Sql Server中百万级数据的查询优化
万级别的数据真的算不上什么大数据,但是这个档的数据确实考核了普通的查询语句的性能,不同的书写方法有着千差万别的性能,都在这个级别中显现出来了,它不仅考核着你sql语句的性能,也考核着程序员的思想。
公司系统的一个查询界面最近非常慢,界面的响应时间在6-8秒钟时间,甚至更长。检查发现问题出现在数据库端,查询比较耗时。该界面涉及到多个表中的数据,基本表有150万数据,关联子表的最多的一个700多万数据,其它表数据也在几十万到几百万之间。其实按这样的数据级别查询响应时间应该在毫秒级内,不应该有这么长时间。那么接下来就该进行问题排查了。
由于这个这界面的功能主要是信息检索,查询比较复杂,太多的条件组合,使用存储过程太多的局限性,因此查询使用的是动态拼接的sql语句。查询方式是最常用的1、获取数据总数2、数据分页。直接上代码(部分条件)。
select numb=count(distinct t1.tlntcode)
from ZWOMMAINM0 t1 inner join ZWOMMLIBM0 t2 on t1.tlntcode=t2.tlntcode
join ZWOMEXPRM0 cp on t1.tlntcode=cp.tlntcode
join ZWOMILBSM0 i on i.tlntcode=t1.tlntcode
join ZWOMILBSM0 p on p.tlntcode=i.tlntcode
join ZWOMILBSM0 l on l.tlntcode=i.tlntcode
where isnull(t2.deletefg,'0')='0' and cp.companyn like '%IBM%' and cp.sequence=0
and i. mlbscode in('i0100','i0101','i0102','i0103','i0104','i0105','i0106') and i.locatype='10'
and p.mlbscode in('p0100','p0102','p0104','p0200','p0600') and p.locatype='10'
and l.mlbscode in('l030') and l.locatype='10'
查看执行时间

根据提示得知,整个查询耗时花费在了分析和编译为4秒,执行为0.7秒。查询语句没有发现什么问题,那么问题出现在了编译,如果让SQL语句执行原有的查询计划,那么跳过编译,只需0.7秒就能得到结果。那么如何做到预编译,或者使用现有的执行计划?
SQL Server有一优化算法,它保存了以往执行sql语句的执行计划,所有的执行计划都会在sys.syscacheobjects表中存储,如果当前sql语句在缓存表中能匹配到,那么它讲执行匹配到的执行计划,而不再进行编译。 那么解决方法我们首先想到的是存储过程(这就是我们面试或者理论中经常说的存储过程有预编译,平时也就是说说,不存在什么深刻印象),是的它能实现预编译,但是由于条件限制,查询太过复杂,如果把没有使用到查询条件的表都关联在一起反而影响到性能。排除存储过程,我们另外想到的就是
EXEC SP_EXECUTESQL @Sql, N'@p NVARCHAR(50)',@p
为什么SP_EXECUTESQL 能复用查询计划而普通sql语句不能,我们从缓存表中查看就能发现问题
select bucketid,cacheobjtype,objtype,objid,sql,sqlbytes from sys.syscacheobjects where cacheobjtype='Compiled Plan'
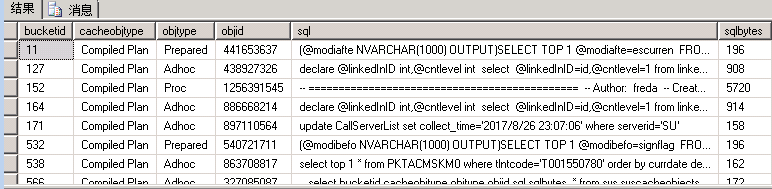
表中sql字段就是历史执行计划的查询语句,如果sql匹配成功那么就会执行匹配的执行计划。普通sql语句很难与之匹配,因为它不但包含了结构还包含了参数,复用率很低。而SP_EXECUTESQL 执行时只存储结构,参数不存储,因此复用率很高。找到了解决方法,那么直接行动。
declare @Sql nvarchar(max),@cpny nvarchar(50)='IBM'
declare @i varchar(1000)='i0100,i0101,i0102,i0103,i0104,i0105,i0106,i0107,i0109',
@p varchar(1000)='p0100,p0101,p0102,p0103,p0104,p0107,p0201',@l varchar(1000)='l030'
set @Sql='select value into #i from f_CSplit(@i,'','')
select value into #p from f_CSplit(@p,'','')
select value into #l from f_CSplit(@l,'','')
select numb=count(distinct t1.tlntcode)
from ZWOMMAINM0 t1 inner join ZWOMMLIBM0 t2 on t1.tlntcode=t2.tlntcode
join ZWOMILBSM0 i on i.tlntcode=t1.tlntcode join ZWOMILBSM0 p on p.tlntcode=t1.tlntcode
join ZWOMILBSM0 l on l.tlntcode=t1.tlntcode join ZWOMEXPRM0 cp on t1.tlntcode=cp.tlntcode
where isnull(t2.deletefg,''0'')=''0''
and i.mlbscode in(select value from #i) and i.locatype=''10'' -- and i.mlbstype=''20''
and p.mlbscode in(select value from #p) and p.locatype=''10'' --and p.mlbstype=''40''
and l.mlbscode in(select value from #l) and l.locatype=''10''-- and l.mlbstype=''50''
and cp.companyn like ''%''+@cpny+''%'' and cp.sequence=0 ' EXEC SP_EXECUTESQL @Sql, N'@cpny NVARCHAR(50),@i NVARCHAR(50),@p NVARCHAR(50),@l NVARCHAR(50)',
@cpny,@i,@p,@l

总耗时0.5秒,无论参数如何改变基本都在0.5秒波动,基本符合了我们的要求,如果想进一步优化还可以进行表分区等其他优化方案。
当我们发现查询速度慢时,有可能是分析和编译占用了你的太多时间,因此简化你的查询语句、复用执行计划能帮你走出困境。
Sql Server中百万级数据的查询优化的更多相关文章
- SQL Server中的SQL语句优化与效率问题
很多人不知道SQL语句在SQL SERVER中是如何执行的,他们担心自己所写的SQL语句会被SQL SERVER误解.比如: select * from table1 where name='zhan ...
- 【转】SQL Server海量数据库的索引、查询优化及分页算法
探讨如何在有着1000万条数据的MS SQL SERVER数据库中实现快速的数据提取和数据分页.以下代码说明了我们实例中数据库的“红头文件”一表的部分数据结构: CREATE TABLE [dbo]. ...
- SQL Server中的SQL语句优化与效率
很多人不知道SQL语句在SQL SERVER中是如何执行的,他们担心自己所写的SQL语句会被SQL SERVER误解.比如: select * from table1 where name='zhan ...
- SQL Server中TOP子句可能导致的问题以及解决办法
简介 在SQL Server中,针对复杂查询使用TOP子句可能会出现对性能的影响,这种影响可能是好的影响,也可能是坏的影响,针对不同的情况有不同的可能性. 关系数据库中SQL语句只 ...
- SQL Server中使用Check约束提升性能
在SQL Server中,SQL语句的执行是依赖查询优化器生成的执行计划,而执行计划的好坏直接关乎执行性能. 在查询优化器生成执行计划过程中,需要参考元数据来尽可能生成高效的执行计划, ...
- SQL Server 中 EXEC 与 SP_EXECUTESQL 的区别
SQL Server 中 EXEC 与 SP_EXECUTESQL 的区别 MSSQL为我们提供了两种动态执行SQL语句的命令,分别是 EXEC 和 SP_EXECUTESQL ,我们先来看一下两种方 ...
- 浅谈SQL Server中的三种物理连接操作
简介 在SQL Server中,我们所常见的表与表之间的Inner Join,Outer Join都会被执行引擎根据所选的列,数据上是否有索引,所选数据的选择性转化为Loop Join,Merge J ...
- 谈一谈SQL Server中的执行计划缓存(上)
简介 我们平时所写的SQL语句本质只是获取数据的逻辑,而不是获取数据的物理路径.当我们写的SQL语句传到SQL Server的时候,查询分析器会将语句依次进行解析(Parse).绑定(Bind).查询 ...
- SQL SERVER中用户定义标量函数(scalar user defined function)的性能问题
用户定义函数(UDF)分类 SQL SERVER中的用户定义函数(User Defined Functions 简称UDF)分为标量函数(Scalar-Valued Function)和表值函数(T ...
随机推荐
- Codeforces Round #327 (Div2) A~E
CodeForces 591A 题意:在距离为L的两端A,B,相向发射魔法,a(以P1的速度)-->B,A<--b(以P2的速度).假设a-->B,途中相遇,则返回到原点A<- ...
- table不让td中文字溢出操作方法
table不让td中文字溢出操作方法 table{ width:100px; table-layout:fixed;/* 只有定义了表格的布局算法为fixed,下面td的定义才能起作用. */ } t ...
- POJ 2318 TOYS | 二分+判断点在多边形内
题意: 给一个矩形的区域(左上角为(x1,y1) 右下角为(x2,y2)),给出n对(u,v)表示(u,y1) 和 (v,y2)构成线段将矩形切割 这样构成了n+1个多边形,再给出m个点,问每个多边形 ...
- Lights inside 3D Grid LightOJ - 1284 (概率dp + 推导)
Lights inside 3D Grid LightOJ - 1284 题意: 在一个三维的空间,每个点都有一盏灯,开始全是关的, 现在每次随机选两个点,把两个点之间的全部点,开关都按一遍:问k次过 ...
- BZOJ3631 [JLOI2014]松鼠的新家 【树上差分】
题目 松鼠的新家是一棵树,前几天刚刚装修了新家,新家有n个房间,并且有n-1根树枝连接,每个房间都可以相互到达,且俩个房间之间的路线都是唯一的.天哪,他居然真的住在"树"上.松鼠想 ...
- 2017-7-18-每日博客-关于Linux基本命令CnetOS7系统基本操作命令.doc
1.root/下 cat anaconda-ks.cfg 确定是否装base软件组 yum groupinstall base 安装base组ifconfig 命令就可以使用了或者使用ip add ...
- powerdesign相关
1.安装程序和汉化放百度云了 2.打印错误处理 http://jingyan.baidu.com/article/c45ad29cd84e4b051753e2c3.html 3.导出sql http: ...
- 浅谈android Socket 通信及自建ServerSocket服务端常见问题
摘 要:TCP/IP通信协议是可靠的面向连接的网络协议,它在通信两端各建立一个Socket,从而在两端形成网络虚拟链路,进而应用程序可通过可以通过虚拟链路进行通信.Java对于基于TCP协议的网络通 ...
- jquerydom对象和字符串之间的转换
字符串转jquery对象:var tmp = $('<div>dd</div>').attr('id','bbq'); //用$符包裹起来即可 jquery对象转字符串: tm ...
- myeclipse maven web项目配置
启用maven:window-->preference-->MyEclipse-->Maven4MyEclipse, 勾选复选框(Enable Mave4MyEclipse feat ...