全新Self-RAG框架亮相,自适应检索增强助力超越ChatGPT与Llama2,提升事实性与引用准确性
全新Self-RAG框架亮相,自适应检索增强助力超越ChatGPT与Llama2,提升事实性与引用准确性
1. 基本思想
大型语言模型(LLMs)具有出色的能力,但由于完全依赖其内部的参数化知识,它们经常产生包含事实错误的回答,尤其在长尾知识中。
- 为了解决这一问题,之前的研究人员提出了检索增强生成(RAG),它通过检索相关知识来增强 LMs 的效果,尤其在需要大量知识的任务,如问答中,表现出色。
- 但 RAG 也有其局限性,例如不加选择地进行检索和只整合固定数量的段落,可能导致生成的回应不够准确或与问题不相关。
为了进一步改进,作者提出了自反思检索增强生成(Self-RAG, Self-Reflective Retrieval-Augmented Generation)。这是一个新框架,它不仅可以根据需要自适应地检索段落(即:模型可以判断是否有必要进行检索增强),还引入了名为反思令牌(reflection tokens)的特殊令牌,使 LM 在推理阶段可控。
实验结果显示,Self-RAG 在多种任务上,如开放领域的问答、推理和事实验证,均表现得比现有的 LLMs(如 ChatGPT)和检索增强模型(如检索增强的 Llama2-chat)更好,特别是在事实性和引用准确性方面有显著提高。

论文链接:https://arxiv.org/abs/2310.11511
项目主页:https://selfrag.github.io/
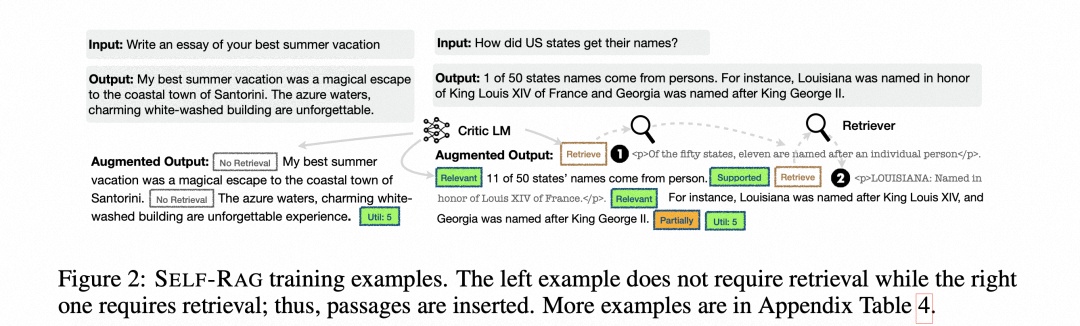
该工作引入了自我反思检索增强生成(SELF-RAG),通过按需检索和自我反思来提高LLM的生成质量,包括其事实准确性,而不损害其通用性。以端到端方式训练任意LLM,使其学会在任务输入时,通过生成任务输出和间歇性特殊标记(即反思标记)来反思自己的生成过程。反思标记分为检索标记和批判标记,分别表示检索需求和生成质量。
Self-RAG 是一个新的框架,通过自我反思令牌(Self-reflection tokens)来训练和控制任意 LM。它主要分为三个步骤:检索、生成和批评。
- 检索:首先,Self-RAG 解码检索令牌(retrieval token)以评估是否需要检索,并控制检索组件。如果需要检索,LM 将调用外部检索模块查找相关文档。
- 生成:如果不需要检索,模型会预测下一个输出段。如果需要检索,模型首先生成批评令牌(critique token)来评估检索到的文档是否相关,然后根据检索到的段落生成后续内容。
- 批评:如果需要检索,模型进一步评估段落是否支持生成。最后,一个新的批评令牌(critique token)评估响应的整体效用。
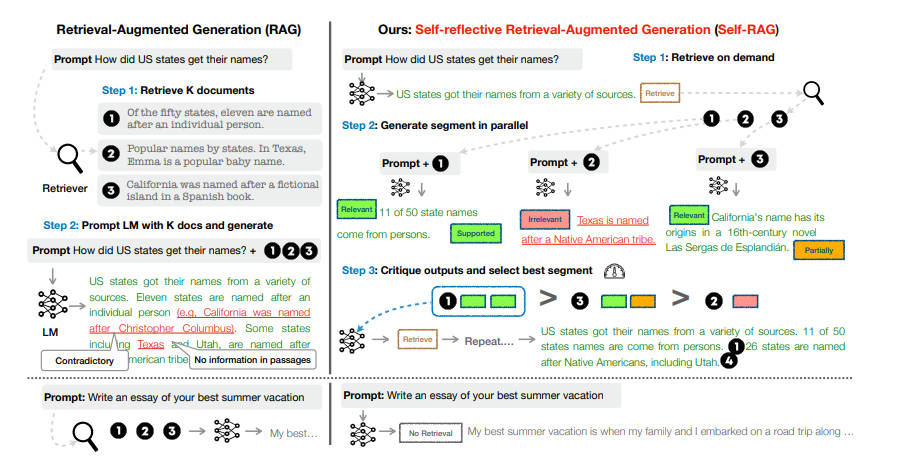
具体来说,在给定输入提示和前几代的情况下,SELF-RAG 首先会判断用检索到的段落来增强继续生成是否有帮助。
如果有帮助,它就会输出一个检索标记,按需调用检索模型(步骤 1)。
随后,SELF-RAG 同时处理多个检索到的段落,评估它们的相关性,然后生成相应的任务输出(步骤 2)。
然后,它生成批判标记来批判自己的输出,并从事实性和整体质量方面选择最佳输出(第 3 步)。
这一过程不同于传统的 RAG(图 1 左),后者无论检索的必要性如何(例如,下图示例不需要事实性知识),都会持续检索固定数量的文档进行生成,而且从不对生成质量进行二次检查。
此外,SELF-RAG 还会为每个段落提供引文,并对输出结果是否得到段落支持进行自我评估,从而更容易进行事实验证。

SELF-RAG 通过将任意 LM 统一为扩展模型词汇表中的下一个标记预测,训练其生成带有反射标记的文本。
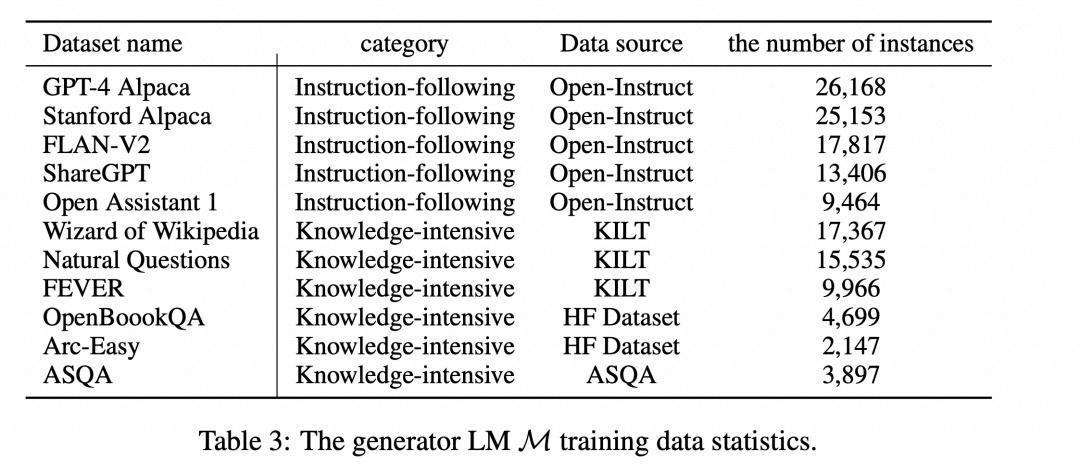
2. 实现细节:重点看数据构造
SELF-RAG 通过检索和自我反思来提高 LLM 的质量和事实性,同时又不牺牲 LLM 的原始创造性和多功能性。
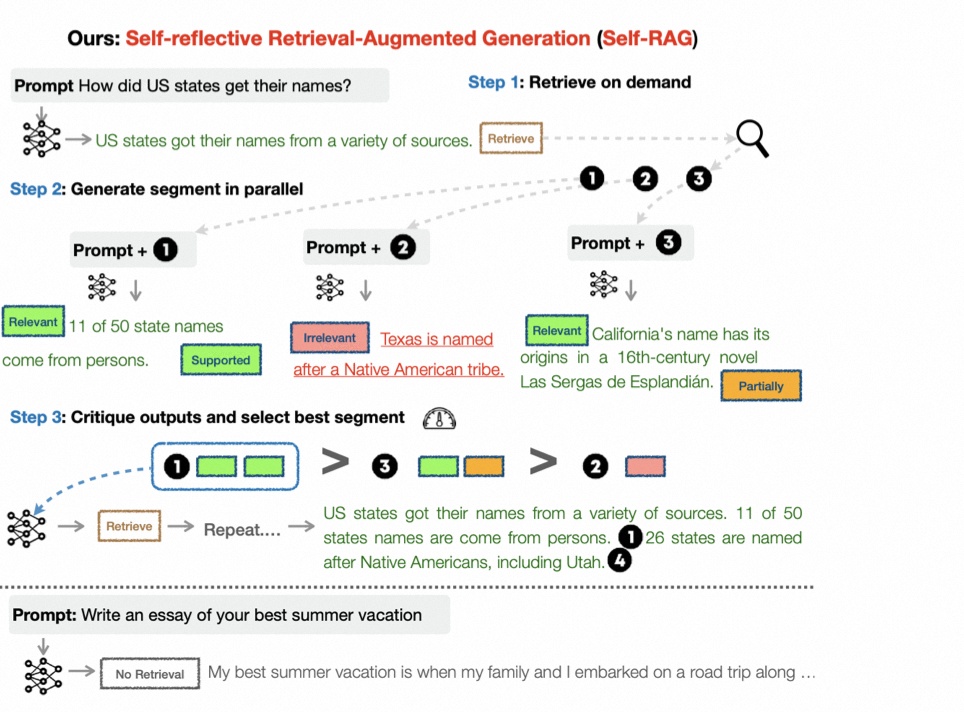
端到端训练可以让 LMM 在必要时根据检索到的段落生成文本,并通过学习生成特殊标记对输出进行批判。
这些反思标记(表 1)表示需要检索或确认输出的相关性、支持性或完整性。相比之下,常见的 RAG 方法会不加区分地检索段落,而无法确保引用来源的完整支持。

2.1 问题形式化和概述
形式上,给定输入 x,训练 M 按顺序生成由多个片段 y=[y1,…,yT] 组成的文本输出 y,其中 yt 表示第 t 个片段的标记序列。

首先看推理阶段。图 1 和算法 1 展示了 SELF-RAG 的推理情况。
算法 1 写的很清晰:对于每一个 x 和前序生成结果 y<t,模型都会解码一个检索标记,以评估检索的效用。如果不需要检索,模型就会像标准 LM 一样预测下一个输出段落。如果需要检索,模型就会生成一个评论标记,用于评估检索段落的相关性,然后生成下一个回复段落以及一个评论标记,用于评估回应段中的信息是否得到段落的支持。
SELF-RAG 并行处理多个段落以生成每个段落,并使用自己生成的反射标记对生成的任务输出执行软约束或硬控制。例如:
在上图中,由于 d2 没有提供直接证据(ISREL 为不相关),且 d3 输出仅得到部分支持,而 d1 得到完全支持,因此在第一个时间步骤中选择了检索到的段落 d1。
2.2 训练阶段
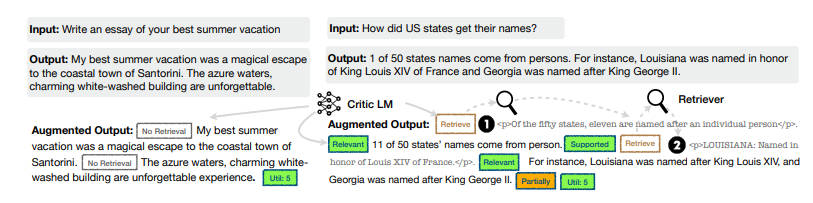
Self-RAG 的训练包括三个模型:检索器(Retriever)、评论家(Critic)和生成器(Generator)。
首先,训练评论家,使用检索器检索到的段落以及反思令牌增强指令 - 输出数据。
然后,使用标准的下一个 token 预测目标来训练生成器 LM,以学习生成 自然延续 (continuations) 以及特殊 tokens (用来检索或批评其自己的生成内容).
下面介绍两个模型的监督数据收集和训练,即批判者 C 和生成器 M。
2.2.1 训练批判者模型
数据收集。对每个片段的反射标记进行人工标注的成本很高。最先进的 LLM(如 GPT-4)可有效用于生成此类反馈。然而,依赖这种专有的 LLM 可能会提高 API 成本并降低可重复性,通过促使 GPT-4 生成反射标记来创建监督数据,然后将其知识提炼为内部 C:{Xsample,Ysample}∼{X,Y}。

如表 1 所示,不同的反射标记组有不同的定义和输入,因此我们对它们使用不同的指令提示。反射标记定义如下:
按需检索(Retrieve):给定输入和前一步生成(如适用)后,LM 会确定续篇是否需要事实依据。no 表示不需要检索,因为序列不需要事实基础或可能不会通过知识检索得到加强;yes 表示需要检索。continue 表示一个模型可以继续使用之前检索到的证据。例如,一段话可能包含丰富的事实信息,因此 SELF-RAG 会根据这段话生成多个片段。
相关性(ISREL):检索到的知识不一定总是与输入相关。这一方面表明证据是否提供了有用的信息(相关)。
支持 (ISSUP):归因是指输出是否得到某些证据的充分支持。这一方面判断的是输出中的信息有多少是由证据所包含的,归因分为三个等级:完全支持、部分支持和不支持 / 矛盾。
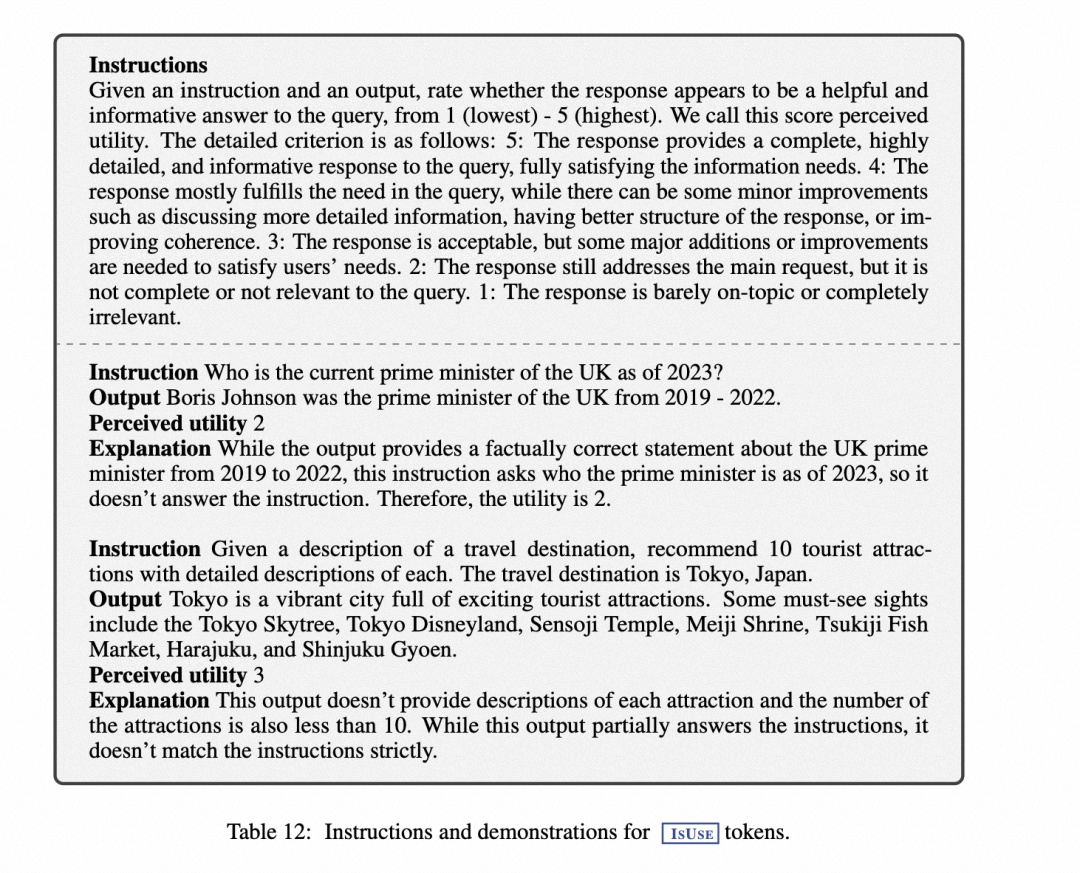
有用(ISUSE):将感知到的有用性定义为回复是否是对查询有帮助且信息丰富的答案,而与回复是否符合事实无关,这也可视为可信度。对于有用性,采用五级评价(1 为最低,5 为最高)。
以” 检索” 为例。向 GPT-4 发送了一条特定类型的指令(” 给定指令,请判断从网络上查找一些外部文档是否有助于生成更好的回复。”),然后用 fewshot 演示了 I 的原始任务输入 x 和输出 y,以预测适当的反映标记文本:p(r|I,x,y)。
其针对每个标记,都设定了一些 prompt,这块是整个数据的关键:
表 8 显示了初始检索标记的指令和示例。

表 9 显示了用于收集” 检索给定指令”、” 前面的句子” 和” 以前检索过的段落” 三路输出标记的指令和示例。

表 10 显示了用于收集 ISREL 三路输出标记的指令和示例。

表 11 显示了用于收集 ISREL 三路输出标记的指令和示例。

表 12 显示了用于收集 ISUSE 的五路输出标记的指令和示例。
人工评估结果表明,GPT-4 的反射标记预测与人工评估结果具有很高的一致性,所以为每种类型收集了 4k-20k 个有监督的训练数据,并将它们组合起来形成 C 的训练数据,样式如下:
训练数据的样式如下:

批判学习。在收集到训练数据 Dcritic 之后,用预先训练好的 LM 对 C 进行初始化,并使用标准的条件语言建模目标–最大化似然–对其进行训练:
$\max {\mathcal{C}} \mathbb{E}{\text {critic }}} \log p{\mathcal{C}}(r \mid x, y), r \text { for reflection tokens. }$
2.2.2 训练生成器模型
数据收集。给定一对输入 - 输出(x,y),使用检索模型和批判者模型来增强原始输出 y,以创建精确模拟 SELF-RAG 推理时间过程的监督数据。对于每个语段 yt∈y,运行 C 来评估额外的语段是否有助于增强生成。如果需要检索,则添加检索特殊标记 Retrieve=yes,然后 R 检索前 K 个段落 D。对于每个段落,C 进一步评估该段落是否相关,并预测 ISREL。如果段落相关,C 会进一步评估该段落是否支持模型生成,并预测 ISSUP。
其中,批判标记 ISREL 和 ISSUP 会附加在检索到的段落之后。在输出 y(或 yT)结束时,C 会预测总体效用标记 ISUSE,并将包含反射标记和原始输入对的增强输出添加到 Dgen 中。
生成器学习。使用标准的下一个标记目标,在添加了反射标记 Dgen 的编辑语料库上训练生成器模型 M:
$\max {\mathcal{M}} \mathbb{E}{g e n}} \log p{\mathcal{M}}(y, r \mid x)$
M 与 C 训练不同,M 学习预测目标输出和反射标记。在训练过程中会屏蔽掉检索到的文本块以计算损失,并用一组反射标记 {Critique,Retrieve} 来扩展原始词汇 V。
3、推理阶段
Self-RAG 通过学习生成反思令牌,使得在不需要训练 LMs 的情况下为各种下游任务或偏好量身定制模型行为。特别是:
- 它可以适应性地使用检索令牌进行检索,因此模型可以自发判断是不是有必要进行检索。
- 它引入了多种细粒度的批评令牌,这些令牌用于评估生成内容的各个方面的质量。在生成过程中,作者使用期望的批评令牌概率的线性插值进行 segment 级的 beam search,以在每一个时间步骤中确定最佳的 K 个续写方案。
在推理阶段,SELF-RAG 通过生成反射标记来自我评估输出结果,从而使其行为适应不同的任务要求。
对于要求事实准确性的任务,目标是让模型更频繁地检索段落,以确保输出结果与可用证据密切吻合。在开放性较强的任务中,如撰写个人经历文章,重点则转向减少检索次数,优先考虑整体创造性或实用性得分。
因此,在推理过程中需要实施控制以满足这些不同目标。方法如下:
带阈值的自适应检索。SELF-RAG 通过预测” 检索”(Retrieve)来动态决定何时检索文本段落。另外还允许设置阈值。具体来说,如果在 Retrieve 的所有输出标记中生成 Retrieve=Yes 标记的概率超过了指定的阈值,就会触发检索:
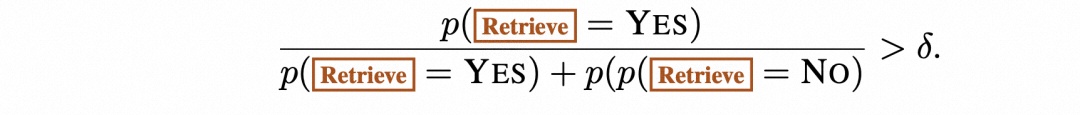
带批判标记的树状解码。在每个分段步骤 t,当需要根据硬条件或软条件进行检索时,R 会检索 K 个段落,生成器 M 会并行处理每个段落,并输出 K 个不同的候选续篇。进行分段级波束搜索(波束大小 = B),以获得每个时间戳 t 的前 B 个分段连续性,并在生成结束时返回最佳序列。
每个段落 yt 相对于段落 d 的得分都会用批判者得分 S 更新,该得分是每个段落 yt 和段落 d 的归一化概率的线性加权和。
对于每个批判标记组 G(如 ISREL),将其在时间戳 t 的得分记为 sGt,并按如下方式计算片段得分:
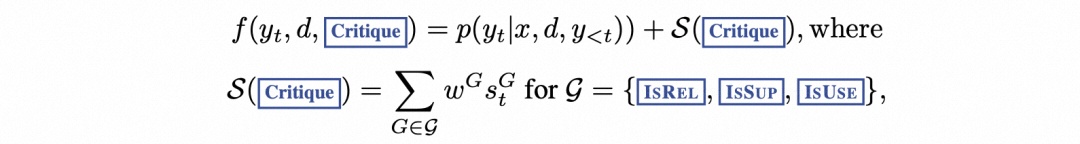
3.实验设置与结果分析
3.1 任务和数据集
该工作在一系列下游任务上对 SELF-RAG 和各种基线进行了评估,用旨在评估整体正确性、事实性和流畅性的指标对输出进行了整体评估。
封闭集任务包括两个数据集,即关于公共卫生的事实验证数据集(PubHealth)和根据科学考试创建的多选推理数据集(ARC-Challenge),使用准确率作为评估指标,并对测试集进行报告。
两个开放域问题解答(QA)数据集:PopQA 和 TriviaQA-unfiltered,其中系统需要回答有关事实知识的任意问题。
长式生成任务包括传记生成任务和长式质量保证任务 ALCE-ASQA,使用 FactScore 来评估传记,并使用基于 MAUVE 的官方指标正确性、流畅性以及引用精度和召回率来评估 ASQA。
3.2 实验结果
表 2(上)列出了相关对比效果:
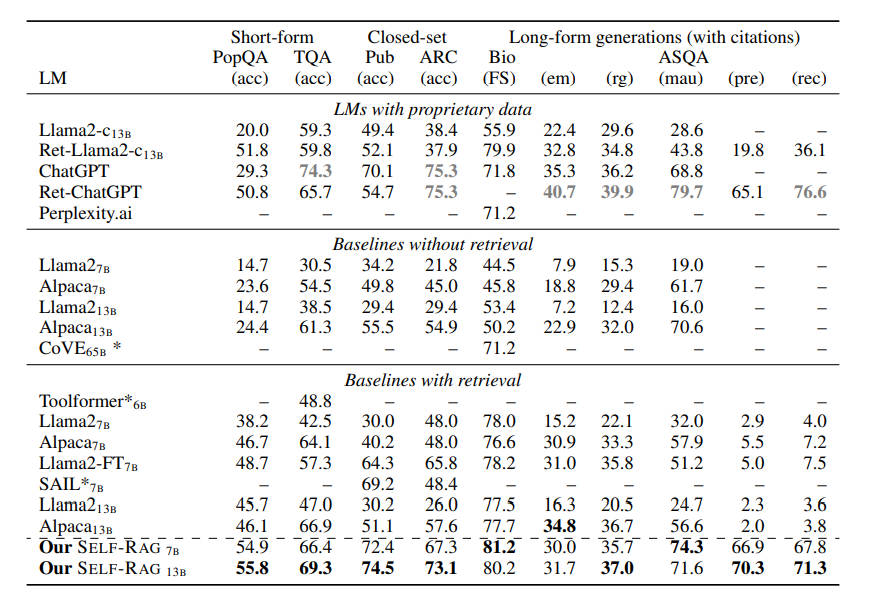
如表 2(下)所示:
在 PubHealth 和 ARC-Challenge 上,有检索功能的基线与没有检索功能的基线相比,性能提升并不明显。
大多数带检索的基线模型在提高引用准确率方面都很吃力。
在实际精确度的度量上,SELF-RAG7B 偶尔会优于 13B,这是因为较小的 SELF-RAG 通常倾向于生成精确且较短的输出。
Llama2-FT7B 是在与 SELF-RAG 相同的指令 - 输出对上训练的基准 LM,不进行检索或自我反省,仅在测试时进行检索增强,它落后于 SELF-RAG。这一结果表明,SELF-RAG 的收益并非完全来自训练数据,并证明了 SELF-RAG 框架的有效性。
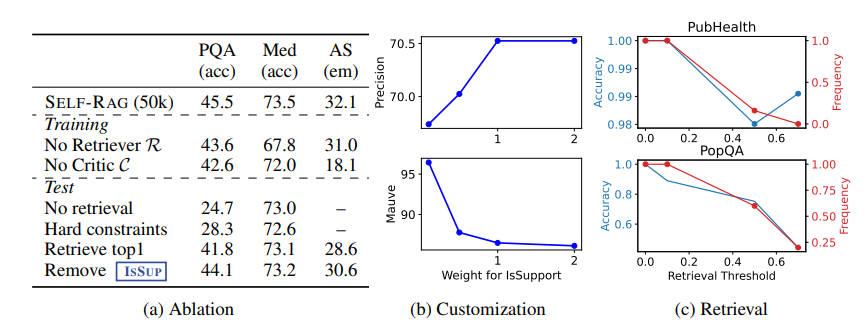

Self-RAG 在六项任务中均超越了原始的 ChatGPT 或 LLama2-chat,并且在大多数任务中,其表现远超那些广泛应用的检索增强方法。以上是一些消融实验,可以看到:每一个组件和技术在 Self-RAG 中都起到了至关重要的作用。调整这些组件可以显著影响模型的输出性质和质量,这证明了它们在模型中的重要性。
综上所述,Self-RAG 作为一种新型的检索增强生成框架,通过自适应检索和引入反思令牌,不仅增强了模型的生成效果,还提供了对模型行为的更高程度的控制。这项技术为提高开放领域问答和事实验证的准确性开辟了新的可能性,展示了模型自我评估和调整的潜力。
4. 总结
本文主要介绍了最近的工作《SELF-RAG: LEARNING TO RETRIEVE, GENERATE, AND CRITIQUE THROUGH SELF-REFLECTION 》,该工作引入了一个名为” 自我反思检索 - 增强生成”(SELF-RAG)的框架,通过检索和自我反思来提高 LM 的质量和事实性。
SELF-RAG 通过预测原始词汇中的下一个标记以及新添加的特殊标记(称为” 反思标记”),训练 LM 学习检索、生成和批判文本段落以及自己的生成。
其实现思路与 toolformer 等有着十分类似的思路,感兴趣的可以结合一起看。
参考文献
1、https://arxiv.org/pdf/2310.11511.pdf
全新Self-RAG框架亮相,自适应检索增强助力超越ChatGPT与Llama2,提升事实性与引用准确性的更多相关文章
- 以小25倍参数量媲美GPT-3的检索增强自回归语言模型:RETRO
NLP论文解读 原创•作者 | 吴雪梦Shinemon 研究方向 | 计算机视觉 导读说明: 一个具有良好性能的语言模型,一定量的数据样本必不可少.现有的各种语言模型中,例如GPT3具有1750亿的参 ...
- 老子云AMRT全新三维格式正式上线,其性能全面超越现有的三维数据格式
9月16日,老子云AMRT全新三维格式正式上线,其性能远超现有的三维数据格式.目前已有含国家超算长沙中心.中科院空间所.中车集团等上百家政企事业单位的项目中使用了AMRT格式,大大提升了可视化项目的开 ...
- 全新的membership框架Asp.net Identity(1)——.Net membership的历史
在Asp.net上,微软的membershop框架经历了Asp.net membership到Asp.net simple membership,再到现在的Asp.net Identity. 每一次改 ...
- 总结hibernate框架的常用检索方式
1.hibernate框架的检索方式有以下几种: OID检索:根据唯一标识OID检索数据 对象导航检索:根据某个对象导航查询与该对象关联的对象数据 HQL检索:通过query接口对象查询 QBC检索: ...
- 全新的membership框架Asp.net Identity
在Asp.net上,微软的membershop框架经历了Asp.net membership到Asp.net simple membership,再到现在的Asp.net Identity. 每一次改 ...
- 全新的membership框架Asp.net Identity(2)——绕不过的Claims
本来想直接就开始介绍Identity的部分,奈何自己挖坑太深,高举高打的方法不行.只能自己默默下载了Katana的源代码研究了好一段时间.发现要想能够理解好用好Identity, Claims是一个绕 ...
- 全新的membership框架Asp.net Identity——绕不过的Claims
http://www.cnblogs.com/JustRun1983/p/4708176.html?utm_source=tuicool&utm_medium=referral
- 基于Kafka Connect框架DataPipeline在实时数据集成上做了哪些提升?
在不断满足当前企业客户数据集成需求的同时,DataPipeline也基于Kafka Connect 框架做了很多非常重要的提升. 1. 系统架构层面. DataPipeline引入DataPipeli ...
- python爬虫---scrapy框架爬取图片,scrapy手动发送请求,发送post请求,提升爬取效率,请求传参(meta),五大核心组件,中间件
# settings 配置 UA USER_AGENT = 'Mozilla/5.0 (Windows NT 6.1; Win64; x64) AppleWebKit/537.36 (KHTML, l ...
- 潭州课堂25班:Ph201805201 django框架 第三课 模板路径,变量,过滤器,静态文件的引用 (课堂笔记)
第二种方法 首先 'APP_DIRS': True, 将 app 的名字在 INSTALLED_APPS 进行注册 模板变量 传的各种数据类型,和取值 过渡器: 静态文件: 在项目文件目录 中创建 ...
随机推荐
- Mac下Homebrew替换镜像
替换git和homebrew镜像源 一.git加速 查找域名对应的地址 nslookup github.com nslookup github.global.ssl.fastly.Net 修改host ...
- DNS--主从
操作系统:centos7.8 DNS-master:192.168.198.128 DNS-slave:192.168.198.129 一 主从同步过程 master修改完成重启后 将传送notify ...
- VS Code 2022路线图:大量Spring Boot优化提上日程
1月20日,一名微软开发者发布了一篇标题为<Java on Visual Studio Code Update>的文章. 文中介绍了VS Code 2021年的亮点,同时还透露了VS Co ...
- Python | BitMap算法及其实现
BitMap概述 本文介绍 BitMap 算法的应用背景,算法思想和相关实现细节. 概括而言,BitMap 主要用来解决海量数据中元素查询,去重.以及排序等问题.这里对海量数据场景的强调,似乎暗示了这 ...
- AtCoder Beginner Contest 203 (A~D,玄学二分场)
补题链接:Here A - Chinchirorin 给出 \(a,b,c\) 三个正整数,现请打印各种情况的答案: \(a=b=c\) ,输出一个即可 \(a = b\ and\ a != c\) ...
- M-SOLUTIONS Programming Contest 2020 游记 (AB水题,CD模拟,E题DFS)
A - Kyu in AtCoder 水题 B - Magic 2 题意很好理解,但写的时候注意一下边界 void solve() { int a, b, c, k; cin >> a & ...
- Codeforces Round #679 (Div. 2, based on Technocup 2021 Elimination Round 1) (个人题解)
1434A. Finding Sasuke // Author : RioTian // Time : 20/10/25 #include <bits/stdc++.h> using na ...
- 第17场-快乐AC赛
A - 看我,看我,我最简单了 POJ - 2387 这道题是以前记录过的最短路板子题,然而我还是脑抽用Floyd交了一发 解题报告:https://www.cnblogs.com/RioTian/p ...
- 阿里云 Serverless 应用引擎(SAE)2
8月7日,阿里云 Serverless 应用引擎(SAE)2.0正式公测上线!全面升级后的SAE 2.0具备极简体验.标准开放.极致弹性三大优势,应用冷启动全面提效,秒级完成创建发布应用,应用成本下降 ...
- shell脚本(16)-awk命令
文档目录 一.awk介绍 二.awk基本用法 1.awk对字段(列)的提取: 2.awk对记录(行)的提取: 3.awk对字符串提取: 4.awk程序的优先级: 三.awk高级用法 1.awk定义数组 ...