后在最后的节点,猜应该是一个将\(x[2][0]\)加上去得到最终值的加法运算。
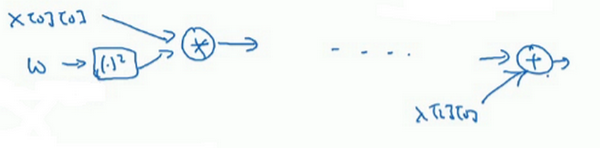
认为计算图用第一种方式会更容易理解,但是如果去看TensorFlow的使用说明,如果看到说明里的计算图,会看到另一种表示方式,节点都用运算来标记而不是值,但这两种呈现方式表达的是同样的计算图。
在编程框架中可以用一行代码做很多事情,例如,不想用梯度下降法,而是想用Adam优化器,只要改变这行代码,就能很快换掉它,换成更好的优化算法。所有现代深度学习编程框架都支持这样的功能,让很容易就能编写复杂的神经网络。
神经网络优化篇:详解TensorFlow的更多相关文章
- PHP函数篇详解十进制、二进制、八进制和十六进制转换函数说明
PHP函数篇详解十进制.二进制.八进制和十六进制转换函数说明 作者: 字体:[增加 减小] 类型:转载 中文字符编码研究系列第一期,PHP函数篇详解十进制.二进制.八进制和十六进制互相转换函数说明 ...
- 走向DBA[MSSQL篇] 详解游标
原文:走向DBA[MSSQL篇] 详解游标 前篇回顾:上一篇虫子介绍了一些不常用的数据过滤方式,本篇详细介绍下游标. 概念 简单点说游标的作用就是存储一个结果集,并根据语法将这个结果集的数据逐条处理. ...
- 十图详解tensorflow数据读取机制(附代码)转知乎
十图详解tensorflow数据读取机制(附代码) - 何之源的文章 - 知乎 https://zhuanlan.zhihu.com/p/27238630
- Scala进阶之路-Scala函数篇详解
Scala进阶之路-Scala函数篇详解 作者:尹正杰 版权声明:原创作品,谢绝转载!否则将追究法律责任. 一.传值调用和传名调用 /* @author :yinzhengjie Blog:http: ...
- tensorflow 1.0 学习:十图详解tensorflow数据读取机制
本文转自:https://zhuanlan.zhihu.com/p/27238630 在学习tensorflow的过程中,有很多小伙伴反映读取数据这一块很难理解.确实这一块官方的教程比较简略,网上也找 ...
- 十图详解tensorflow数据读取机制
在学习tensorflow的过程中,有很多小伙伴反映读取数据这一块很难理解.确实这一块官方的教程比较简略,网上也找不到什么合适的学习材料.今天这篇文章就以图片的形式,用最简单的语言,为大家详细解释一下 ...
- 详解Tensorflow数据读取有三种方式(next_batch)
转自:https://blog.csdn.net/lujiandong1/article/details/53376802 Tensorflow数据读取有三种方式: Preloaded data: 预 ...
- 十图详解TensorFlow数据读取机制(附代码)
在学习TensorFlow的过程中,有很多小伙伴反映读取数据这一块很难理解.确实这一块官方的教程比较简略,网上也找不到什么合适的学习材料.今天这篇文章就以图片的形式,用最简单的语言,为大家详细解释一下 ...
- 【转载】 十图详解tensorflow数据读取机制(附代码)
原文地址: https://zhuanlan.zhihu.com/p/27238630 何之源 深度学习(Deep Learning) 话题的优秀回答者 --------------- ...
- CentOS 7 下编译安装lnmp之PHP篇详解
一.安装环境 宿主机=> win7,虚拟机 centos => 系统版本:centos-release-7-5.1804.el7.centos.x86_64 二.PHP下载 官网 http ...
随机推荐
- MongoDB的安装使用与监控
MongoDB的安装使用与监控 下载 https://www.mongodb.com/try/download/community 我这边习惯于下载 Windows 的 MSI 进行安装 Linux ...
- Spring Cloud 系列:基于Seata 实现 XA模式
https://seata.io/zh-cn/docs/user/mode/xa https://seata.io/zh-cn/docs/dev/mode/xa-mode XA 规范 是 X/Open ...
- 2020第二届长安杯wp
1 检材 1 的操作系统版本是 A. CentOS release 6.5 (Final) B. Ubuntu 16.04.3 LTS C. Debian GNU/Linux 7.8 (wheezy) ...
- Unity2020或Unity2019安装后无法启动
无法启动Unity 下载国际版的Unity2020,双击Unity.exe无法启动,通过Unity Hub也无法启动 原因 通过查看unity hub的日志发现Unity 启动的时候会检查 lie ...
- java8新特性知识整理
目录 前言 Lambda 表达式 方法引用 函数式接口 Stream 流 构造流的几种方式 常用 api Collectors.toMap (List 转 Map) peek 和 map 区别 gro ...
- 声明式API和命令式API的区别
声明式API 声明式和命令式的对比 Kubernetes 声明式 API 的工作原理 参考 声明式API 声明式和命令式的对比 命令式 命令式有时也称为指令式,命令式的场景下,计算机只会机械的完成指定 ...
- 【2】Pycharm插件推荐,超级实用!每个小trick都可以快速提升变成效率!
相关文章: [1]Pycharm 主题设置推荐Material Theme UI以及编辑环境配置(字体大小和颜色) [2]Pycharm插件推荐,超级实用!每个小trick都可以快速提升变成效率! [ ...
- 19.11 Boost Asio 获取远程目录
远程目录列表的获取也是一种很常用的功能,通常在远程控制软件中都存在此类功能,实现此功能可以通过filesystem.hpp库中的directory_iterator迭代器来做,该迭代器用于遍历目录中的 ...
- STL源码剖析 | priority_queue优先队列底层模拟实现
今天博主继续带来STL源码剖析专栏的第四篇博客了! 今天带来优先队列priority_queue的模拟实现!话不多说,直接进入我们今天的内容! 前言 那么这里博主先安利一下一些干货满满的专栏啦! 手撕 ...
- InnoDB存储引擎的行级锁
InnoDB存储引擎的行级锁 InnoDB存储引擎和MyISAM的其中有两个很重要的区别:一个是事务,一个就是锁机制不同.事务之前有介绍,有问题的去补课;锁方面的不同是InnoDB引擎既有表锁又有行锁 ...