python爬虫---从零开始(一)初识爬虫
我们开始来谈谈python的爬虫。
1,什么是爬虫:
网络爬虫是一种按照一定的规则,自动地抓取万维网信息的程序或者脚本。另外一些不常使用的名字还有蚂蚁、自动索引、模拟程序或者蠕虫。互联网犹如一个大蜘蛛网,我们的爬虫就犹如一个蜘蛛,当在互联网遇到所需要的资源,我们就会爬取下来,即为爬虫是一个请求网站并且提取数据的自动化程序。
2,下面我们来提到两个名词:
1)请求,request即为我们的请求,当我们在浏览器内输入网址,敲击回车时,这时浏览器就会发送消息给该网址所在的服务器,这个过程叫做HTTP Request
2)响应,response即为我们的响应,服务器在接收到浏览器发送的消息后,能够根据浏览器发送消息的内容做出相应的处理,然后把消息回传给浏览器。这个过程就做HTTP Response。浏览器收到服务器的Response信息后,会对信息进行处理,然后展示。
3,Request中包含什么?
1)请求方式,请求方式主要包含get,post,另外还有put,head,delete,options等,但我们常用的、常见的还是get和post请求。
get请求:get请求方式所有的参数都包含在URL地址里,get请求可以直接在浏览器地址栏内输入URL地址,然后直接访问。
post请求:比get方式多包含一个formdata数据,且参数没有在URL地址内。不可以直接在地址栏访问,需要构造一个form表单,进行提交访问。
同时post请求所有参数不显示地址栏内,相对于get请求来说更安全。
2)请求URL,URL全称统一资源定位符,如一个网页文档、一张图片、一个视频等都可以用URL唯一来确定。
3)请求头,包含请求时的头部信息,如User-Agent、Host、Cookies等信息,请求头是一个很重要的参数,在很多爬虫里需要设置请求头信息,
一般权限验证,浏览器类型等信息,如下图所示:

4)请求体,请求时额外携带的数据,如表单提交时的表单数据,一般来说get方式请求时,都没有请求体。
4,Response中包含什么?
1)响应状态,有多种响应状态,如200代表成功,404找不到页面,500服务器错误
扩展:
-1xx :报告的 -请求被接收到,继续处理
-2xx :成功 - 被成功地接收(received),理解(understood),接受(accepted)的动作 。
-3xx :重发 - 为了完成请求必须采取进一步的动作。
-4xx :客户端出错 - 请求包括错的语法或不能被满足。
-5xx :服务器出错 - 服务器无法完成显然有效的请求。
2)响应头,如内容类型、内容长度、服务器信息、设置Cookie等等信息。如图所示:
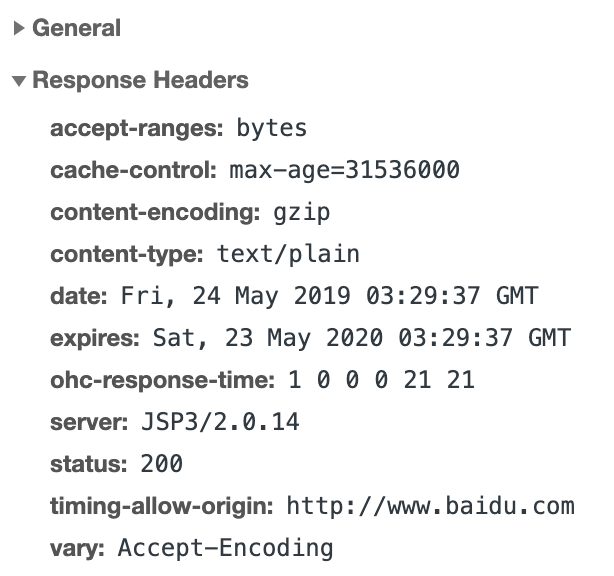
3)响应体,最主要的部分,包含了请求资源的内容,如网页HTML,图片,二进制数据(视频,图片等)等信息。
我们爬取的数据大部分就是从这个部分获取的
5,我们所需要的环境和资源
1)python环境,最好是python3,python2在2020年就不再维护了,语法还是有一定差异的,我建议使用python3。
2)redis,mongo分关系型数据库,安装过程自行百度。(后期会有专门的博客来说明讲解非关系型数据库)。
3)scrapy环境,pip install scrapy即可安装。
4)Urllib库,Requests库,BeautifulSoup库,PyQuery,Selenium和与其相关联的环境配置(后面我们会逐个来说明每一个库和其操作使用方法)。
总结:爬虫是一个请求网站并且提取数据的自动化程序。有的是通过原生html标签就可以获取到数据,则有的需要通过解析ajax请求来取得数据。
第一次写博客,还是有点点紧张,我也是现学现卖的,欢迎斧正。谢谢
python爬虫---从零开始(一)初识爬虫的更多相关文章
- python爬虫之路——初识爬虫原理
爬虫主要做两件事 ①模拟计算机对服务器发起Request请求 ②接收服务器端的Response内容并解析,提取所需的信息 互联网页面错综复杂,一次请求不能获取全部信息.就需要设计爬虫的流程. 本书主要 ...
- python爬虫系列之初识爬虫
前言 我们这里主要是利用requests模块和bs4模块进行简单的爬虫的讲解,让大家可以对爬虫有了初步的认识,我们通过爬几个简单网站,让大家循序渐进的掌握爬虫的基础知识,做网络爬虫还是需要基本的前端的 ...
- python爬虫之路——初识爬虫三大库,requests,lxml,beautiful.
三大库:requests,lxml,beautifulSoup. Request库作用:请求网站获取网页数据. get()的基本使用方法 #导入库 import requests #向网站发送请求,获 ...
- [转]让你从零开始学会写爬虫的5个教程(Python)
让你从零开始学会写爬虫的5个教程(Python) 写爬虫总是非常吸引IT学习者,毕竟光听起来就很酷炫极客,我也知道很多人学完基础知识之后,第一个项目开发就是自己写一个爬虫玩玩. 其实懂了之后,写个 ...
- Python 爬虫3——第一个爬虫脚本的创建
在进行真正的爬虫工程创建之前,我们先要明确我们所要操作的对象是什么?完成所有操作之后要获取到的数据或信息是什么? 首先是第一个问题:操作对象,爬虫全称是网络爬虫,顾名思义,它所操作的对象当然就是网页, ...
- python Cmd实例之网络爬虫应用
python Cmd实例之网络爬虫应用 标签(空格分隔): python Cmd 爬虫 废话少说,直接上代码 # encoding=utf-8 import os import multiproces ...
- Python爬虫与数据分析之爬虫技能:urlib库、xpath选择器、正则表达式
专栏目录: Python爬虫与数据分析之python教学视频.python源码分享,python Python爬虫与数据分析之基础教程:Python的语法.字典.元组.列表 Python爬虫与数据分析 ...
- python爬虫随笔(2)—启动爬虫与xpath
启动爬虫 在上一节中,我们已经创建好了我们的scrapy项目,看着这一大堆文件,想必很多人都会一脸懵逼,我们应该怎么启动这个爬虫呢? 既然我们采用cmd命令创建了scrapy爬虫,那就得有始有终有逼格 ...
- 2.Python爬虫入门二之爬虫基础了解
1.什么是爬虫 爬虫,即网络爬虫,大家可以理解为在网络上爬行的一直蜘蛛,互联网就比作一张大网,而爬虫便是在这张网上爬来爬去的蜘蛛咯,如果它遇到资源,那么它就会抓取下来.想抓取什么?这个由你来控制它咯. ...
- Python爬虫进阶一之爬虫框架概述
综述 爬虫入门之后,我们有两条路可以走. 一个是继续深入学习,以及关于设计模式的一些知识,强化Python相关知识,自己动手造轮子,继续为自己的爬虫增加分布式,多线程等功能扩展.另一条路便是学习一些优 ...
随机推荐
- SVN进行代码的托管
svn 使用的是集中服务器 就是只有一个服务器的意思 git 是分布式服务器 服务器: 存储客户端上传的源代码. 可以在Windows上通过安装 Visual SVN Sever . 客户端: 上 ...
- list转json的一些问题
利用JSONArray转换list 定义的model: package com.yds.model; import java.util.Date; public class DeviceHistory ...
- 开挂的map
转自:http://blog.csdn.net/sunshinewave/article/details/8067862 #include<iostream> #include<ma ...
- IT兄弟连 Java Web教程 Tomcat
本文采用的Tomcat服务器版本是Tomcat8.5版本,Tomcat8.5支持Servlet3.1.JSP2.3以及EL3.0规范.并且Tomcat8.5版本对JDK8的支持比Tomcat8更加全面 ...
- C#读取大文件
有些时候需要读取文件,小文件的时候效率的影响可以忽略,但是当文件上M,上G的时候,这个时候,效率问题就非常重要了,下面将对一个3G的文件,用C#的方式读取,对比效率的影响. 1. FileStream ...
- 简述网站、B/S架构与C/S架构
一.什么是网站? 定义:网站是指在因特网上根据一定的规则,使用HTML等工具制作的用于展示特定内容相关网页的集合. 简单地说,网站是一种沟通工具(或者说是一种软件——建设网站也是软件开发的一种),我们 ...
- useradd user 错误解决
今天给安装Sequoiadb 软体时,出现添加用户和组失败,显示错误: cannot lock /et/passwd; try again later. 在网上查了一下,说是/etc/passwd 文 ...
- 各大版本idea永久破解激活方法
文章转载自:https://www.jiweichengzhu.com/article/a45902a1d7284c6291fe32a4a199e65c 如果还有问题,加群交流:686430774(就 ...
- 7天学完Java基础之5/7
接口 接口就是一种公共的规范标准 是一种引用数据类型 定义格式 public interface 接口名称{} java7 中接口可以包含常量,抽象方法:Java8 还可以额外包含默认方法,静态方法: ...
- luogu P1095守望者的逃离【dp】By cellur925
题目传送门 考虑dp,设f[i]表示到第i时间,能到达的最远距离.因为题目涉及了三种操作:1,补血消耗魔法值:2, 等待增加魔法值:3,直接向前走.而1,3和2,3的操作是可以同时进行没有冲突的,所以 ...