利用Hadoop自带example实现wordCount
上次虽然把环境搭好了,但是实际运行起来一堆错误,下面简述一下踩的坑。
1、hadoop fs -put上传文件失败,WARN org.apache.hadoop.hdfs.server.datanode.DataNode: Problem connecting to server: master:8020
解决方案:https://www.cnblogs.com/BoqianLiu/p/10183535.html
2、NodeManager运行一段时间后自行消失
解决方案:同上,第1个问题解决了这个问题也消失了,亏我还给他准备了好几种解决方案。
具体过程:
1、开启hdfs与yarn集群
start-dfs.sh
start-yarn.sh
我这里测试图省事就直接start-all了,正常工作还是按照人家的建议来,分别开启好一点哈
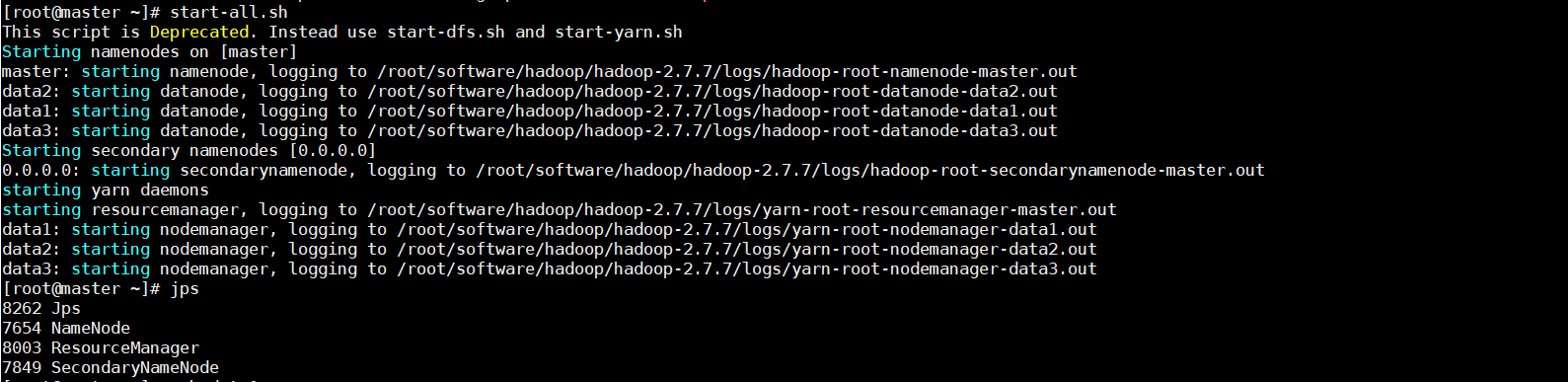
2、确认hadoop已经成功运行
ps -ef|grep hadoop

3、在hdfs新建test目录并测试
hadoop fs -mkdir /test
hadoop fs -ls -R /

4、从本地向test目录上传文件
*.txt表示当前终端目录下所有txt类型的文件
hadoop fs -put *.txt /test
5、运行hadoop自带example里面的wordcount程序
hadoop jar /root/software/hadoop/hadoop-2.7./share/hadoop/mapreduce/hadoop-mapreduce-examples-2.7..jar wordcount /test /output
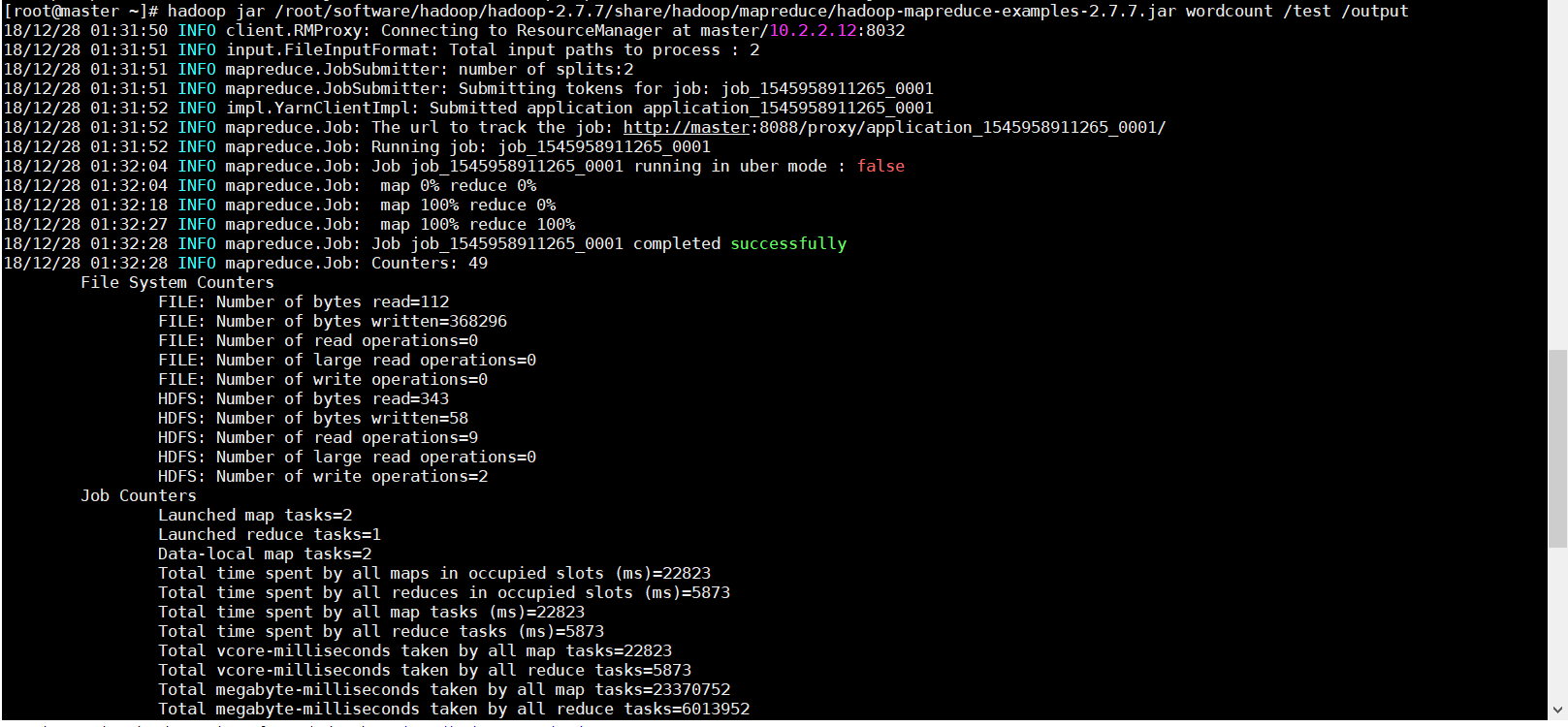
这个地方要注意的就是output必须是事先不存在的,如果已经存在会报错FileAlreadyExistsException,即便提前把里面的文件清空也是不可以的。

6、打印/output结果
hadoop fs -cat /output/part-r-

参考资料:
1、Ubuntu16.04 上运行 Hadoop2.7.3 自带example wordCount摸索记录
2、Hadoop学习之路(七)Hadoop集群shell常用命令
利用Hadoop自带example实现wordCount的更多相关文章
- 利用hadoop自带程序运行wordcount
1.启动hadoop守护进程 bin/start-all.sh 2.在hadoop的bin目录下建立一个input文件夹 JIAS-MacBook-Pro:hadoop- jia$ mkdir inp ...
- Hadoop入门实践之从WordCount程序说起
这段时间需要学习Hadoop了,以前一直听说Hadoop,但是从来没有研究过,这几天粗略看完了<Hadoop实战>这本书,对Hadoop编程有了大致的了解.接下来就是多看多写了.以Hado ...
- hadoop自带例子wordcount的具体运行步骤
1.在hadoop所在目录“usr/local”下创建一个文件夹input root@ubuntu:/usr/local# mkdir input 2.在文件夹input中创建两个文本文件file1. ...
- 执行hadoop自带的WordCount实例
hadoop 自带的WordCount实例可以统计一批文本文件中各单词出现的次数.下面介绍如何执行WordCount实例. 1.启动hadoop [root@hadoop ~]# start-all. ...
- 几个有关Hadoop自带的性能测试工具的应用
http://www.talkwithtrend.com/Question/177983-1247453 一些测试的描述如下内容最为详细,供你参考: 测试对于验证系统的正确性.分析系统的性能来说非常重 ...
- Hadoop_05_运行 Hadoop 自带 MapReduce程序
1. MapReduce使用 MapReduce是Hadoop中的分布式运算编程框架,只要按照其编程规范,只需要编写少量的业务逻辑代码即可实现 一个强大的海量数据并发处理程序 2. 运行Hadoop自 ...
- hadoop学习笔记:运行wordcount对文件字符串进行统计案例
文/朱季谦 我最近使用四台Centos虚拟机搭建了一套分布式hadoop环境,简单模拟了线上上的hadoop真实分布式集群,主要用于业余学习大数据相关体系. 其中,一台服务器作为NameNode,一台 ...
- 利用jdk自带的运行监控工具JConsole观察分析Java程序的运行
利用jdk自带的运行监控工具JConsole观察分析Java程序的运行 原文链接 一.JConsole是什么 从Java 5开始 引入了 JConsole.JConsole 是一个内置 Java 性能 ...
- Hadoop实战3:MapReduce编程-WordCount统计单词个数-eclipse-java-ubuntu环境
之前习惯用hadoop streaming环境编写python程序,下面总结编辑java的eclipse环境配置总结,及一个WordCount例子运行. 一 下载eclipse安装包及hadoop插件 ...
随机推荐
- 什么是gitlab CI ?CI代表什么?
CI是Continuous Integration的简称,就是持续集成的意思. 就是说你代码改动了,测试了,提交了,持续集成系统会自动构建(编译等等).持续集成的理念是每个提交的版本都应该是可交付的, ...
- linux 设备文件
一.设备文件 在dev目录下 外部设备通过创建好的设备文件连接到服务器上,例如可以通过设备号给连接上去的硬件发消息. 二.设备文件分类 块设备 按块为单位,随机访问的设备 常见的有 硬盘 字符设备 按 ...
- HTML-CSS浮动元素详解
浮动定位是指 1.1将元素排除在普通流之外,即元素将脱离标准文档流 1.2元素将不在页面占用空间 1.3将浮动元素放置在包含框的左边或者右边 1.4浮动元素依旧位于包含框之内 2. 浮动的框可以向左或 ...
- 分享知识-快乐自己:揭秘HDFS
揭秘HDFS: 一):大数据(hadoop)初始化环境搭建 二):大数据(hadoop)环境搭建 三):运行wordcount案例 四):揭秘HDFS 五):揭秘MapReduce 六):揭秘HBas ...
- hdu 2955 Robberies(01背包)
Robberies Time Limit: 2000/1000 MS (Java/Others) Memory Limit: 32768/32768 K (Java/Others)Total S ...
- Linux-NoSQL之Redis(二)
一.Redis配置文件详解 1.通用配置 daemonize no # 默认情况下,redis并不是以daemon形式来运行的.通过daemonize配置项可以控制redis的运行形式 pidfil ...
- php中五种常见的设计模式
设计模式 一书将设计模式引入软件社区,该书的作者是 Erich Gamma.Richard Helm.Ralph Johnson 和 John Vlissides Design(俗称 “四人帮”).所 ...
- POJ-1564 dfs
#include"cstring" #include"cstdio" +; int nux[maxn]; int nua[maxn];//解的集合 int t; ...
- 使用 Anthem.NET 框架的一个调试经历
简介:Anthem 是一个很好用的 Ajax 框架,支持 ASP.NET 1.1, 2.0.由于该框架的所有控件都继承自 ASP.NET 自身的服务器控件,保留了几乎所有这些控件的属性和行为(除了把它 ...
- BZOJ1216:[HNOI2003]操作系统
我对模拟的理解:https://www.cnblogs.com/AKMer/p/9064018.html 题目传送门:https://www.lydsy.com/JudgeOnline/problem ...