什么是数据同步利器DataX,如何使用?
转载至我的博客 https://www.infrastack.cn ,公众号:架构成长指南
今天给大家分享一个阿里开源的数据同步工具DataX,在Github拥有14.8k的star,非常受欢迎,官网地址:https://github.com/alibaba/DataX
什么是 Datax?
DataX 是阿里云 DataWorks数据集成 的开源版本,使用Java 语言编写,在阿里巴巴集团内被广泛使用的离线数据同步工具/平台。DataX 实现了包括 MySQL、Oracle、OceanBase、SqlServer、Postgre、HDFS、Hive、ADS、HBase、TableStore(OTS)、MaxCompute(ODPS)、Hologres、DRDS, databend 等各种异构数据源之间高效的数据同步功能。
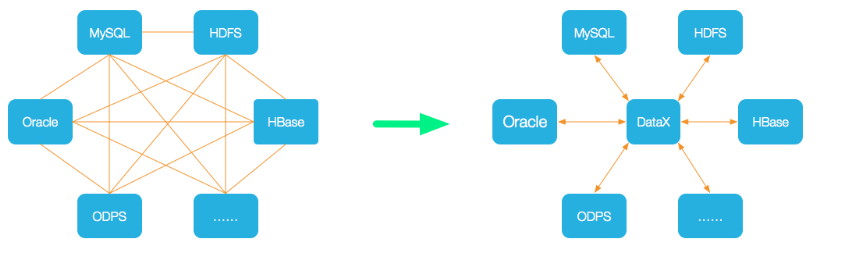
应用场景有那些?
- 数据仓库同步:DataX 可以帮助将数据从一个数据仓库(如关系型数据库、大数据存储系统等)同步到另一个数据仓库,实现数据的迁移、备份或复制。
- 数据库迁移:当我们需要将数据从一个数据库平台迁移到另一个数据库平台时,DataX 可以帮助完成数据的转移和转换工作
- 数据集成与同步:DataX 可以用作数据集成工具,用于将多个数据源的数据进行整合和同步。它支持多种数据源,包括关系型数据库、NoSQL 数据库、文件系统等,可以将这些数据源的数据整合到一个目标数据源中。
- 数据清洗与转换:DataX 提供了丰富的数据转换能力,可以对数据进行清洗、过滤、映射、格式转换等操作。这对于数据仓库、数据湖和数据集市等数据存储和分析平台非常有用,可以帮助提高数据质量和一致性。
- 数据备份与恢复:DataX 可以用于定期备份和恢复数据。通过配置定时任务,可以将数据从源端备份到目标端,并在需要时进行数据恢复。
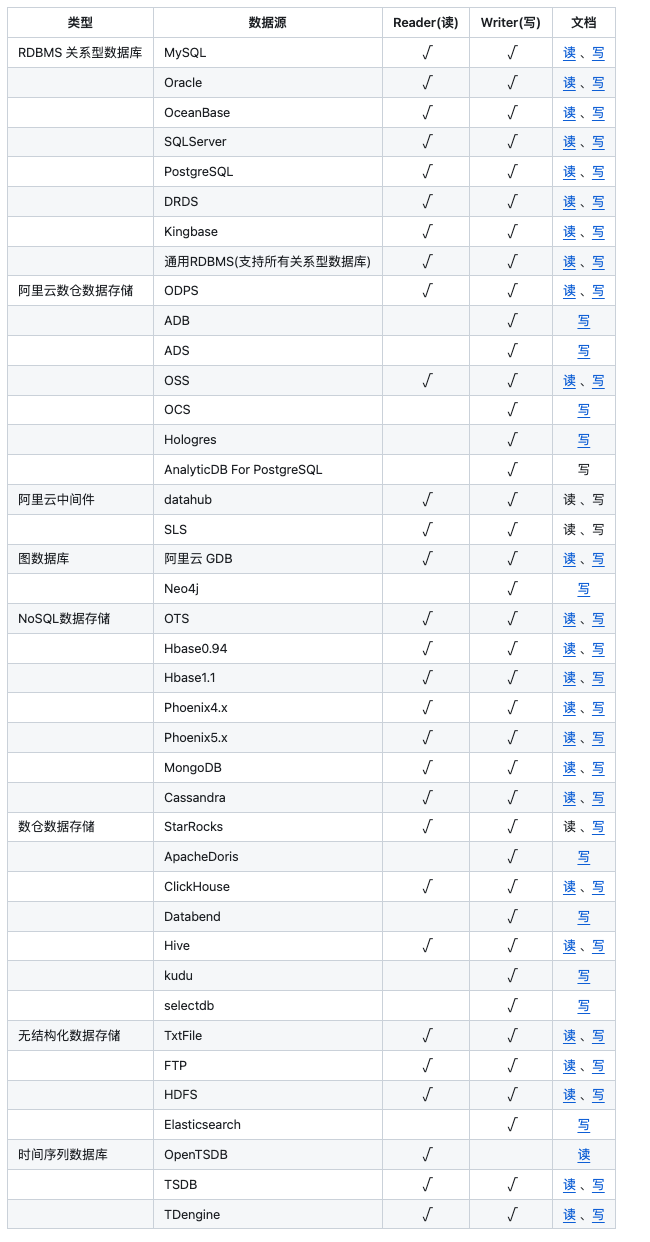
DataX支持那些数据源?
架构设计

DataX作为离线数据同步框架,采用Framework + plugin架构构建。将数据源读取和写入抽象成为Reader/Writer插件,纳入到整个同步框架中。
- Reader:Reader为数据采集模块,负责采集数据源的数据,将数据发送给Framework。
- Writer: Writer为数据写入模块,负责不断向Framework取数据,并将数据写入到目的端。
- Framework:Framework用于连接reader和writer,作为两者的数据传输通道,并处理缓冲,流控,并发,数据转换等核心技术问题。
DataX 开源版本支持单机多线程模式完成同步作业运行,如下图
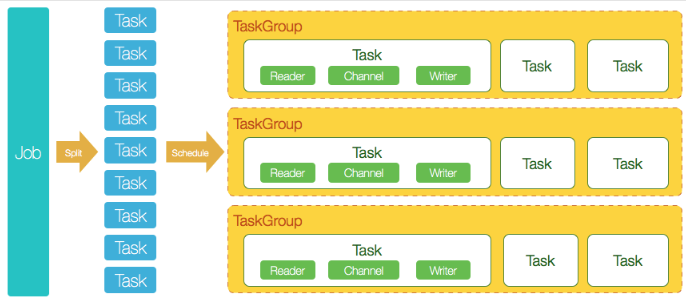
- DataX完成单个数据同步的作业,称之为Job,DataX接受到一个Job之后,将启动一个进程来完成整个作业同步过程。DataX Job模块是单个作业的中枢管理节点,承担了数据清理、子任务切分(将单一作业计算转化为多个子Task)、TaskGroup管理等功能。
- DataXJob启动后,会根据不同的源端切分策略,将Job切分成多个小的Task(子任务),以便于并发执行。Task便是DataX作业的最小单元,每一个Task都会负责一部分数据的同步工作。
- 切分多个Task之后,DataX Job会调用Scheduler模块,根据配置的并发数据量,将拆分成的Task重新组合,组装成TaskGroup(任务组)。每一个TaskGroup负责以一定的并发运行完毕分配好的所有Task,默认单个任务组的并发数量为5。
- 每一个Task都由TaskGroup负责启动,Task启动后,会固定启动Reader—>Channel—>Writer的线程来完成任务同步工作。
- DataX作业运行起来之后, Job监控并等待多个TaskGroup模块任务完成,等待所有TaskGroup任务完成后Job成功退出。否则,异常退出,进程退出值非0
DataX调度流程
举例来说,用户提交了一个DataX作业,并且配置了20个并发,目的是将一个100张表的mysql数据同步到odps里面。 DataX的调度决策是:
- Job根据分表切分成了100个Task。
- 根据20个并发,DataX计算需要分配4个TaskGroup。
- 4个TaskGroup平分切分好的100个Task,每一个TaskGroup负责5个并发共计运行25个Task。
如何使用 Datax?
点击datax 下载,下载后解压至本地某个目录,如下图

用例说明
这里为了方便演示,我们同步MySQL的user_info表至MySQL的ods_test_mysql_user_info_m,同步条件为更新时间字段,如下
在实际工作中你可以选择不同类型的数据源测试
drop table ods_test_mysql_user_info_m
CREATE TABLE `user_info` (
`id` int NOT NULL COMMENT 'ID',
`name` varchar(50) NOT NULL COMMENT '名称',
`sex` tinyint NOT NULL COMMENT '性别 1男 2女',
`phone` varchar(11) COMMENT '手机',
`address` varchar(1000) COMMENT '地址',
`age` int COMMENT '年龄',
`create_time` datetime(6) NOT NULL DEFAULT CURRENT_TIMESTAMP(6) COMMENT '创建时间',
`update_time` datetime(6) NOT NULL DEFAULT CURRENT_TIMESTAMP(6) ON UPDATE CURRENT_TIMESTAMP(6) COMMENT '修改时间',
PRIMARY KEY (`id`) USING BTREE
) ENGINE=InnoDB DEFAULT CHARSET=utf8mb3 COMMENT='用户信息表';
CREATE TABLE `ods_test_mysql_user_info_m` (
`id` int NOT NULL COMMENT 'ID',
`name` varchar(50) NOT NULL COMMENT '名称',
`sex` tinyint NOT NULL COMMENT '性别 1男 2女',
`phone` varchar(11) COMMENT '手机',
`address` varchar(1000) COMMENT '地址',
`age` int COMMENT '年龄',
`create_time` datetime(6) NOT NULL DEFAULT CURRENT_TIMESTAMP(6) COMMENT '创建时间',
`update_time` datetime(6) NOT NULL DEFAULT CURRENT_TIMESTAMP(6) ON UPDATE CURRENT_TIMESTAMP(6) COMMENT '修改时间',
PRIMARY KEY (`id`) USING BTREE
) ENGINE=InnoDB DEFAULT CHARSET=utf8mb3 COMMENT='用户信息数仓表';
在user_info表中插入数据如下

创建作业的配置文件(json格式)
在 datax 的 script 目录,创建ods_test_mysql_user_info_m.json文件,配置如下,mysqlreader表示读取端,mysqlwriter表示写入端
{
"job": {
"content": [
{
"reader": {
"name": "mysqlreader",
"parameter": {
"column": ["id","name","sex","phone","address","age","create_time","update_time"],
"splitPk": "id",
"connection": [
{
"jdbcUrl": ["jdbc:mysql://127.0.0.1:3306/test?useUnicode=true&characterEncoding=utf-8&useSSL=false"],
"table": ["user_info"]
}
],
"password": "root",
"username": "root",
"where": "update_time > '${updateTime}' "
}
},
"writer": {
"name": "mysqlwriter",
"parameter": {
"writeMode": "replace",
"column": ["id","name","sex","phone","address","age","create_time","update_time"],
"connection": [
{
"jdbcUrl":"jdbc:mysql://127.0.0.1:3306/test?useUnicode=true&characterEncoding=utf-8&useSSL=false",
"table": ["ods_test_mysql_user_info_m"]
}
],
"username": "root",
"password": "root",
"preSql": [],
"session": [
"set session sql_mode='ANSI'"
]
}
}
}
],
"setting": {
"speed": {
"channel": "5"
}
}
}
}
创建执行脚本
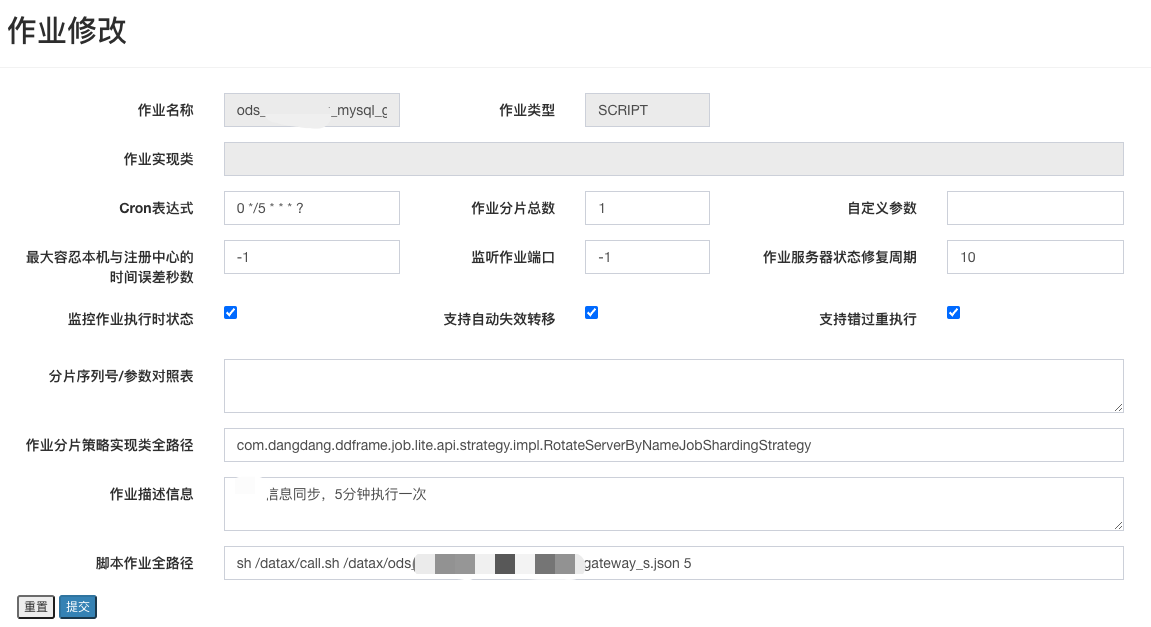
为了更贴合实际,写一个调度脚本sync.sh支持动态参数来执行任务
#!/bin/bash
## 执行示例 sh /Users/weizhao.dong/Documents/soft/datax/datax-script/call.sh /Users/weizhao.dong/Documents/soft/datax/datax-script/dwd_g2park_inout_report_s.json 1
jsonScript=$1
echo '执行脚本:'$jsonScript
interval=$2
echo "时间间隔(分钟):"$interval
now_time=$(date '+%Y-%m-%d %H:%M:%S')
echo "当前时间:"$now_time
update_time=$(date -v -${interval}M '+%Y-%m-%d %H:%M:%S')
#linux 更新时间获取
#update_time=$(date -d "${now_time} $interval minute ago" +"%Y-%m-%d %H:%M:%S")
echo "更新时间:"$update_time
#执行
python3 /Users/weizhao.dong/Documents/soft/datax/bin/datax.py $jsonScript -p "-DupdateTime='${update_time}'"
假设我们要执以上ods_test_mysql_user_info_m.json脚本,并且同步十分钟之前的数据,如下
./sync.sh ods_test_mysql_user_info_m.json 10
测试
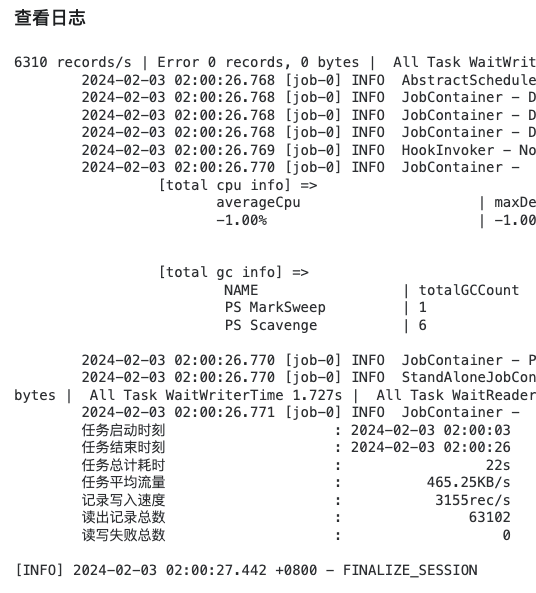
执行./sync.sh ods_test_mysql_user_info_m.json 10进行同步

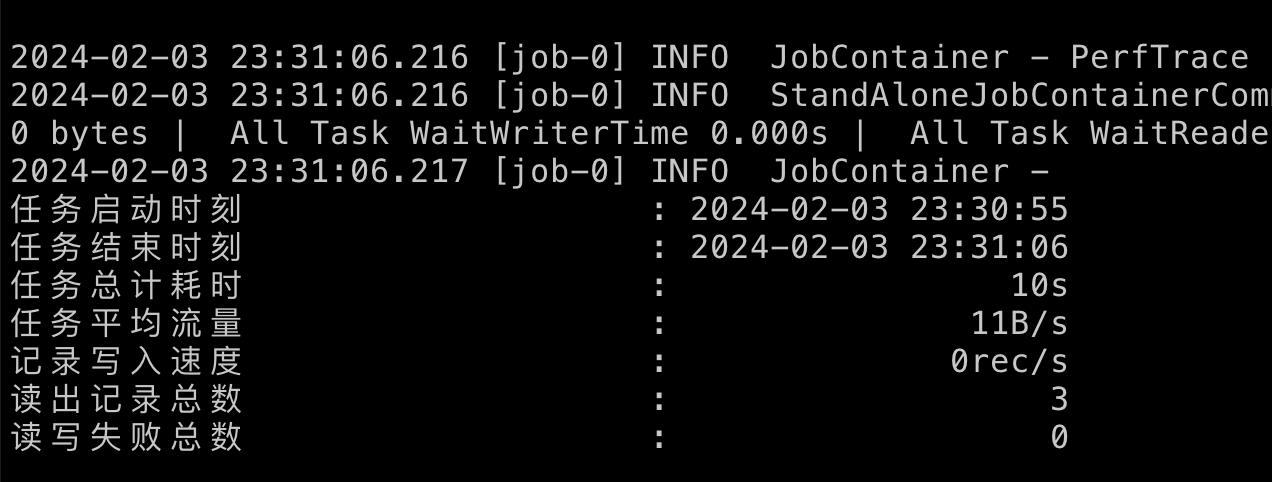
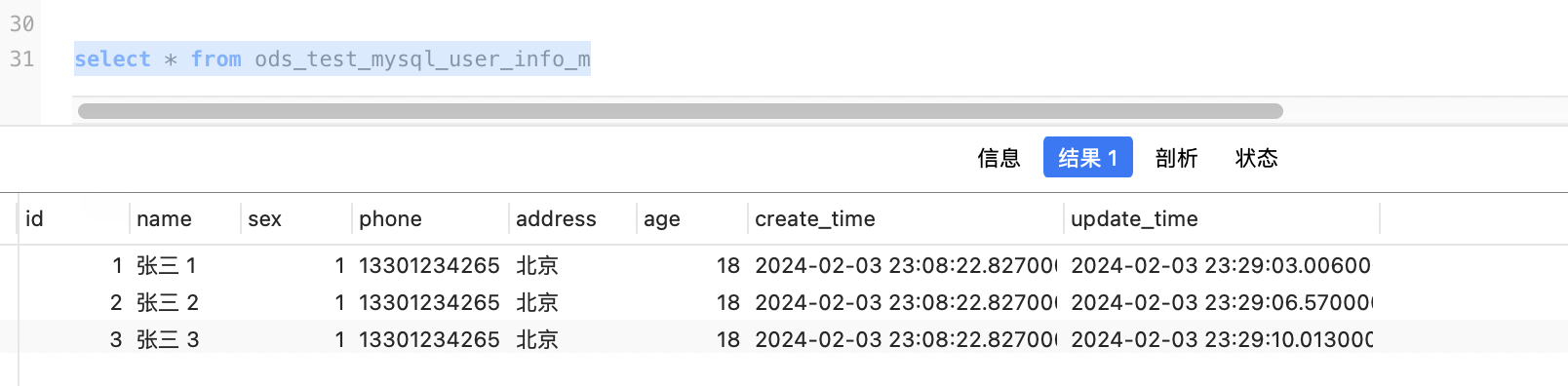
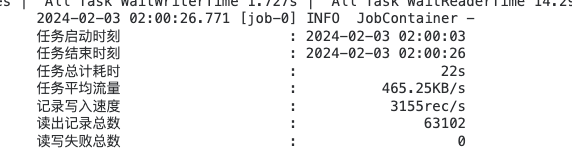
以上结果可能有些人有疑问,就三条数据执行时间为 10s,其实这个 10s主要是初始化时间,耗时过长,同步的数据量多了优势就体现出来了,以下为实际生产同步数据结果,可以看到同步63102条耗时22s
推荐用法
以上我们只是通过一个简单的示例来演示了dataX如何使用,如果只是一次性同步,没问题,但是如果是周期性进行同步,有以下几种方式推荐
crontab调度
这种方式是最简单的,可以使用操作系统中的crontab定时调度,通过crontab -e编辑corn 任务,添加对应脚本即可
海豚调度器
在种方式在大数据领域用的比较多,典型场景就是 mysql 同步到数仓,海豚调度器内置了 datax 并且提供了图形化配置界面,配置起来非常方便

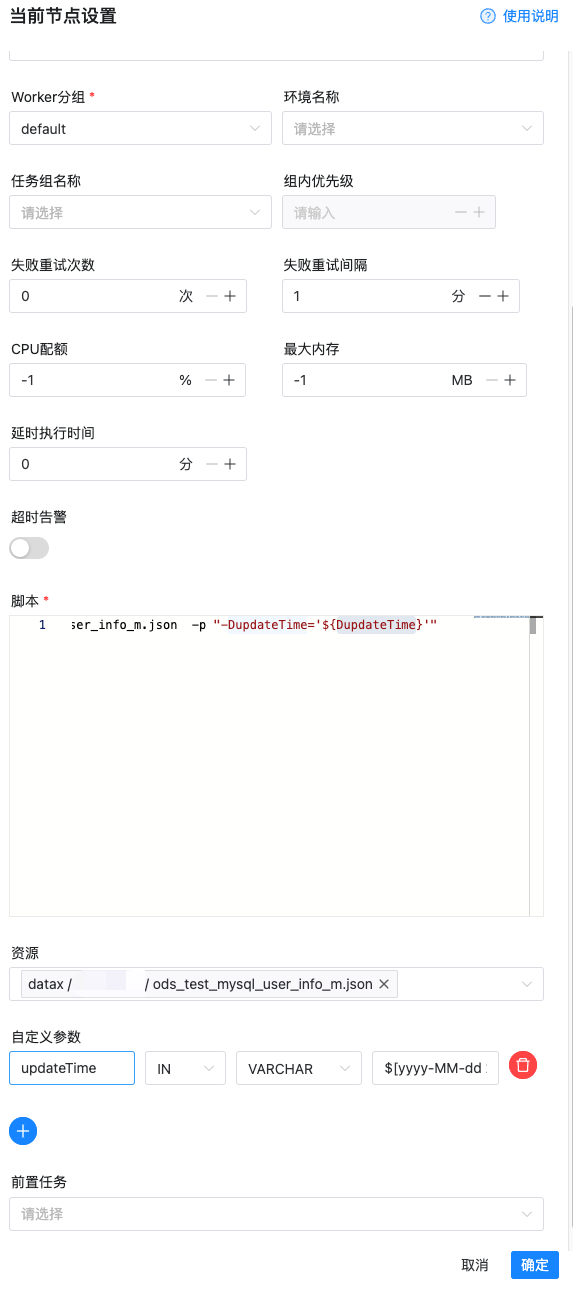
同时每次执行都有记录,并且都有对应的日志
定时任务框架(elasticjob/xxl-job)
在我们实际使用的业务系统定时调度框架都支持调度 shell 脚本,通过传入对应参数也可执行
扫描下面的二维码关注我们的微信公众帐号,在微信公众帐号中回复◉加群◉即可加入到我们的技术讨论群里面共同学习。

什么是数据同步利器DataX,如何使用?的更多相关文章
- 【转】Syncthing – 数据同步利器---自己的网盘,详细安装配置指南,内网使用,发现服务器配置
Syncthing – 数据同步利器---自己的网盘,详细安装配置指南,内网使用,发现服务器配置 原贴:https://www.cnblogs.com/jackadam/p/8568833.html ...
- 环境篇:数据同步工具DataX
环境篇:数据同步工具DataX 1 概述 https://github.com/alibaba/DataX DataX是什么? DataX 是阿里巴巴集团内被广泛使用的离线数据同步工具/平台,实现包括 ...
- 比Sqoop功能更加强大开源数据同步工具DataX实战
@ 目录 概述 定义 与Sqoop对比 框架设计 支持插件 核心架构 核心优势 部署 基础环境 安装 从stream读取数据并打印到控制台 读取MySQL写入HDFS 读取HDFS写入MySQL 执行 ...
- Syncthing – 数据同步利器---自己的网盘,详细安装配置指南,内网使用,发现服务器配置
简介: 无论办公.文件共享.团队协作还是家庭照片.视频.音乐.高清电影的存储,我们常常都有文件同步和存储的需求.但随着国内各大网盘的花式阵亡或限速,早已没什么好选择了.好吧,我已经转战使用onedri ...
- 数据同步DataX
数据同步那些事儿(优化过程分享) 简介 很久之前就想写这篇文章了,主要是介绍一下我做数据同步的过程中遇到的一些有意思的内容,和提升效率的过程. 当前在数据处理的过程中,数据同步如同血液一般充满全过 ...
- Spark记录-阿里巴巴开源工具DataX数据同步工具使用
1.官网下载 下载地址:https://github.com/alibaba/DataX DataX 是阿里巴巴集团内被广泛使用的离线数据同步工具/平台,实现包括 MySQL.Oracle.SqlSe ...
- 基于datax的数据同步平台
一.需求 由于公司各个部门对业务数据的需求,比如进行数据分析.报表展示等等,且公司没有相应的系统.数据仓库满足这些需求,最原始的办法就是把数据提取出来生成excel表发给各个部门,这个功能已经由脚本转 ...
- 数据同步工具Sqoop和DataX
在日常大数据生产环境中,经常会有集群数据集和关系型数据库互相转换的需求,在需求选择的初期解决问题的方法----数据同步工具就应运而生了.此次我们选择两款生产环境常用的数据同步工具进行讨论 Sqoop ...
- 数据同步Datax与Datax_web的部署以及使用说明
一.DataX3.0概述 DataX 是一个异构数据源离线同步工具,致力于实现包括关系型数据库(MySQL.Oracle等).HDFS.Hive.ODPS.HBase.FTP等各种异构数据源之间稳定高 ...
- 执行 dataX 数据同步命令
:: 执行 dataX 数据同步命令 @echo off set day_interval=7@echo =========开始执行dataX数据同步========= @echo 时间周期为最近%d ...
随机推荐
- [转帖]jvm学习三-MAT内存分析工具的使用
目录 1 模拟内存溢出程序 1.1 jvm配置 1.2 测试代码 2 MAT工具进行内存分析 2.1 大纲介绍 2.2 Histogram视图介绍 2.3 Leak Suspects视图介绍 2.4 ...
- CentOS8 设置开机自动登录账户的方法
CentOS8 设置开机自动登录账户的方法 修改/etc/gdm/custom.conf文件, 并且添加内容即可. vim /etc/gdm/custom.conf # 在配置节下添加如下内容. [d ...
- redis 6源码解析之 ziplist
ziplist ziplist结构 ziplist的布局如下,所有的字符默认使用小端序保存: +--------+--------+--------+--------+-------+-------+ ...
- linux中如何统计千万个文件总和
很简单.很简单.很简单.重要事情说三遍 命令:ls | grep '匹配信息' | wc -l ls查看该目录下的所有文件,果然隐藏文件也要匹配上的话,需要:ls -a grep匹配,如查看文件中有. ...
- Protocol Buffer命名空间冲突
原文在这里. 什么是Protocol Buffer命名空间冲突? 所有链接到Go二进制文件的Protocol Buffer声明都被插入到一个全局注册表中. 每个Protocol Buffer声明(例如 ...
- StackFrame和StackTrace在Unity和C#中的区别
本文通过实际例子来看看StackFrame和StackTrace有什么区别,分别在.NET和Unity中测试. .NET环境 测试代码 using System; using System.Diagn ...
- TienChin 代码格式化-项目结构大改造
代码格式化 博主下载项目之后发现,整体的代码格式化风格,与 C 那种语言很相似,说明这个作者之前就是从事这块的导致风格有点类似,我们来格式化一下,当然这不是必要的,我是没习惯这种写法所以这里我写一下我 ...
- 手把手教学构建证券知识图谱/知识库(含码源):网页获取信息、设计图谱、Cypher查询、Neo4j关系可视化展示
手把手教学构建证券知识图谱/知识库(含码源):网页获取信息.设计图谱.Cypher查询.Neo4j关系可视化展示 demo展示: 代码结构 stock-knowledge-graph/ ├── __i ...
- 8.3 NtGlobalFlag
NtGlobalFlag 是一个Windows内核全局标记,在Windows调试方案中经常用到.这个标记定义了一组系统的调试参数,包括启用或禁用调试技术的开关.造成崩溃的错误代码和处理方式等等.通过改 ...
- django 处理请求
本文基于 django runsever 入口 执行 python manage.py runserver 调用 django.core.management.commands.runserver.C ...