Hadoop 2.x简介
Hadoop 2.0产生背景
- Hadoop1.0中HDFS和MapReduce在高可用、扩展性等方面存在问题
- HDFS存在的问题
- NameNode单点故障,难以应用于在线场景
- NameNode压力过大,且内存受限,影响系统扩展性
- MapReduce存在的问题
- JobTracker访问压力大,影响系统扩展性
- 难以支持除MapReduce之外的计算框架,比如Spark 、Storm等
MapReduce是离线计算框架,计算时间会比较长
Spark是内存计算框架,更快
Storm是流计算框架,可实时获取计算结果
Hadoop 1.x 与Hadoop 2.x
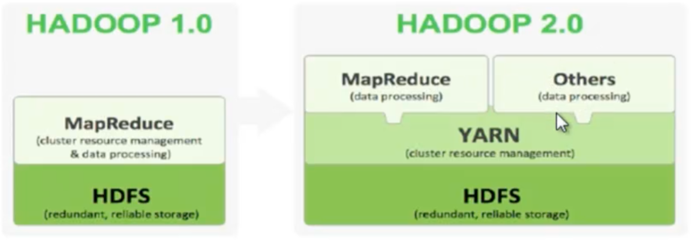
- Hadoop 2.x由HDFS、MapReduce和YARN三个分支构成
- HDFS : NN Federation、HA;
- MapReduce : 运行在YARN上的MR
- YARN : 资源管理系统(内存、CPU资源)
Federation把元数据分成两个独立的NameNode去工作。
YARN知道任何一台机器的使用情况,在执行任务的时候,首先去YARN上申请,YARN 分配到某台机器上去执行,可做到资源不浪费
HDFS存储的数据可由MapReduce进行计算,也可以由其它的计算框架计算
HDFS 2.x优点
- 解决HDFS 1.0中单点故障和内存受限问题
- 解决单点故障
- HDFS HA : 通过主备NameNode解决(只有一个NameNode正常工作,其它都是备用)
- 如果主NameNode发生故障,则切换到备NameNode上
- 解决内存受限问题
- HDFS Federation(联邦)
- 水平扩展,支持多个NameNode
- 每个NameNode分管一部分目录(相互独立)
- 所有NameNode共享所有DataNode存储资源
- 2.x仅是架构上发生了变化,使用方式不变
- 对HDFS使用者透明
- HDFS 1.X中的命令和API仍可以使用
Hadoop 2.x简介的更多相关文章
- Hadoop开发环境简介(转)
1.Hadoop开发环境简介 1.1 Hadoop集群简介 Java版本:jdk-6u31-linux-i586.bin Linux系统:CentOS6.0 Hadoop版本:hadoop-1.0.0 ...
- Hadoop发展历史简介
简介 本篇文章主要介绍了Hadoop系统的发展历史以及商业化现状, 科普文. 如果你喜欢本博客,请点此查看本博客所有文章:http://www.cnblogs.com/xuanku/p/index.h ...
- Hadoop体系架构简介
今天跟一个朋友在讨论hadoop体系架构,从当下流行的Hadoop+HDFS+MapReduce+Hbase+Pig+Hive+Spark+Storm开始一直讲到HDFS的底层实现,MapReduce ...
- 二十六、Hadoop学习笔记————Hadoop Yarn的简介复习
1. 介绍 YARN(Yet Another Resource Negotiator)是一个通用的资源管理平台,可为各类计算框架提供资源的管理和调度. 之前有提到过,Yarn主要是为了减轻Hadoop ...
- Hadoop mapreduce框架简介
传统hadoop MapReduce架构(老架构) 从上图中可以清楚的看出原 MapReduce 程序的流程及设计思路: 1.首先用户程序 (JobClient) 提交了一个 job,job ...
- Hadoop主要生态系统简介
Hadoop的起源 Doug Cutting是Hadoop之父 ,起初他开创了一个开源软件Lucene(用Java语言编写,提供了全文检索引擎的架构,与Google类似),Lucene后来面临与Goo ...
- hadoop(十一)HDFS简介和常用命令介绍
HDFS背景 随着数据量的增大,在一个操作系统中内存不了了,就需要分配到操作系统的的管理磁盘中,但是不方便管理者维护,迫切需要一种系统来管理多态机器上的文件,这就是分布式文件管理系统. HDFS的概念 ...
- hadoop学习笔记(一):hadoop生态系统及简介
一.hadoop1.x的生态系统 HBase:实时分布式数据库 相当于关系型数据库,数据放在文件中,文件就放在HDFS中.因此HBase是基于HDFS的关系型数据库.实时性:延迟非常低,实时性高. 举 ...
- 【hadoop】——window下elicpse连接hadoop集群基础超详细版
1.Hadoop开发环境简介 1.1 Hadoop集群简介 Java版本:jdk-6u31-linux-i586.bin Linux系统:CentOS6.0 Hadoop版本:hadoop-1.0.0 ...
随机推荐
- UVALive - 4255 - Guess (拓扑排序)
Guess 题目传送:Guess 白书例题 注意拓扑排序时,,入度同一时候为0的前缀和须要赋值为同一个数(这个数能够随机取.由于前缀和是累加的,每个a的数值都仅仅和前缀和之差有关).,由于此时能够看成 ...
- C语言中的signal函数
signal是一个系统调用.是一种特殊的中断,当某种特定的"软件中断"发生时.用于调用的程序.中断通常是程序运行中出现的特殊情况,如引用特殊内存中的非法地址, 浮点数被0除. si ...
- 查看Android源码和源码布局
一.查看源码 1.https://github.com/android 2.http://grepcode.com/project/repository.grepcode.com/java/ext/c ...
- Codeforces 14D Two Paths 树的直径
题目链接:点击打开链接 题意:给定一棵树 找2条点不反复的路径,使得两路径的长度乘积最大 思路: 1.为了保证点不反复,在图中删去一条边,枚举这条删边 2.这样得到了2个树,在各自的树中找最长链.即树 ...
- linux下apache+php搭建配置记录
第1章 环境说明1.1 系统说明Centos 6.2 (最小化安装)1.2 软件说明httpd-2.4.2.tar.gzapr-util-1.4.1.tar.gzapr-1.4.6.tar.gzpc ...
- 微信小程序之云开发一
最近听说微信小程序发布了云开发,可以不需要购买服务器,就能开发小程序和发布小程序,对于动辄千元的服务器,极大的节约了开发成本,受不住诱惑,我就开始了小程序的云开发,目前项目已上线,亲测不收费,闲不住的 ...
- 【php】global的使用与php的全局变量
php的全局变量和其余编程语言是不同的,在大多数的编程语言中,全局变量在其下的函数.类中自己主动生效.除非被局部变量覆盖,或者根本就不同意再声明同样名称与类型的局部变量.可是php中的全局变量不是默认 ...
- (比赛)B - Super Mobile Charger
B - Super Mobile Charger Time Limit:1000MS Memory Limit:32768KB 64bit IO Format:%I64d & ...
- ibatis中井号跟美元符号区别(#.$)
1.#可以进行预编译,进行类型匹配,#变量名# 会转化为 jdbc 的 类型 $不进行数据类型匹配,$变量名$就直接把 $name$替换为 name的内容 例如: select * from tabl ...
- php记录百度等搜索引擎蜘蛛的来访记录
<?php function is_robot() { $useragent = strtolower($_SERVER['HTTP_USER_AGENT']); if (strpos($use ...