Go 监控告警入门 Opentelemetry
前言
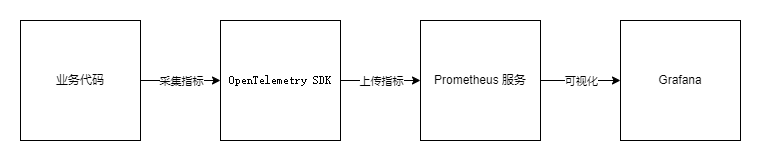
Opentelemetry
分布式链路跟踪( Distributed Tracing )的概念最早是由 Google 提出来的,发展至今技术已经比较成熟,也是有一些协议标准可以参考。目前在 Tracing 技术这块比较有影响力的是两大开源技术框架:Netflix 公司开源的 OpenTracing 和 Google 开源的 OpenCensus。两大框架都拥有比较高的开发者群体。为形成统一的技术标准,两大框架最终磨合成立了 OpenTelemetry 项目,简称 otel。otel 有链路追踪和监控告警两大块,关于监控告警,可以查看另一篇文章:Go 链路追踪入门 Opentelemetry
Prometheus
Prometheus 源自 SoundCloud,拥有一整套开源系统监控和警报工具包,是支持 OpenTelemetry 的系统之一,是 CNCF 的第二个项目。
Grafana
Grafana 是一个开源的分析和可视化平台,它允许你查询、可视化和警报来自各种数据源的数据。它提供了一个用户友好的界面,用于创建和共享仪表板、图表和警报。Grafana 支持广泛的数据源,其中就包括 Prometheus
基础概念
这里为了简单入门,尽量简单的介绍一些抽象概念,结合着代码理解,如果不能理解也没关系,代码写着写着自然就明白了:
Meter Provider
用于接口化管理全局的 Meter 创建,相当于全局的监控指标管理工厂。
Meter
用于接口化创建并管理全局的 Instrument,不同的 Meter 可以看做是不同的程序组件。
Instrument
用于管理不同组件下的各个不同类型的指标,例如 http.server.request.total
Measurements
对应指标上报的具体的 DataPoint 指标数据,是一系列的数值项。
Metric Reader
用于实现对指标的数据流读取,内部定义了具体操作指标的数据结构。OpenTelemetry 官方社区提供了多种灵活的 Reader 实现,例如 PeridRader、ManualReader 等。
Metric ExporterExporter 用于暴露本地指标到对应的第三方厂商,例如:Promtheus、Zipkin 等。
指标类型
OpenTelemetry metrics 有许多不同指标类型,可以把它想象成类似于 int, float 这种的变量类型:
Counter:只增不减的指标,比如 http 请求总数,字节大小;
Asynchronous Counter:异步 Counter;
UpDownCounter:可增可减的指标,比如 http 活动连接数;
Asynchronous UpDownCounter:异步 Counter;
Gauge:可增可减的指标,瞬时计量的值,比如 CPU 使用,它是异步的;
Histogram:分组聚合指标,这个较为难以理解一些,可以移步此处查看,当然,后文也会有一个详细的例子来使用它。
实战:采集指标
废话了一堆,终于可以实战了。我们先以 http 请求总数为例来走一遍整个采集指标流程。安装扩展:
go get github.com/prometheus/client_golang
go get go.opentelemetry.io/otel/exporters/prometheus
go get go.opentelemetry.io/otel/metric
go get go.opentelemetry.io/otel/sdk/metric打开 main.go,编写以下代码:
package main
import (
"context"
"fmt"
"log"
"net/http"
"os"
"os/signal"
"github.com/prometheus/client_golang/prometheus/promhttp"
"go.opentelemetry.io/otel/exporters/prometheus"
api "go.opentelemetry.io/otel/metric"
"go.opentelemetry.io/otel/sdk/metric"
)
const meterName = "oldme_prometheus_testing"
var (
requestHelloCounter api.Int64Counter
)
func main() {
ctx := context.Background()
// 创建 prometheus 导出器
exporter, err := prometheus.New()
if err != nil {
log.Fatal(err)
}
// 创建 meter
provider := metric.NewMeterProvider(metric.WithReader(exporter))
meter := provider.Meter(meterName)
// 创建 counter 指标类型
requestHelloCounter, err = meter.Int64Counter("requests_hello_total")
if err != nil {
log.Fatal(err)
}
go serveMetrics()
ctx, _ = signal.NotifyContext(ctx, os.Interrupt)
<-ctx.Done()
}
func serveMetrics() {
log.Printf("serving metrics at localhost:2223/metrics")
http.Handle("/metrics", promhttp.Handler())
http.Handle("/index", http.HandlerFunc(func(w http.ResponseWriter, r *http.Request) {
// 记录 counter 指标
requestHelloCounter.Add(r.Context(), 1)
_, _ = w.Write([]byte("Hello, Otel!"))
}))
err := http.ListenAndServe(":2223", nil) //nolint:gosec // Ignoring G114: Use of net/http serve function that has no support for setting timeouts.
if err != nil {
fmt.Printf("error serving http: %v", err)
return
}
}在我们的代码中,我们定义一个名字为 requests_hello_total 的 Int64Counter 指标类型,Int64Counter 代表这是一个只增不减的 int64 数值,用作记录请求总数正好合适。运行我们的程序,如果不出错的话,访问 http://localhost:2223/index 可以看到 Hello, Otel!。并且我们访问 http://localhost:2223/metrics 可以看到指标数据:

这里数据还没有进行可视化,我们先把流程走通,多访问几次 http://localhost:2223/index 可以看到 requests_hello_total 会增加:
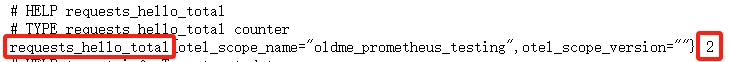
Histogram
接下来我们采集一下 Histogram 指标,统计在 0.1, 0.2, 0.5, 1, 2, 5 秒以内的 http 请求数,在 main.go 中加上相关代码,可以直接复制过去:
package main
import (
"context"
"fmt"
"log"
"math/rand"
"net/http"
"os"
"os/signal"
"time"
"github.com/prometheus/client_golang/prometheus/promhttp"
"go.opentelemetry.io/otel/exporters/prometheus"
api "go.opentelemetry.io/otel/metric"
"go.opentelemetry.io/otel/sdk/metric"
)
const meterName = "oldme_prometheus_testing"
var (
requestHelloCounter api.Int64Counter
requestDurationHistogram api.Float64Histogram
)
func main() {
ctx := context.Background()
// 创建 prometheus 导出器
exporter, err := prometheus.New()
if err != nil {
log.Fatal(err)
}
// 创建 meter
provider := metric.NewMeterProvider(metric.WithReader(exporter))
meter := provider.Meter(meterName)
// 创建 counter 指标类型
requestHelloCounter, err = meter.Int64Counter("requests_hello_total")
if err != nil {
log.Fatal(err)
}
// 创建 Histogram 指标类型
requestDurationHistogram, err = meter.Float64Histogram(
"request_hello_duration_seconds",
api.WithDescription("记录 Hello 请求的耗时统计"),
api.WithExplicitBucketBoundaries(0.1, 0.2, 0.5, 1, 2, 5),
)
if err != nil {
log.Fatal(err)
}
go serveMetrics()
go goroutineMock()
ctx, _ = signal.NotifyContext(ctx, os.Interrupt)
<-ctx.Done()
}
func serveMetrics() {
log.Printf("serving metrics at localhost:2223/metrics")
http.Handle("/metrics", promhttp.Handler())
http.Handle("/index", http.HandlerFunc(func(w http.ResponseWriter, r *http.Request) {
// 记录 counter 指标
requestHelloCounter.Add(r.Context(), 1)
// 计算请求处理时间
startTime := time.Now()
// 模拟请求处理时间
time.Sleep(time.Duration(rand.Intn(3)) * time.Second)
defer func() {
duration := time.Since(startTime).Seconds()
requestDurationHistogram.Record(r.Context(), duration)
}()
_, _ = w.Write([]byte("Hello, Otel!"))
}))
err := http.ListenAndServe(":2223", nil) //nolint:gosec // Ignoring G114: Use of net/http serve function that has no support for setting timeouts.
if err != nil {
fmt.Printf("error serving http: %v", err)
return
}
}
// 随机模拟若干个协程
func goroutineMock() {
for {
go func() {
// 等待若干秒
var s = time.Duration(rand.Intn(10))
time.Sleep(s * time.Second)
}()
time.Sleep(1 * time.Millisecond)
}
}走到这里,代码层面结束了,已经成功一半了,代码开源在 Github。之后我们就可以安装 Prometheus 服务端和 Grafana 来进行数据可视化。
安装 Prometheus
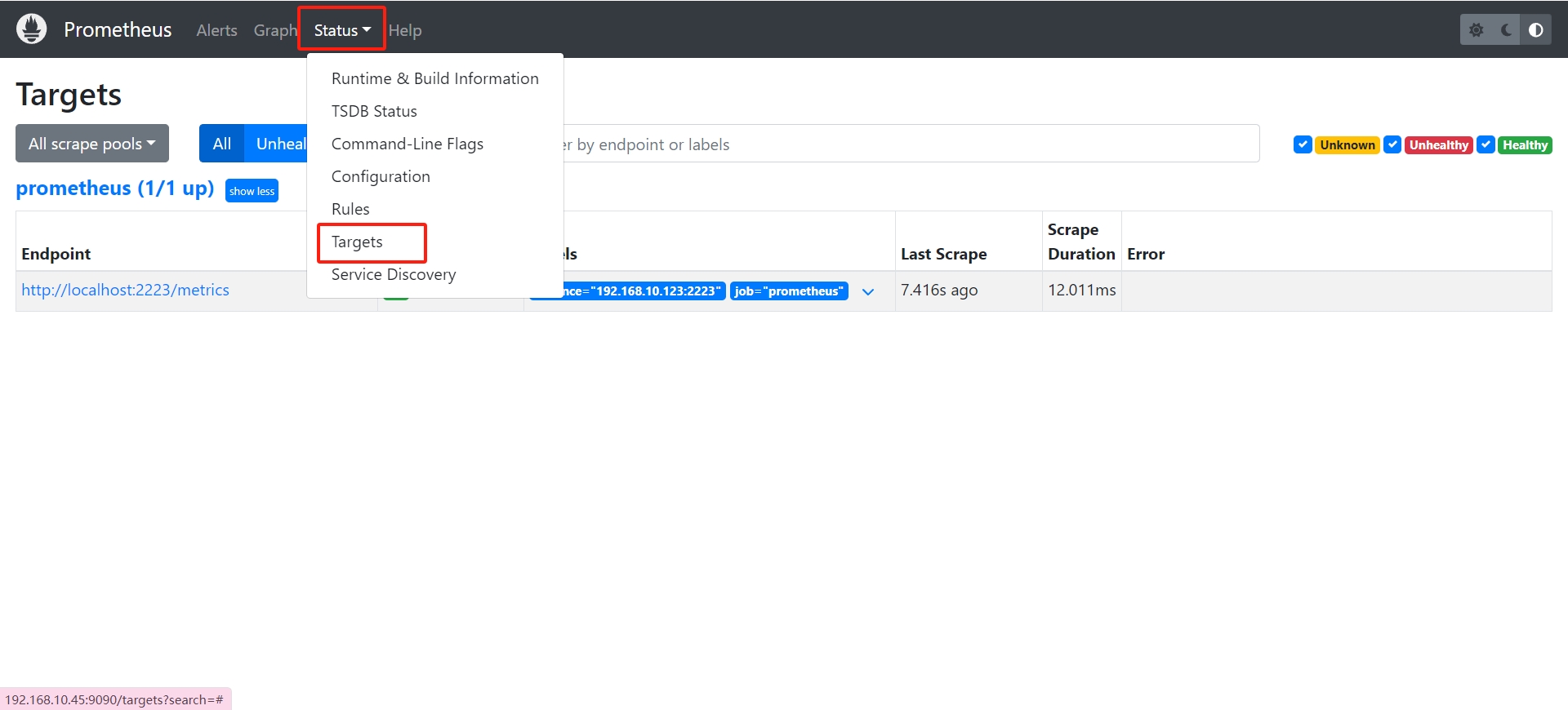
Prometheus 有多种安装方式,我这里依旧采用 Docker 安装,当然,你也可以使用其他方式安装,具体安装方式可以参考其他文章,后续 Grafana 同理,不在赘述,在 Prometheus.yml 中填写 targets 我们的地址:
scrape_configs:
- job_name: "prometheus"
static_configs:
- targets: ["localhost:2223"]Prometheus 会自动去 {{target}}/metrics 中拉取我们的指标。之后在浏览器打开 Promethues 的地址,例如我的是:http://localhost:9090,如果全部正常的话可以在 status:targets 中看见我们的指标:
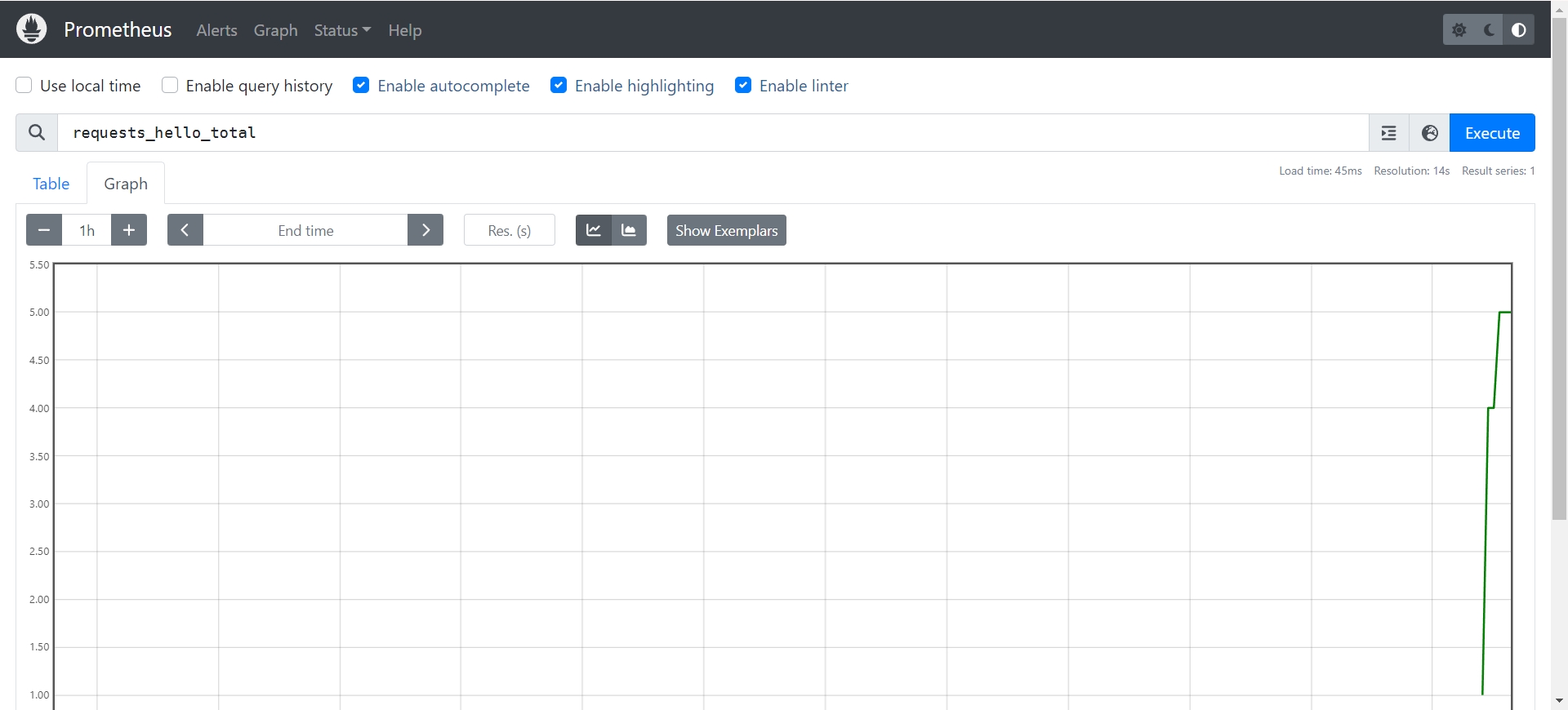
在 Promethues 的首页查询 requests_hello_total 指标可以看到可视化的图表:
安装 Grafana
我的 Grafana 安装好了,登录进去后是这样的(我更改后默认颜色):
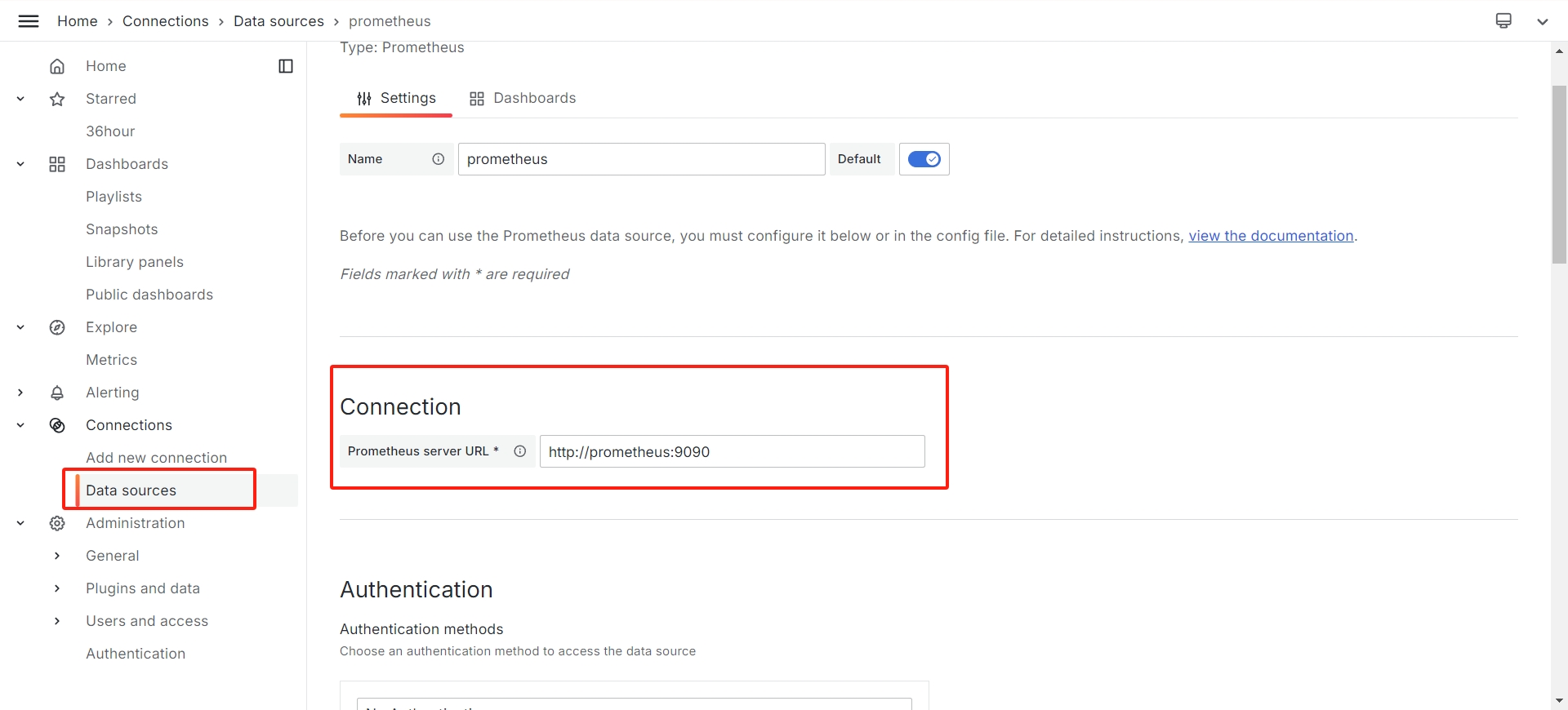
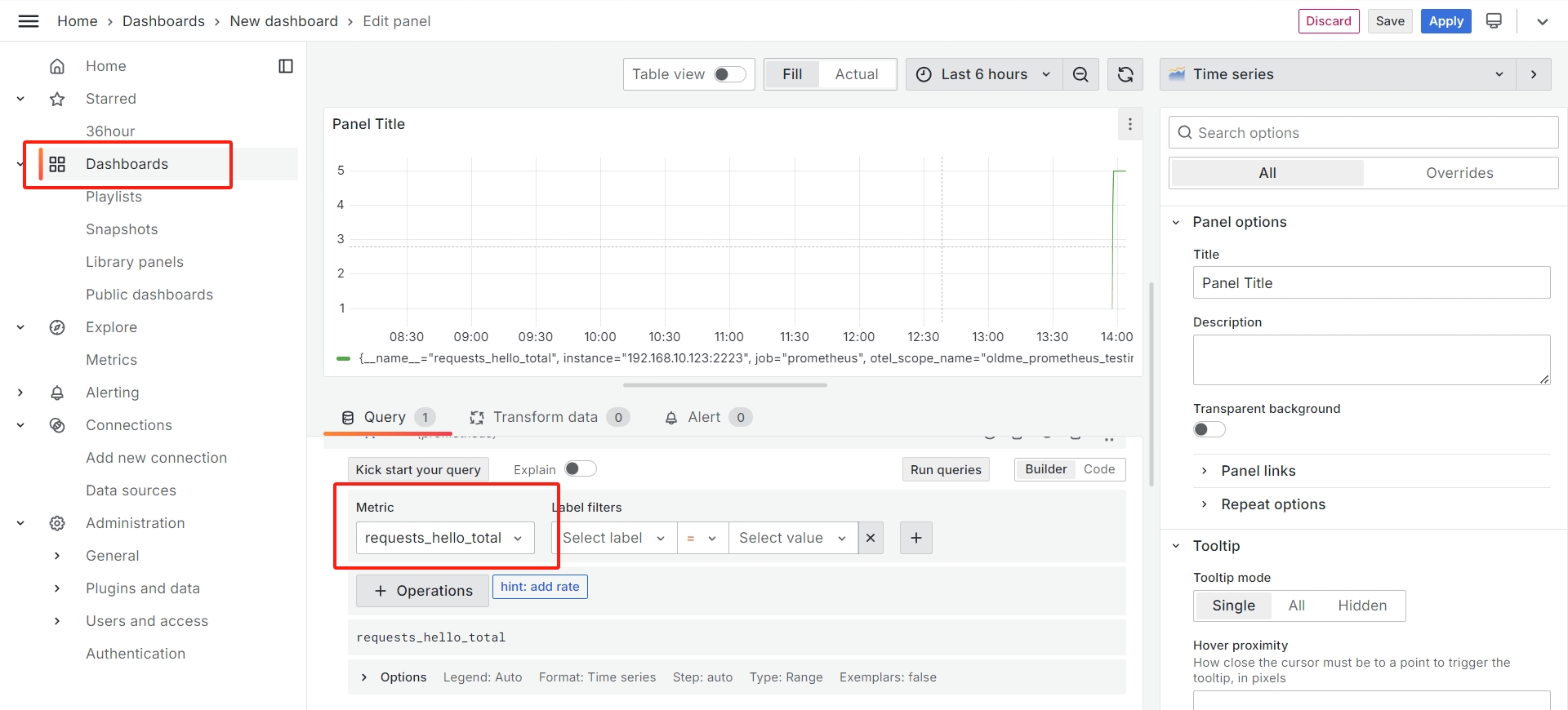
在 Data source 中添加 Prometheus 服务器,然后在 Dashboard 中添加我们想要监控的指标,即可看到更美观的图表:
Go 监控告警入门 Opentelemetry的更多相关文章
- Prometheus监控告警浅析
前言 最近有个新项目需要搞一套完整的监控告警系统,我们使用了开源监控告警系统Prometheus:其功能强大,可以很方便对其进行扩展,并且可以安装和使用简单:本文首先介绍Prometheus的整个监控 ...
- zookeeper监控告警
一.ZooKeeper简介 ZooKeeper作为分布式系统中重要的组件,目前在业界使用越来越广泛,ZooKeeper的使用场景非常多,以下是几种典型的应用场景: l 数据发布与订阅(配置中心) l ...
- linux服务器内存、根目录使用率、某进程的监控告警脚本
脚本内容如下 #!/bin/bash #磁盘超过百分之80发送邮件告警 DISK_USED=`df -T |sed -n "2p" |awk '{print ($4/$3)*100 ...
- Execute to Parse %: 29.76,数据库硬解析过高,监控告警提示数据库硬解析比例过低
客户反馈,Oracle重启库操作后,监控告警出现pin比例低于25% 根据Oracle体系结构的理解,重启库后,硬解析及buffer命中率肯定有一段时间低. 生成不同时段的AWR报告:不要生成rac ...
- 24 Zabbix系统配置日志监控告警--关键字触发
点击返回:自学Zabbix之路 点击返回:自学Zabbix4.0之路 点击返回:自学zabbix集锦 24 Zabbix系统配置日志监控告警--关键字触发 trapper是被监控主机主动发送数据给za ...
- zabbix监控告警Received empty response from Zabbix Agent Assuming that agent dropped connection
zabbix监控告警Received empty response from Zabbix Agent Assuming that agent dropped connection错误 查看zabbi ...
- (转)Linux磁盘空间监控告警 && Linux磁盘管理
Linux磁盘空间监控告警 http://blog.csdn.net/github_39069288/article/details/73478784-----------Linux磁盘管理 原文:h ...
- SQL Server Alwayson架构下 服务器 各虚拟IP漂移监控告警的功能实现 -2(虚拟IP视角)
1.需求描述 我们知道Windows Cluster 都是多节点的,当虚拟IP漂移的时候,一般都是从一个节点漂移到另外一个节点.如果可以及时捕捉到旧节点信息是什么.新节点信息是什么对我们提供高可用的数 ...
- 分布式监控告警平台Centreon快速使用
一. Centreon概述 Centreon是一款功能强大的分布式IT监控系统,它通过第三方组件可以实现对网络.操作系统和应用程序的监控:首先,它是开源的,我们可以免费使用它:其次,它的底层采用nag ...
- MaxCompute按量计费计算任务消费监控告警
MaxCompute 按量计费资源为弹性伸缩资源,对于计算任务,按任务需求提供所需资源,对资源使用无限制,同时MaxCompute按量计费的账单为天账单,即当天消费需要第二天才出账,因此,有必要对计算 ...
随机推荐
- 08-Python迭代器与生成器
迭代器 什么是迭代器 迭代是Python最强大的功能之一,是访问序列中元素的一种方式. 迭代器是一个可以记住遍历的位置的对象. 迭代器对象从集合的第一个元素开始访问,直到所有的元素被访问完结束.迭代器 ...
- Project Euler 1~10 野蛮题解
这些题都比较简单就不贴代码和做法了 23333333 具体到做法就是枚举暴力,这十题中可能难一点地方的就是筛质数表,可以学习一下 Eratosthenes 筛法或者是欧拉筛. 如果您不会前十题建议好好 ...
- 使用Scrcpy 在电脑显示手机画面并控制安卓设备
使用Scrcpy 显示手机画面并控制手机 原文(有删改):https://www.iplaysoft.com/scrcpy.html 背景 本文适用于安卓开发人员,不针对普通安卓手机用户. 在安卓开发 ...
- 关于Android开机动画调试的一点小小的经验
格式要求: 开机动画图片既可以是jpg文件,也可以是png文件,只是一定要按顺序命名.文件名命名的国际惯例是五位数,即:00000.00001. 00002--也可以是文件夹名称+下划线+序数,即:p ...
- 如何在Zynq-7000上烧写PL Image
由 技术编辑archive1 于 星期六, 06/28/2014 - 10:05 发表 作者:hqin, Xilinx处理器专家FAE 在Zynq-7000上编程PL大致有3种方法: 用FSBL,将b ...
- C语言:不定长结构体的实现方式
需求 有时候,我们会遇到一些情况:数据前部分相同,但是后部分长度不固定:数据格式相似,只是尾缀的长度不同,例如某些数据包,需要不定长度. 为了能够同时使用上不同长度的数据.可以用以下的方式实现. 方案 ...
- Canvas绘制圆角图片
效果图: 思路: 先绘制一个圆角长方形 在画布中裁剪下来 在圆角长方形内绘制图片 图片四个角超出圆角长方形的区域被隐藏 具体代码: <!DOCTYPE html> <html lan ...
- debian11 简单搭建go环境
简单环境,目前仅支持单版本go,后续可以考虑直接把go环境放到docker中或podman中,这样每个容器都是一套go版本. 新建文件夹目录 # 我直接用的root账户 cd /root mkdir ...
- 说说你对 SPA 单页面的理解,它的优缺点分别是什么?
SPA( single-page application )仅在 Web 页面初始化时加载相应的 HTML.JavaScript 和 CSS. 一旦页> 面加载完成,SPA 不会因为用户的操作而 ...
- Mac 版本10.15.4 安装 telnel工具
下载脚本 mac新版本安装telnel发生的变化,进入下面的链接,右键另存为,保存到桌面 https://raw.githubusercontent.com/Homebrew/install/mast ...