SQL SERVER全面优化-------索引有多重要?
想了好久索引的重要性应该怎么写?讲原理结构?我估计大部分人不愿意看,也不愿意花那么多时间仔细研究。光写应用?感觉不明白原理一样不会用。举例说明?情况太多也写不全....到底该怎么写呢?
随便写吧,想到哪写到哪!
前面很多篇不管CPU、内存、磁盘、语句等等等都提到了索引的重要,我想刚刚开始学数据库的在校学生都知道索引对语句性能的重要性。但他们可能不知道,对语句的重要性就是对系统的重要性!
抛出一个问题 :你相信一条语句就能让你的大系统挂掉么?
带着问题,首先还是贴出我的座驾

最近不太喜欢红色换了一辆!
--------------博客地址---------------------------------------------------------------------------------------
Expert 诊断优化系列 http://www.cnblogs.com/double-K/
废话不多说,直接开整-----------------------------------------------------------------------------------------
开篇小测验
下面这样一个小SQL 你该怎么样添加最优索引
两个表上现在只有聚集索引 bigproduct 表上已经有聚集索引 ProductID
bigtransactionhistory 表上已经有聚集索引 TransactionID
select p.productnumber,p.reorderpoint,th.Quantity
from bigproduct as p
join bigtransactionhistory as th on th.productid=p.productid and th.TransactionDate > p.SellStartDate
where p.name in ('LL Crankarm1000','ML Crankarm1000') and th.TransactionDate > '2010-01-01'
你是否一眼就能看出来呢?
答案将在文章中逐步揭晓~~~
简单粗暴的添加索引
看过我前面文章的看官们一定会发现我很喜欢用“简单粗暴”这个词,一是因为词汇量小文笔也差,真心用不出高大上的词儿! 再一个,你们不喜欢简单粗暴么~~干货最重要,不是么?
首先我们看一下没有优化前的执行计划


clustered index scan 这其实就是表扫描,不是table scan 只是因为表上有聚集索引
可以看出这个查询俩表都使用了表扫描!
where 条件添加索引
首先大多数人都知道 where 条件中的字段需要添加索引! 我们添加一下看看效果创建
在 bigproduct 表上创建 name 列索引 ,在bigtransactionhistory表上创建 TransactionDate 列索引。
再次执行语句看一下效果!


添加where索引以后可以看到以下几个现象
- bigproduct 从原来的clustered index scan 变成 index seek
- 另外多出来个KEY Lookup(clustered)
- bigproduct 上添加的索引起了作用,逻辑读bigproduct 由 601 变成 10。
- bigtransactionhistory 没啥变化啊 还是clustered index scan
解释一下出现的现象 : 首先一点bigproduct 边添加的where 条件索引,起到了作用,执行的时候不是全表扫描了,逻辑读有明显的下降,出现的 KEY Lookup 是因为选择(select)的列,在索引中没有,而需要通过聚集索引再查找一次,再找一次也意味着多一部分开销!
那么同样添加了where 条件索引的bigtransactionhistory 表为什么没起作用呢? 那是因为SQL优化器在选择计划的时候认为,不使用TransactionDate 列索引查找效率会更好!
真的么? 我们来验证一下,通过指定选择索引,来让优化器选择索引查找!


强制使用索引以后,可以看出逻辑读由 14W 变成1961W,语句时间也变得很长,这就是优化器为什么不选用你加的索引!优化器还是很智能的吧。
高能预警:优化器可不是什么时候都这么智能的...由于缓存计划或优化器抽风等原因,也会出现优化器用了这种索引,导致你的语句奇慢,读飙升直接影响到你的内存、磁盘、CPU资源!另外如果这样一条语句是系统中一条很频繁运行的语句,你的系统就挂了!没错就挂了!这就是开篇抛出的问题就是因为一条语句!
消灭Key Lookup 添加select 字段
这就是传说中的覆盖索引!
看到执行计划中存在Key Lookup 而且消耗占比很高,如上面强制索引的计划,那么我们就要想到的 在索引中包含那些SELECT 的列!如果消耗低,逻辑读少,如上面bigproduct 表中的Key Lookup 就可以忽略(如果你追求完美,也一样优化就可以了)。
包含列的图形化创建 : @秋仙 特意给你的说明
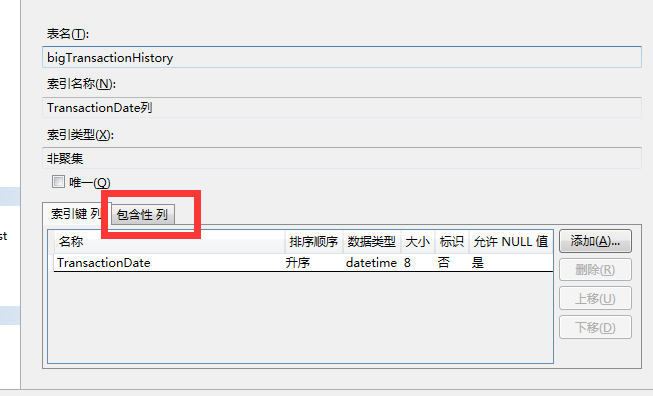
语句创建就是 :
CREATE NONCLUSTERED INDEX TransactionDate包含ProductID_Quantity
ON [dbo].[bigTransactionHistory] ([TransactionDate]) ------INCLUDE 就是包含列
INCLUDE ([ProductID],[Quantity])
GO
下面我们添加一下看看效果 :
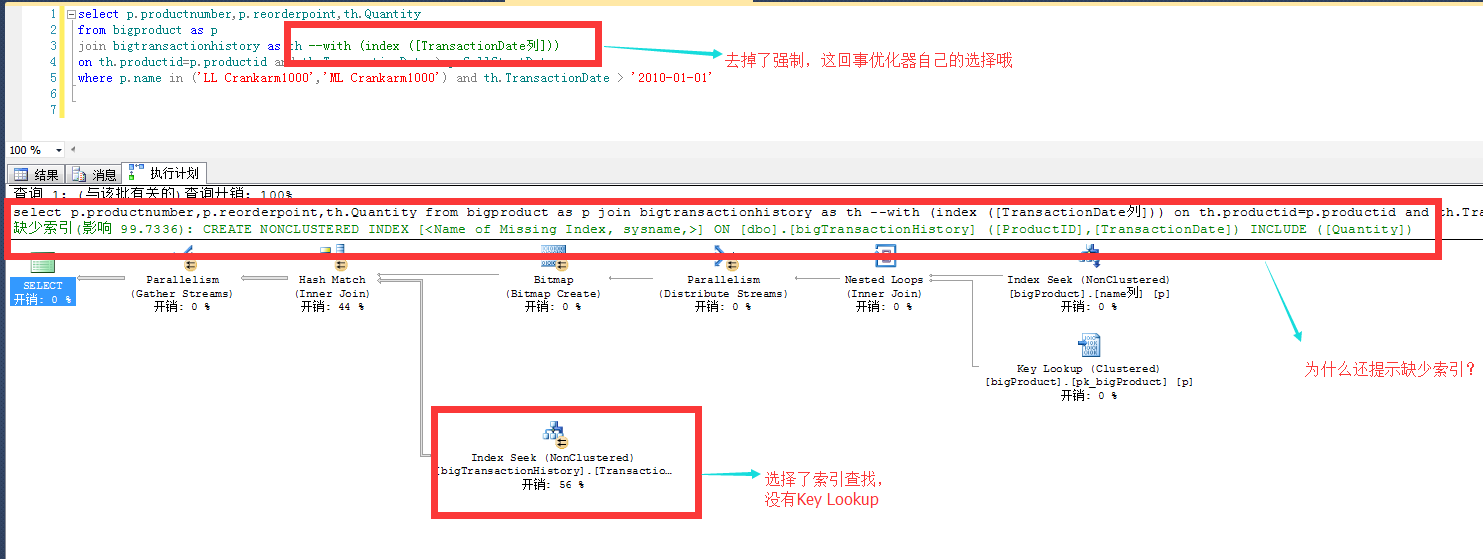

添加select 索引字段后可以看出的现象:
- 优化器自己选择了index seek
- bigtransactionhistory占比最高的Key Lookup消失了
- 逻辑读由原来无索引的14W变成1W
- bigtransactionhistory表还提示缺少索引?
通过优化索引添加select 字段,我们看出语句又一次得到了提升 bigtransactionhistory 从表扫描变成索引查找,逻辑读由14W变成 1W!这是一个质的飞跃啊!
CREATE NONCLUSTERED INDEX TransactionDate包含ProductID_Quantity
ON [dbo].[bigTransactionHistory] ([TransactionDate]) ------INCLUDE 就是包含列
INCLUDE ([ProductID],[Quantity])
GO
那为什么还提示缺少索引呢? 创建一下试试吧!
索引再优化加入表关联列
按照提示我们创建索引 : 和上一个索引的不同 ProductID 列由包含列变成了索引列!
USE [AdventureWorks2012]
GO
CREATE NONCLUSTERED INDEX ProductID_TransactionDate包含Quantity
ON [dbo].[bigTransactionHistory] ([ProductID],[TransactionDate])
INCLUDE ([Quantity])
我们看一下效果:
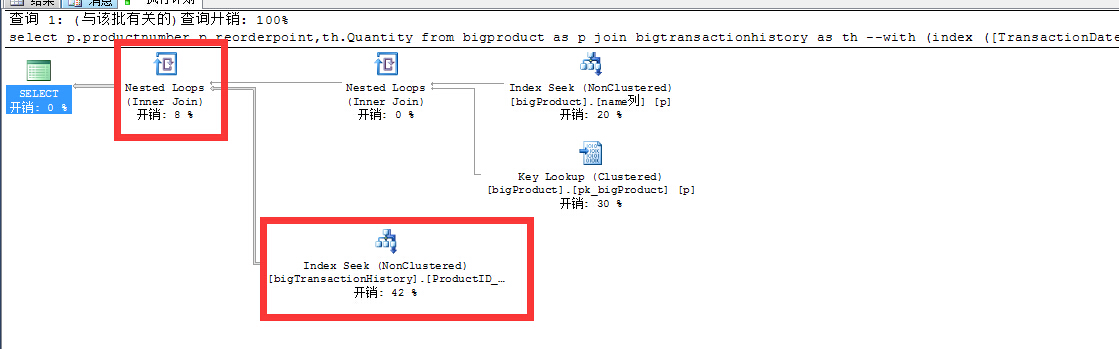

再次优化索引以后可以看到以下几个现象
- bigtransactionhistory表还是索引查找index seek
- bigtransactionhistory依然没有了Key Lookup
- 两表关联的hash join 变成了nested loops
- 并行计划变成了串行
- 逻辑读又从1W 变成18
又一次质的飞跃!读从原来的14W 变成1W 又变成18,这样大大减少了内存和IO的消耗,另外并行计划也变成了串行,无疑又减少了大量CPU的消耗!语句时间,我想这里就不用多说了吧?
高能预警:这里所说的hash join,并行变串行,不懂的朋友可以在百度自行学习,这里只是针对当前语句的情况,不能一概而论!
精简你的索引
大家都知道,索引会导致update、insert、delete操作变慢!那么尽量精简你的索引就是一个很重要的话题了!
上面的优化过程中我们创建了几个索引,以bigTransactionHistory为例来看一下:

脚本这里就不贴了,其实我们最后创建的索引 ProductID_TransactionDate包含Quantity 已经包含了前两个索引,而且可以说无论任何类似语句都使用ProductID_TransactionDate包含Quantity 就可以了!
那么我们就可以清除前两个索引!
--------------博客地址---------------------------------------------------------------------------------------
Expert 诊断优化系列 http://www.cnblogs.com/double-K/
-----------------------------------------------------------------------------------------------------
至此语句的优化算是结束了,留下的就是bigproduct 依然有一个Key Lookup可以优化,可以仿照上面的继续优化,这里就不细说了。语句只是经过了简单的索引优化就从一辆2手QQ变成了法拉利,是不是很神奇?
这就是索引的重要性!
开篇小测试你做对了么?如果没做对那么这么请你自行模拟一个场景再现本篇的话题吧!
-----------------------------------------------------------------------------------------------------
总结 : 往往一个系统的整体缓慢都是因为索引问题导致的,优化索引是对你系统最简单的保养!
不要小看一条语句的威力,一条语句足可以让你的系统彻底无法工作!
一个问题随之而来语句一条一条漫无目的的优化么?我怎么找出系统的问题语句?怎么样的一个优先级?
请参见前文 : Expert 诊断优化系列------------------语句调优三板斧
后一篇我将使用 Expert for sqlserver 工具讲述怎么样针对重点语句调索引,喜欢的看官请mark了!
Expert 诊断优化系列-------------针对重点语句调索引
----------------------------------------------------------------------------------------------------
注:此文章为原创,欢迎转载,请在文章页面明显位置给出此文链接!
若您觉得这篇文章还不错请点击下右下角的推荐,非常感谢!
引用高大侠的一句话 :“拒绝SQL Server背锅,从我做起!”
为了方便阅读给出系列文章的导读链接:
SQL SERVER全面优化-------Expert for SQL Server 诊断系列
----------------------深入索引原理推荐博客--------------------------
目测这几篇文章每篇的编写时间都要超过10小时,非常值得阅读!
pursuer.chen 的博客
SQL Server 深入解析索引存储(上)
SQL Server 深入解析索引存储(中)
SQL Server 深入解析索引存储(下)
桦仔的博客
SQLSERVER聚集索引与非聚集索引的再次研究(上)
SQLSERVER聚集索引与非聚集索引的再次研究(下)
SQL SERVER全面优化-------索引有多重要?的更多相关文章
- SQL SERVER全面优化-------Expert for SQL Server 诊断系列
现在很多用户被数据库的慢的问题所困扰,又苦于花钱请一个专业的DBA成本太高.软件维护人员对数据库的了解又不是那么深入,所以导致问题迟迟不能解决,或只能暂时解决不能得到根治.开发人员解决数据问题基本又是 ...
- SQL Server性能优化(15)选择合适的索引
一.关于聚集索引列的选择(参考) 1. 聚集索引所在的列,或者列的组合最好是唯一的. 当我们创建的聚集索引的值不唯一时,SQL Server则无法仅仅通过聚集索引列(也就是关键字)唯一确定一行.此时, ...
- SQL Server性能优化(9)聚集索引的存储结构
一.索引的概念和分类 索引的概念大家都知道,日常开发中我们也会使用常见的聚集索引.非聚集索引.但是除了这两者以外,sqlserver中还提供其他的索引,如: a. 唯一索引:不包含重复键的索引,聚集索 ...
- SQL SERVER全面优化-------写出好语句是习惯
前几篇文章已经从整体提供了诊断数据库的各个方面问题的基本思路...也许对你很有用,也许你觉得离自己太远.那么今天我们从语句的一些优化写法及一些简单优化方法做一个介绍.这对于很多开发人员来说还是很有用的 ...
- SQL Server基础之索引
索引用于快速找出在某个列中有某一特定值的行,不使用索引,数据库必须从第一条记录开始读完整个表,直到找出相关的行.表越大,查询数据所花费的时间越多,如果表中查询的列有一个索引,数据库能快速到达一个位置 ...
- SQL Server 列存储索引强化
SQL Server 列存储索引强化 SQL Server 列存储索引强化 1. 概述 2.背景 2.1 索引存储 2.2 缓存和I/O 2.3 Batch处理方式 3 聚集索引 3.1 提高索引创建 ...
- 转载: SQL Server中的索引
http://www.blogjava.net/wangdetian168/archive/2011/03/07/347192.html 1 SQL Server中的索引 索引是与表或视图关联的磁盘上 ...
- SQL SERVER全面优化
今天我们从语句的一些优化写法及一些简单优化方法做一个介绍.这对于很多开发人员来说还是很有用的!为了方便阅读给出前文链接: SQL SERVER全面优化-------Expert for SQL Ser ...
- sql server中的索引详情
什么是索引 拿汉语字典的目录页(索引)打比方:正如汉语字典中的汉字按页存放一样,SQL Server中的数据记录也是按页存放的,每页容量一般为4K .为了加快查找的速度,汉语字(词)典一般都有按拼音. ...
随机推荐
- [leetcode]leetcode初体验
这几天把之前的设计模式回顾了一遍,整理了一点以前的项目.同学说,打算刷leetcode题目,也勾起了我的兴趣,索性也刷一些题目,再提高一些内功.刚开始进去,leetcode随机分配的题目,直接也就做了 ...
- JAVA内部类有关
最近在看单例模式的实现,看到有一种利用JAVA静态内部类的特性来实现,对于内部类我还真是不了解,遂了解了一下,代码贴上. /** * 内部类分为:成员内部类.局部内部类.匿名内部类和静态内部类. */ ...
- WorkFlowHelper
/* # Microshaoft /r:System.Xaml.dll /r:System.Activities.dll /r:System.Activities.DurableInstancing. ...
- maven权威指南学习笔记(二)——安装、运行、获取帮助
这部分在网上很容易找到详细教程,这里就略写了. 基础:系统有配置好的jdk,通过 命令行 java -version,有类似下面的提示,表示java环境以配好 下载maven:官网 http://ma ...
- 将 xunit.runner.dnx 的 xml 输出转换为 Nunit 格式
由于目前 DNX 缺乏 XSLT 的转换能力,因此只能使用变通方法.具体参考这个链接 主要内容复制过来是: From @eriklarko on July 14, 2015 7:38 As a wor ...
- Tween Animation----Rotate旋转动画
activity_main.xml布局里 在res/下面新建一个anim文件夹用来保存动画的xml属性 我们在anim文件夹下面创建一个rotate.xml文件 代码如下: <?xml vers ...
- nodejs之主机不能访问到虚拟机的web服务器
问题:在主机使用VMware搭建虚拟机,并运行node.但是主机浏览器不能访问 环境:虚拟机使用centos7,网络模式为桥接.主机IP 192.168.1.48 虚拟机IP 192.168.1.5 ...
- C#解析json文件的方法
C# 解析 json JSON(全称为JavaScript Object Notation) 是一种轻量级的数据交换格式.它是基于JavaScript语法标准的一个子集. JSON采用完全独立于语言的 ...
- 泛型的排序问题(Collections.sort及Comparable的应用)
一.前言 java中对泛型(集合类型)排序的问题,主要采用了两张方式一种是对要排序的实体类,实现Comparable接口,另一种方式,Collections集合工具类进行排序. 二.实现Comp ...
- Cordova 3.x入门 - 目录
这个系列是基于Cordova 3.x的,很多Android的东西都是Eclipse ADT+Ant的,而目前Android的开发已经完全切换到了Android Studio+Gradle,需要大家特别 ...