ElasticSearch 专业术语
1、Analysis(分析)
分析的过程就是将全文(full text)转换成 术语/分词(terms)。 这取决于使用那个分析器,这些短语:“FOO BAR”, “Foo-Bar”, “foo,bar”,可能会拆分成” foo”和“bar”。这些拆分后的词实际上是存储在索引中。
一个完整的文本查询(而不是一个分词查询) “FoO:bAR”,将被分解成 “foo”,“bar”,来匹配存储在索引中的分词。正是这一过程的分析(包括在索引时间和搜索时间),允许elasticsearch执行全文查询。
2、Cluster (集群)
一个集群包含一个或多个分配了相同的集群名称的节点。每个集群都有一个主节点是集群自动选择产生,并且可以决定如果当前主节点失败,哪些可以替换
3、Document(文档)
文档是存储在elasticsearch中的一个JSON文件。这是相当与关系数据库中表的一行数据。每个文档被存储在索引中,并具有一个类型和一个id。
一个文档是一个JSON对象(也被称为在其他语言中的 hash / hashmap / associative array(关联数组)),其中包含零个或多个字段 或者 键值对。
原始JSON文档将被存储在索引的_source字段,在获得(getting)或者 搜索(searching)默认的返回时,得到或搜索文档。
4、Id(标识)
每个文档ID标识了一个文档。一个文档的索引/类型/ ID必须是唯一的。如果没有提供ID,将是自动生成。(还可以看到路由<routing>)
5、Field(字段)
文档中包含的一组字段或键值对。字段的值可以是一个简单的(标量)值(如字符串,整数,日期),或者一个嵌套的结构就像一个数组或对象。一个字段就是类似关系数据库表中的一列。
映射的每个字段有一个字段的类型“type”(不要与文档类型混淆),表示那种类型的数据可以存储在该字段里,如:整数<integer>,字符串<string>,对象<object>。
映射还允许你定义(除其他事项外)一个字段的值如何进行分析。
6、Index(索引)
索引就是像关系数据库中的“数据库”。通过映射可以定义成多种类型。索引是一个逻辑命名空间映射到一个或多个主要的分片,可以有零个或多个副本分片
7、Mapping(映射)
映射是像关系数据库中的”模式定义“。每个索引都有一个映射,它定义了每个索引的类型,再加上一些索引范围的设置。映射可以被明确地定义,或者在一个文档被索引的时候自动生成。
8、Node(节点)
节点是属于elasticsearch群集的运行实例。测试的时候,在一台服务器可以启动多个节点,但通常情况下应该在一台服务器运行一个节点。在启动时,
节点将使用单播(或组播,但是必须指定)来发现使用相同的群集名称的群集,并会尝试加入该群集。
9、Primary shard(主分片)
每个文档都存储在一个主要分片上。当你索引一个文档时,索引首先生成在主分片上,然后才到主分片的所有副本上。默认情况下,索引有5个主分片。
可以指定更多或更少的主分片来适应索引可以处理的文档数。一旦创建了索引,就不能改变索引中主分片的数量。
10、Replica shard(副本分片)
每个主分片可以有零个或多个副本。副本是主分片的一个拷贝,有两个作用:
1、故障转移:如果主分片有问题,副本分片可以提升为主分片;
2、提高性能:获取和搜索请求可以处理主分片或副本分片。
默认情况下,每个主分片有一个副本,不过索引的副本数量可以动态地改变。在同一个节点上,一个副本分片将永远不会和其主分片一起运行。
11、Routing(路由)
当你索引一个文档,它是存储在一个主分片里。这分片的选择是通过哈希的路由值。默认情况下,路由值来自文档的ID;如果该文档指定了父文档,
则使用父文档的ID(以确保这个子文档和父文件都存储在相同的分片上)。这个路由值可以在索引的时候,通过指定数值或者配置字段映射来覆盖。
12、Shard(分片)
一个分片是一个单一的Lucene的实例。这是一个低级别的通过ElasticSearch自动管理的“工作者”单元。索引是一个逻辑命名空间指向主分片和副本分片。
索引的主分片和副本分片的数量需要明确的指定。然而你的代码应该只处理一个索引。Elasticsearch分配集群中所有节点的分片。在节点出现故障或增加新节点的时候,
可以自动的将一个节点上的分片移动到另一个节点上。
13、Source field(源字段)
默认情况下,你的JSON文档将被索引存储在_source字段里面,所有的get(获取)和search(搜索)请求将返回的该字段。这将允许你直接从搜索结果中访问到源数据,而不需要再次发起请求检索。
注:索引将返回完整的的JSON字符串给你,即使它包含无效的JSON。此字段里的内容不表示任何该对象里面的数据如何被索引。
14、Term(术语)
在elasticsearch里,术语(term)是一个被索引的精确值。术语 foo, Foo,FOO 是不想等的。术语(即精确值)可以使用“term”查询接口来查询。
15、Text(文本)
文本(或全文)是普通非结构化的文本,如本段。默认情况下,文本将被分析成术语,术语才是实际存储在索引中。文本字段在索引时需要进行分析,
以便全文搜索,全文查询的关键字在搜索时,必须分析产生(搜索)与索引时相同的术语。
16、Type(类型)
Type是相当于关系数据库中的“表”。每种类型都有一列字段,用来定义文档的类型。映射定义了对在文档中的每个字段如何进行分析。
搜索数据结构如下:

总结
1、Cluster包含多个node,Indices不应该理解成动词索引,Indices可理解成关系数据库中的databases,Indices可包含多个Index,Index对应关系数据库中的database,它是用来存储相关文档的。
document的可以理解为一个JSON序列对象。每个document可包含多个field。
Elasticsearch与关系数据的类比对应关系如下:
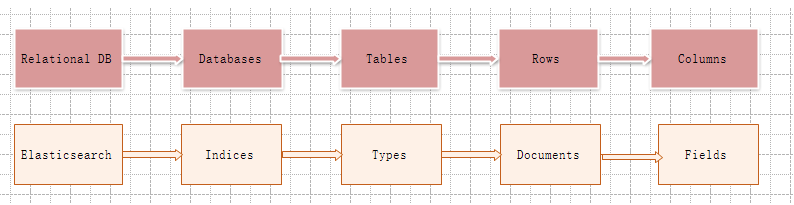
2、每个Index(对应Database)包含多个Shard,默认是5个,分散在不同的Node上,但不会存在两个相同的Shard存在一个Node上,这样就没有备份的意义了。Shard是一个最小的Lucene索引单元。
当来一个document的时候,Elasticsearch通过对docid进行hash来确定其放在哪个shard上面,然后在shard上面进行索引存储。
Replicas就是备份,Elasticsearch采用的是PushReplication模式,当你往 master主分片上面索引一个文档,该分片会复制该文档(document)到剩下的所有 replica副本分片中,这些分片也会索引这个文档。
3、当进行查询时,如果提供了查询的DocID,Elasticsearch通过hash就知道Doc存在哪个shard上面,再通过routingtable查询就知道再哪个node上面,让后去node上面去取就好了。
如果不提供DocID,那么Elasticsearch会在该Index(indics)shards所在的所有node上执行搜索预警,然后返回搜索结果,由coordinating node gather之后返回给用户。
ElasticSearch 专业术语的更多相关文章
- 大数据之kafka-02.搞定kafka专业术语
02.搞定kafka专业术语 在kafka的世界中有很多概念和术语是需要我们提前理解并且熟练掌握的,下面来盘点一下. 之前我们提到过,kafka属于分布式的消息引擎系统,主要功能是提供一套完善的消息发 ...
- AngularJS in Action读书笔记1——扫平一揽子专业术语
前(fei)言(hua): 数月前,以一个盲人摸象的姿态看了一些关于AngularJS的视频书籍,留下了我个人的一点或许是指点迷津或许是误人子弟的读后感.自以为已经达到熟悉ng的程度,但是因为刚入公司 ...
- 学习PS必须弄懂的专业术语
在学习PS的过程中,我们经常会遇到一些专业术语,下面我们来对一些常用的.比较难理解的术语进行简单讲解. 像素:像素是构成图像的最基本元素,它实际上是一个个独立的小方格,每个像素都能记录它所在的位置和颜 ...
- ANTLR v4 专业术语集
记录<The Definitive ANTLR 4 Reference>中出现的专业术语: grammar 文法,一种形式化(formal)的语言描述. syntax 语法 phrase ...
- LoRa---她的简介和她的专业术语
LoRa是LPWAN(低功耗广域网)通信技术的一种,其作用距离超过 15 公里,连接节点可达 100 万个.低功耗与长距离极限的组合可将最大数据速率提升至每秒 50千比特(Kbps). LoRa 是 ...
- HR,OA,CRM,DRP,ERP什么意思?电商行业的特点?电商行业模式?专业术语?
HR,OA,CRM,DRP,ERP HR----Human Resource人力资源管理 OA----Office Automation办公自动化 CRM---Customer Relationshi ...
- SAP模块一句话入门(专业术语的理解)
SAP模块一句话入门(专业术语的理解) SAP一句话入门:Financial & Controlling Accounting (FICO) 财务,财务,呵呵,让我们关心一下给我发工资的部门. ...
- Android开发 音视频开发需要了解的专业术语知识
前言 在摸索一段时间的音视频开发后,越来越发现这个坑的深度真是特别的深. 除了了解Android自带的音视频处理API以外,还得了解一些视频与音频方面的知识.这篇博客就是主要讲解这方面的专业术语.内容 ...
- 第2节 storm实时看板案例:11、实时看板综合案例工程构建,redis的专业术语
redis当中的一些专业术语: redis缓存击穿 redis缓存雪崩 redis的缓存淘汰 =========================================== 详见代码
随机推荐
- 自动驾驶缺人才?听听David Silver怎么说!
如今自动驾驶在全球范围内的发展势头愈发“凶猛”,该领域人才也一度被视为“香饽饽”. 即使在美国,自动驾驶工程师的起薪也已经突破了25万美元,我国‘“开价”之高更是令人咋舌. 人才.人才.还是人才!重要 ...
- 动态规划DP的斜率优化 个人浅解 附HDU 3669 Cross the Wall
首先要感谢叉姐的指导Orz 这一类问题的DP方程都有如下形式 dp[i] = w(i) + max/min(a(i)*b(j) + c(j)) ( 0 <= j < i ) 其中,b, c ...
- 【CF Round 439 B. The Eternal Immortality】
time limit per test 1 second memory limit per test 256 megabytes input standard input output standar ...
- Codeforces 938.B Run For Your Prize
B. Run For Your Prize time limit per test 1 second memory limit per test 256 megabytes input standar ...
- [网络流24题] COGS 运输问题1
11. 运输问题1 ★★☆ 输入文件:maxflowa.in 输出文件:maxflowa.out 简单对比时间限制:1 s 内存限制:128 MB [问题描述] 一个工厂每天生 ...
- python 使用urllib2下载文件
#! usr/bin/python #coding=utf-8 import urllib2 fp = open('test', 'wb') req = urllib2.urlopen('http:/ ...
- 《Linux命令、编辑器与shell编程》第三版 学习笔记---003 使用multibootusb
1.下载文件https://codeload.github.com/mbusb/multibootusb-8.9.0.tar.gz,使用命令: tar xvf multibootusb-8.9.0.t ...
- C++ 调节PCM音频音量大小
在用解码器解码音频数据得到PCM音频数据块之后,可以在将数据送给声卡播放之前调节其音量大小,具体的实现函数如下: void RaiseVolume(char* buf, UINT32 size, UI ...
- 9.OpenStack安装web界面
安装仪表板 安装仪表板组件 yum install -y openstack-dashboard httpd mod_wsgi memcached python-memcached 编辑/etc/op ...
- Selenium2+python自动化17-JS处理滚动条【转载】
前言 selenium并不是万能的,有时候页面上操作无法实现的,这时候就需要借助JS来完成了. 常见场景: 当页面上的元素超过一屏后,想操作屏幕下方的元素,是不能直接定位到,会报元素不可见的. 这时候 ...