(转) 淘淘商城系列——Redis集群的搭建
http://blog.csdn.net/yerenyuan_pku/article/details/72860432
本文我将带领大家如何搭建Redis集群。首先说一下,为何要搭建Redis集群。Redis是在内存中保存数据的,而我们的电脑一般内存都不大,这也就意味着Redis不适合存储大数据,适合存储大数据的是Hadoop生态系统的Hbase或者是MogoDB。Redis更适合处理高并发,一台设备的存储能力是很有限的,但是多台设备协同合作,就可以让内存增大很多倍,这就需要用到集群。
redis-cluster架构图
我们来看一下redis-cluster架构图,如下图所示。可以看到Redis集群是没有统一入口的,客户端连集群中的哪台设备都行,集群中各个设备之间都定时进行交互,以便知道节点是否还正常工作。 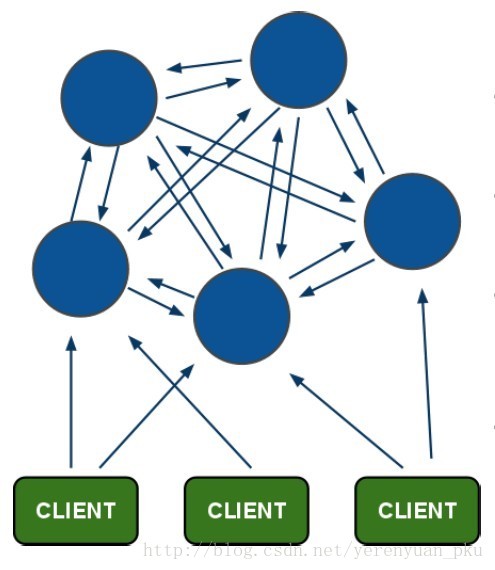
我按照我个人的理解说一下集群架构中的一些细节:
- 上图中的蓝圈表示的都是节点,每个节点和节点之间使用PING-PONG机制来相互通信,内部使用二进制协议优化传输速度和带宽。
- 在整个集群内部,没有一个代理层,也就是说集群中没有哪个节点是入口。也即客户端要连集群的话,连集群中的哪个节点都行,只要连上其中一个,那么这时你就可以通过这个节点访问集群中任意一个节点了。
- 我们现在集群中有这么多节点,节点上面存储的数据都是一样的吗?如果存储的数据要是一样的话,那这个集群其实意义并不太大,顶多也算是一个储备。Redis的所有数据都是保存到内存中的,内存能放的东西其实并不太多,如果数据量很大的话,那么这时候一台服务器就会存不下,你就算加多少个备份机也不能解决该问题。而你要想解决这个存储容量的问题,那么需要保证每个节点上面存放的数据不一样。如果其中一个节点挂了呢?整个集群中的这些节点数据就不完整了,如果有其中任意一个节点挂了,那么集群就挂了,你要想让它不挂,每一个节点就应有一个备份机,如果主节点挂了,那么备份机就顶上来。那么如何判断一个节点挂了呢?——节点挂了是通过集群中超过半数的节点投票(投票机制)决定的,如果超过半数的节点认为这个节点它挂了,那么它就挂了,没挂也挂。说得更细致一点,Redis集群是有容错投票机制的,如下图所示。浅黄色的那个节点向红色的那个节点发出ping命令,红色节点没有回应,这时浅黄色节点便认为这个节点可能挂掉了,它会投上一票,不过这时只是疑问,所以浅黄色节点画了一个”?”,然后浅黄色节点告诉别的节点说这个红色的节点可能挂掉了,第二个节点去尝试和这个红色节点联系,发现也ping不同,于是第二个节点也认为这个红色节点挂掉了,第二个节点也投上一票,接着第三个节点去和红色节点联系,也联系不上,于是也投上一票,这样便三票了。Redis的容错投票机制是集群中过半数的节点认为某个节点挂了,那么就认定这个节点挂了。这时要看这个红色节点还有没有备用节点,如果没有备用节点了,那么整个集群将停止对外提供服务,如果有备份节点,那么会将备份节点扶正,继续对外提供服务。

- 我们要把数据分散存储到不同的节点,这时我们如何确定我的这个数据存储到哪个节点上呢?这个时候Redis集群引入另外一个概念,就是槽这个概念,槽的数量是固定的,一共16384个槽。我们先把这个槽分配到不同节点上,每个节点分配一定数量的槽,反正加起来一共16384个槽。当我们要往里面存储某个key的时候,先计算一下这个key它应该在哪个槽上,计算完了之后,这个槽分配到哪个服务器上,我们是知道的。所以,我们就找到对应的服务器,然后把key存到该服务器上就可以了。
Redis集群内置了16384个哈希槽,当需要在Redis集群中放置一个key-value时,Redis先对key使用crc16算法算出一个结果,然后把结果对16384求余数,这样每个key都会对应一个编号在0-16383之间的哈希槽,redis会根据节点数量大致均等的将哈希映射到不同的节点。我们以下图为例,我们把这16384个哈希槽分配到三个Server上,假如Server1上卡槽是0-5000,Server2上卡槽是5001-10000,Server3上卡槽是10001-16383。假如我们要保存字符串”Hello”,而”Hello”经过crc16算法再对16384求余后是500,很显然应该存到Server1上,假如要存储的字符串”Hello2”经过crc16算法再对16384求余后是11500,那么很显然应该存到Server3上,同理,”Hello3”、”Hello1”被分别存到Server2和Server1上了。也就是说每个Server其实存储的内容是不一样的,这也就是为何某个节点挂掉后如果没有备用节点的话,整个集群都会挂掉,因为数据不全了啊。另外,关于每个服务器上卡槽的分布数量可以根据服务器的性能来定,性能好的可以多分配些卡槽,这样在它上面存储的内容也就多了。
Redis集群的搭建
下面我们来搭建Redis集群,由于集群的容错机制是超过半数的节点认为某节点挂掉就确认挂掉,因此我们搭建的集群最好是奇数台(>=3)。又由于为了高可用性,每个节点需要有备份节点,因此我们搭建一个Redis集群至少要有6台虚拟机。这样的话,我们需要6台虚拟机,我们的本机又确实跑不了6台虚拟机,但我们还想搭建Redis集群,那怎么办呢?其实很简单,只能搭建伪分布式集群了,可想而知并不是真正的集群。具体做法是可以使用一台虚拟机运行6个Redis实例,每个Redis实例需要运行在不同的端口,这里我假设为7001-7006这6个端口。
在一台虚拟机上创建6个Redis实例
我相信大家都知道了如何在一台虚拟机上创建一个Redis实例,如果读者还不会,可以通过淘淘商城系列——Redis的安装我的这篇文章进行学习。
首先我们在/usr/local目录下创建一个redis-cluster目录,如下图所示。 
接着我们将redis/bin目录复制到redis-cluster/redis01目录下,如果redis-cluster目录下没有redis01这个目录的,则创建该目录,如下图所示。 
紧接着我们进入redis-cluster/redis01目录中,并使用ll命令查看一下该目录。 
可以发现Redis实例里面有一些持久化文件,所以我们要把这些持久化文件删掉,否则,这个节点中有数据的话,集群是搭不起来的。 
接下来,我们通过redis.conf配置文件来修改redis01实例的运行端口号,将其端口号置为7001,还要记得将redis.conf配置文件中的cluster-enabled设置为yes哟! 
redis01实例的配置文件修改之后,我们只须在redis-cluster目录下复制5个这样的Redis实例就可以了,如下图所示。 
现在我们有6个Redis实例了,需要把每个Redis实例运行在不同的端口上。redis01这个实例的端口号已经被改为7001了,接下来就是修改其他5个Redis实例的运行端口号了。具体做法是将redis02实例的端口号置为7002,redis03实例的端口号置为7003,redis04实例的端口号置为7004,redis05实例的端口号置为7005,redis06实例的端口号置为7006。
启动每个Redis实例
我们在一台虚拟机上创建好6个Redis实例之后,就需要把每个Redis实例启动起来。如果想启动每个Redis实例的话,不必每个实例一个个启动,这样太麻烦了,我们可以写个批处理程序来把它们一下子启动起来。在redis-cluster目录下使用vim start-all.sh命令来创建一个批处理文件,文件内容为:
cd redis01
./redis-server redis.conf
cd ..
cd redis02
./redis-server redis.conf
cd ..
cd redis03
./redis-server redis.conf
cd ..
cd redis04
./redis-server redis.conf
cd ..
cd redis05
./redis-server redis.conf
cd ..
cd redis06
./redis-server redis.conf
cd ..保存完该文件之后,使用ll命令查看一下redis-cluster目录,可以发现start-all.sh文件,如下图所示。 
但是这个批处理程序是不能运行的,所以你使用chmod u+x start-all.sh命令需要改一下它的权限,这样我们就可以使用./start-all.sh命令来启动每个Redis实例了。 
如何知道每个Redis实例启动起来了呢?可使用ps aux|grep redis命令来查看每一个Redis实例的启动进程,如下图所示。 
安装ruby环境
我们是使用ruby脚本来搭建集群的,所以需要安装ruby的运行环境。具体做法是在联网的情况下输入yum install ruby命令来安装ruby的运行环境,如下图所示。 
安装完ruby之后,我们还需要安装rubygems(也就是ruby第三方包管理工具),使用命令yum install rubygems,如下图所示。 
安装完ruby和rubygems之后,我们需要安装ruby脚本运行所需要的一个包redis-3.0.0.gem,下面是我所下载的redis-3.0.0.gem包。 
大家下载完后要上传到虚拟机上,怎样知道我们真的上传上去了呢?在当前用户主目录(即root)下使用ll命令查看一下该目录即可。 
下面来安装这个第三方包,输入gem install redis-3.0.0.gem命令然后回车,如下图所示。 
使用ruby脚本搭建集群
上面做了那么多准备其实是为一个脚本文件(redis-trib.rb)服务的,这个脚本文件的位置在/root/redis-3.0.0/src目录下,如下图所示。 
为方便管理,我们把这个脚本文件复制到/usr/local/redis-cluster目录下,然后进入到该目录中,使用ll命令查看一下该目录是否有redis-trib.rb脚本文件,如下图所示。 
下面正式开始搭建集群,我们使用如下命令来搭建集群。
./redis-trib.rb create --replicas 1 192.168.25.128:7001 192.168.25.128:7002 192.168.25.128:7003 192.168.25.128:7004 192.168.25.128:7005 192.168.25.128:7006命令中–replicas是指定每个节点备份的节点的数量,我们现在是每个节点备份一个,因此输入1。 
从上图可以看到从主节点是随机组成的,主节点是192.168.25.128:7001、192.168.25.128:7002、192.168.25.128:7003这三台设备,192.168.25.128:7004、192.168.25.128:7005、192.168.25.128:7006这三台是备用节点。Adding replica 192.168.25.128:7004 to 192.168.25.128:7001的意思是192.168.25.128:7004作为192.168.25.128:7001的从节点,同理,192.168.25.128:7005作为了192.168.25.128:7002的从节点,192.168.25.128:7006作为了192.168.25.128:7003的从节点。这样我们的集群便搭建完了。
(转) 淘淘商城系列——Redis集群的搭建的更多相关文章
- linux环境(CentOS-6.7)下redis集群的搭建全过程
linux环境下redis集群的搭建全过程: 使用mount命令将光盘挂载到/mnt/cdrom目录下: [root@hadoop03 ~]# mount -t iso9660 -o ro /dev/ ...
- 【redis】 linux 下redis 集群环境搭建
Redis集群 (要让集群正常工作至少需要3个主节点,在这里我们要创建6个redis节点,其中三个为主节点,三个为从节点,对应的redis节点的ip和端口对应关系如下) 127.0.0.1:63791 ...
- 2.Redis集群环境搭建
转载请出自出处:http://www.cnblogs.com/hd3013779515/ 一.基本概念 1.redis集群是一个可以在多个节点之间进行数据共享的设施.redis集群提供了以下两个好处1 ...
- redis集群的搭建详细教程
1 Redis-cluster架构图 redis-cluster投票:容错 (至少要三个才可以,才能超过半数) 架构细节: (1)所有的redis节点彼此互联(PING-PO ...
- <正则吃饺子> :关于redis集群的搭建、集群测试、搭建中遇到的问题总结
项目中使用了redis ,对于其基本的使用,相对简单些,根据项目中已经提供的工具就可以实现基本的功能,但是只是这样的话,对于redis还是太肤浅,甚至刚开始时候,集群.多节点.主从是什么,他们之间是什 ...
- Redis集群环境搭建
Redis集群cluster环境搭建 描述:本章节主要单服务器搭建集群,在一个服务器上启动多个不同端口的redis服务,非真实环境. 真实环境下redis集群会搭建在多个物理服务器上,并非单一的服务器 ...
- Redis集群的搭建【转】
redis集群的特点: 1.机器多,能够保证redis服务器出现问题后,影响较小 2.自备主从结构,自动的根据算法划分主从结构.动态的实现 3.能够根据主从结构自动的实现高可用 4.实现数据文件的备份 ...
- redis集群redis-cluster搭建
redis集群搭建--参考微信公众号(诗情画意程序员):https://mp.weixin.qq.com/s/s5eJE801TInHgb8bzCapJQ 这是来自redis官网的一段介绍,大概意思就 ...
- Redis集群环境搭建实践
0 Redis集群简介 Redis集群(Redis Cluster)是Redis提供的分布式数据库方案,通过分片(sharding)来进行数据共享,并提供复制和故障转移功能.相比于主从复制.哨兵模式, ...
随机推荐
- 一个Navi过程下多个DocumentCompleted事件问题的解决的方法
7.16 Marked to Write.... 七月份马克的一篇文章了,今天才想起来把他写完,呵呵. 原本是七月份用来做微博爬虫的,后来发现新浪对机器人的检測不好绕过,连简单地訪问都会被检測出来,后 ...
- IOS View编程指南笔记
我们所示程序 对于一切IOS APP来说.我们看的的内容,都是UIView所呈现的. UIView如场景,UIWindow如舞台.UIView粉墨登场在UIWindow这个舞台上,使我们看到丰富多彩的 ...
- (工具类)Linux笔记之终端日志记录工具script
在学习Linux时,有时候终端的打印消息对于我们很重要,可是终端显示也是有一定的缓冲空间的.当信息打印许多时,前面的信息就会被覆盖掉.所以这里网上搜索了一下这方面的介绍.现总结例如以下: script ...
- NYOJ 496 [巡回赛-拓扑排序]
链接:click here 题意: 巡回赛 时间限制:1000 ms | 内存限制:65535 KB 难度:3 描写叙述 世界拳击协会(WBA)是历史最悠久的世界性拳击组织,孕育了众多的世界冠军, ...
- 2016/1/12 第一题 输出 i 出现次数 第二题 用for循环和if条件句去除字符串中空格 第三题不用endwith 实现尾端字符查询
import java.util.Scanner; public class Number { private static Object i; /* *第一题 mingrikejijavabu中字符 ...
- a non-linear editing software
VLMC, open source video editor - VideoLAN http://www.videolan.org/vlmc/
- 牛了个逼,phpstorm查询技巧
两次shift,会弹出最近常用的文件. 可以查询按照方法名,类名,文件名等进行查询. Ctrl+E可以查看最近使用的文件. Ctrl+Shift+E可以查看最近修改的文件. Ctrl+shift+N ...
- SGU 145
节点不可重复经过的K短路问题. 思路:二分路径长度,深搜小于等于路径长度的路径数.可以利用可重复点K短路问题中的A*函数进行剪枝. 尝试另一种解法:把可重复点K短路A*直接搬过来,堆中的每个元素额外记 ...
- 29. ExtJs - Struts2 整合(1) - 登录页面
转自:https://yarafa.iteye.com/blog/729197 初学 ExtJS,在此记录下学习过程中的点点滴滴,以备不时只需,也希望能给跟我一样的菜鸟一些帮助,老鸟请忽略.如有不当之 ...
- 关于Jedis无法连接上Linux上Redis问题
环境:CentOS7.Redis 主要解决Jedis客户端无法连接Linux上Redis服务问题 1.修改Redis目录下的redis.conf配置文件 注释掉bind本地回环地址:bind 127. ...