JUC源码分析-集合篇(三)ConcurrentLinkedQueue
JUC源码分析-集合篇(三)ConcurrentLinkedQueue
在并发编程中,有时候需要使用线程安全的队列。如果要实现一个线程安全的队列有两种方式:一种是使用阻塞算法,另一种是使用非阻塞算法。使用阻塞算法的队列可以用一个锁(入队和出队用同一把锁)或两个锁(入队和出队用不同的锁)等方式来实现。非阻塞的实现方
式则可以使用循环 CAS 的方式来实现。本节让我们一起来研究一下 Doug Lea 是如何使用非阻塞的方式来实现线程安全队列 ConcurrentLinkedQueue 的,相信从大师身上我们能学到不少并发编程的技巧。
ConcurrentLinkedQueue先进先出(FIFO)单向队列ConcurrentLinkedDeque双向队列
下面以 ConcurrentLinkedQueue 为例看使用非阻塞算法(CAS) 保证线程安全。
1. 数据结构
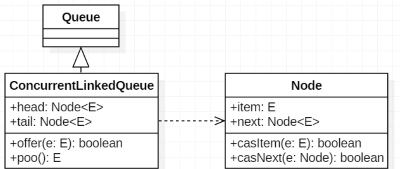
ConcurrentLinkedQueue 由 head 节点和 tail 节点组成,每个节点(Node)由节点元素(item)和
指向下一个节点(next)的引用组成,节点与节点之间就是通过这个 next 关联起来,从而组成一
张链表结构的队列。默认情况下 head 节点存储的元素为空,tail 节点等于 head 节点。head、tail 以及 Node.item、Node.next 都是 volatile 修辞。
private transient volatile Node<E> head;
private transient volatile Node<E> tail;
private static class Node<E> {
volatile E item;
volatile Node<E> next;
}
默认情况下 head、tail 都是空节点。
public ConcurrentLinkedQueue() {
head = tail = new Node<E>(null);
}
获取一个节点的后继节点
// 遇到哨兵节点,从 head 开始遍历
final Node<E> succ(Node<E> p) {
Node<E> next = p.next;
return (p == next) ? head : next;
}
2. 入队 offer
入队列就是将入队节点添加到队列的尾部。为了方便理解入队时队列的变化,以及 head 节点和 tail 节点的变化,每添加一个节点我就做了一个队列的快照图(注意这是单线程入队情况)。
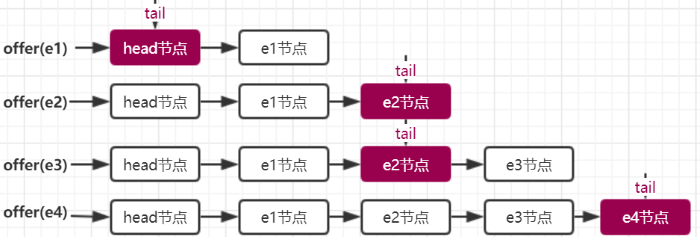
第一步添加元素 e1。队列更新 head 节点的 next 节点为元素 e1 节点。又因为 tail 节点默认情况下等于 head 节点,所以它们的 next 节点都指向元素 e1 节点。
第二步添加元素 e2。队列首先设置元素 e1 节点的 next 节点为元素 e2 节点,然后更新 tail 节点指向元素 e2 节点。
第三步添加元素 e3,设置 tail 节点的next节点为元素 e3 节点。
第四步添加元素 e4,设置元素 e3 的 next 节点为元素 e4 节点,然后将 tail 节点指向元素 e4 节点。
通过 debug 入队过程并观察 head 节点和 tail 节点的变化,发现入队主要做两件事情,第一是将入队节点设置成当前队列尾节点的下一个节点。第二是更新 tail 节点,如果 tail 节点的 next 节点不为空,则将入队节点设置成 tail 节点,如果 tail 节点的 next 节点为空,则将入队节点设置成 tail 的 next 节点,所以 tail 节点不总是尾节点,理解这一点对于我们研究源码会非常有帮助。
上面的分析让我们从单线程入队的角度来理解入队过程,但是多个线程同时进行入队情况就变得更加复杂,因为可能会出现其他线程插队的情况。如果有一个线程正在入队,那么它必须先获取尾节点,然后设置尾节点的下一个节点为入队节点,但这时可能有另外一个线程插队了,那么队列的尾节点就会发生变化,这时当前线程要暂停入队操作,然后重新获取尾节点。让我们再通过源码来详细分析下它是如何使用CAS算法来入队的。
public boolean offer(E e) {
checkNotNull(e);
final Node<E> newNode = new Node<E>(e);
for (Node<E> t = tail, p = t;;) {
Node<E> q = p.next;
// 1. p is last node
if (q == null) {
// 1.1 通过自旋保证节点一定添加到数据链中
if (p.casNext(null, newNode)) {
// 1.2 p代表当前结点,当前节点不是尾节点时更新
// 也就是说tail不一定是尾节点,尾节点为tail或tail.next
// 更新失败了也没关系,因为失败了表示有其他线程成功更新了tail节点
if (p != t) // hop two nodes at a time
casTail(t, newNode); // Failure is OK.
return true;
}
// Lost CAS race to another thread; re-read next
}
// 2. 遇到哨兵节点,从 head 开始遍历
// 但是如果 tail 被修改,则使用 tail(因为可能被修改正确了)
else if (p == q)
p = (t != (t = tail)) ? t : head;
// 3. 尾节点只可能是tail或tail.next。如果tail发生变化则直接从tail开始遍历
else
// Check for tail updates after two hops.
// 其实我认为这里一直取p.next节点遍历最终可以遍历到尾节点,可以不必取重新tail
// 可能重新取tail会遍历更快
p = (p != t && t != (t = tail)) ? t : q;
}
}
3. hops 设计意图
上面分析我们知道真正的尾节点可能 tail 或 tail.next,doug lea 写的代码和逻辑还是稍微有点复杂。那么可不可以让 tail 永远指向尾节点呢?代码如下
public boolean offer(E e) {
Node n = new Node(e);
for (;;) {
Node</e><e> t = tail;
if (t.casNext(null, n) && casTail(t, n)) {
return true;
}
}
}
让 tail 节点永远作为队列的尾节点,这样实现代码量非常少,而且逻辑非常清楚和易懂。但是这么做有个缺点就是每次都需要使用循环 CAS 更新 tail 节点,如果能减少 CAS 更新 tail 节点的次数,就能提高入队的效率。
所以 doug lea 使用 hops 变量(JDK1.8没有直接使用hops,但逻辑没有改变)来控制并减少 tail 节点的更新频率,并不是每次节点入队后都将 tail 节点更新成尾节点,而是当 tail 节点和尾节点的距离大于等于常量 HOPS 的值(默认等于1)时才更新 tail 节点,tail 和尾节点的距离越长使用 CAS 更新 tail 节点的次数就会越少,但是距离越长带来的负面效果就是每次入队时定位尾节点的时间就越长,因为循环体需要多循环一次来定位出尾节点,但是这样仍然能提高入队的效率,因为从本质上来看它通过增加对 volatile 变量的读操作来减少了对 volatile 变量的写操作,而对 volatile 变量的写操作开销要远远大于读操作,所以入队效率会有所提升。
// JDK1.7 代码直接使用 hops 来控制
public boolean offer(E e) {
if (e == null) throw new NullPointerException();
Node<E> n = new Node<E>(e);
retry:
for (;;) {
Node<E> t = tail;
Node<E> p = t;
for (int hops = 0; ; hops++) {
// 获得p节点的下一个节点。
Node<E> next = succ(p);
// next节点不为空,说明p不是尾节点,需要更新p后在将它指向next节点
if (next != null) {
if (hops > HOPS && t != tail)
continue retry;
p = next;
} else if (p.casNext(null, n)) {
if (hops >= HOPS)
casTail(t, n); // 更新tail节点,允许失败
return true;
} else {
p = succ(p);
}
}
}
}
4. 出队列 poll
出队列的就是从队列里返回一个节点元素,并清空该节点对元素的引用。让我们通过每个节点出队的快照来观察下head节点的变化。
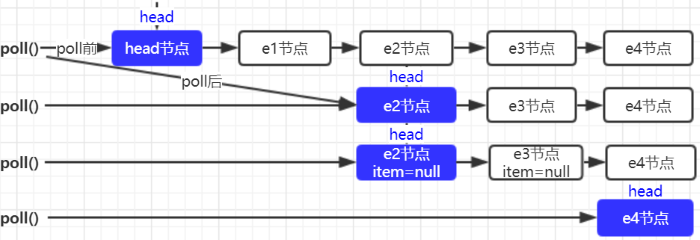
出队的代码和入队差不多,也有 hop 的概念。出队了完成了两件事:一是将节点的 item 设置为 null;二是更新头节点并将头节点的 next 指向自己,也就是哨兵节点。
public E poll() {
restartFromHead:
for (;;) {
for (Node<E> h = head, p = h, q;;) {
E item = p.item;
// 1. 出队后 p.item 一定为 null
if (item != null && p.casItem(item, null)) {
if (p != h) // hop two nodes at a time
// 更新头节点并将头节点的 next 指向自己。成为哨兵节点,等 GC 回收
// 同样允许失败,说明其它的线程更新了头节点
updateHead(h, ((q = p.next) != null) ? q : p);
return item;
// 2. 遍历到尾节点了,没有元素了
} else if ((q = p.next) == null) {
updateHead(h, p);
return null;
// 3. 出现哨兵节点,说明有其它线程poll后更新了head,需要重新从head开始遍历
} else if (p == q)
continue restartFromHead;
// 4. 继续遍历
else
p = q;
}
}
}
5. 其它常用方法
5.1 元素个数 size
// 可以看到 size 是一个很耗时的方法
public int size() {
int count = 0;
for (Node<E> p = first(); p != null; p = succ(p))
if (p.item != null)
if (++count == Integer.MAX_VALUE)
break;
return count;
}
5.1 元素是否为空 isEmpty
public boolean isEmpty() {
return first() == null;
}
如果只判断集合中是否存在元素请使用 isEmpty
5.3 查找第一个有效元素 first
// 从 head 开始遍历找到第一个 item!=null 的元素
Node<E> first() {
restartFromHead:
for (;;) {
for (Node<E> h = head, p = h, q;;) {
boolean hasItem = (p.item != null);
// 要么找到了 item!=null 的元素,要么遍历完整个链表
if (hasItem || (q = p.next) == null) {
updateHead(h, p);
return hasItem ? p : null;
} else if (p == q)
continue restartFromHead;
else
p = q;
}
}
}
5.4 查找后继节点 succ
// 遇到哨兵节点,从 head 开始遍历
final Node<E> succ(Node<E> p) {
Node<E> next = p.next;
return (p == next) ? head : next;
}
参考:
- 《Java并发编程的艺术》第六章
- 并发队列-无界非阻塞队列 ConcurrentLinkedQueue 原理探究(有节点变化图)
- 聊聊并发(六)ConcurrentLinkedQueue的实现原理分析
每天用心记录一点点。内容也许不重要,但习惯很重要!
JUC源码分析-集合篇(三)ConcurrentLinkedQueue的更多相关文章
- JUC源码分析-集合篇(十)LinkedTransferQueue
JUC源码分析-集合篇(十)LinkedTransferQueue LinkedTransferQueue(LTQ) 相比 BlockingQueue 更进一步,生产者会一直阻塞直到所添加到队列的元素 ...
- JUC源码分析-集合篇(六)LinkedBlockingQueue
JUC源码分析-集合篇(六)LinkedBlockingQueue 1. 数据结构 LinkedBlockingQueue 和 ConcurrentLinkedQueue 一样都是由 head 节点和 ...
- JUC源码分析-集合篇:并发类容器介绍
JUC源码分析-集合篇:并发类容器介绍 同步类容器是 线程安全 的,如 Vector.HashTable 等容器的同步功能都是由 Collections.synchronizedMap 等工厂方法去创 ...
- JUC源码分析-集合篇(九)SynchronousQueue
JUC源码分析-集合篇(九)SynchronousQueue SynchronousQueue 是一个同步阻塞队列,它的每个插入操作都要等待其他线程相应的移除操作,反之亦然.SynchronousQu ...
- JUC源码分析-集合篇(一)ConcurrentHashMap
JUC源码分析-集合篇(一)ConcurrentHashMap 1. 概述 <HashMap 源码详细分析(JDK1.8)>:https://segmentfault.com/a/1190 ...
- JUC源码分析-集合篇(八)DelayQueue
JUC源码分析-集合篇(八)DelayQueue DelayQueue 是一个支持延时获取元素的无界阻塞队列.队列使用 PriorityQueue 来实现. 队列中的元素必须实现 Delayed 接口 ...
- JUC源码分析-集合篇(七)PriorityBlockingQueue
JUC源码分析-集合篇(七)PriorityBlockingQueue PriorityBlockingQueue 是带优先级的无界阻塞队列,每次出队都返回优先级最高的元素,是二叉树最小堆的实现. P ...
- JUC源码分析-集合篇(四)CopyOnWriteArrayList
JUC源码分析-集合篇(四)CopyOnWriteArrayList Copy-On-Write 简称 COW,是一种用于程序设计中的优化策略.其基本思路是,从一开始大家都在共享同一个内容,当某个人想 ...
- JUC源码分析-线程池篇(三)ScheduledThreadPoolExecutor
JUC源码分析-线程池篇(三)ScheduledThreadPoolExecutor ScheduledThreadPoolExecutor 继承自 ThreadPoolExecutor.它主要用来在 ...
随机推荐
- CTF 密码学(一)
0x00 前言 为了练习python,强迫自己能用Python的题都用python解题还有各种密码 0x01 奇怪的字符串 实验吧题目:信息保密的需求和实际操作自古有之,与之相应的信息加密与解密也是历 ...
- VPS性能测试:CPU内存,硬盘IO读写,带宽速度,UnixBench和压力测试
现在便宜的VPS主机越来越多了,一些美国的VPS主机甚至给出1美元一月的VPS,堪比虚拟主机还要便宜,巨大的价格优势吸引不少人购买和使用,而近些年来国内的主机商也开始意识到便宜的VPS对草根站长的诱惑 ...
- PHP 3DES 加解密(CBC模式,pkcs5padding填充)
1.前言:项目中接入第三方支付遇到3DES加密,以前也没用过,搜了好多,都不适用,各种不对,后来自己结合搜到的终于弄正确了,检测地址:http://tool.chacuo.net/crypt3des. ...
- 使用soapui进行webservice接口测试
一.web service(SOAP)与HTTP接口的区别 1.什么是web service WebService就是Web服务的意思,对应的应用层协议为SOAP(相当于HTTP协议),可理解为远 ...
- Emacs安装配置全攻略之中的一个编译安装简单配置
/*************************************************************************************************** ...
- 一、最新Kafka单节点部署+测试 完整
每次学一个东西从基础的开始,循序渐进. 不急不躁,路还很长. 所有教程都是学习汪文君大神的kafka教程的. 一.部署 这里选的kafka版本是 0.10.2.1 下载连接 https://dow ...
- 微信小程序の页面路由
微信小程序的页面路由由平台已栈的形式管理. 微信小程序的页面为什么会如此特殊呢,因为可视区域始终只有一个页面. 一.小程序页面的路由方式 小程序页面有6种路由方式:初始化.打开新页面.页面重定向.页面 ...
- Mach-O简介及实际应用
一.前言 在正题开始之前,我们先来聊聊iOS中的hook技术.一谈到hook,很多人首先想到的是runtime,runtime确实强大,但是它存在很多局限性: 1).侵入性:一旦hook了某个类的 ...
- 【记录】VScode快捷键大全
记住快捷键能够提高工作效率 Ctrl+Shift+P,F1 展示全局命令面板 Ctrl+P 快速打开最近打开的文件 Ctrl+Shift+N 打开新的编辑器窗口 Ctrl+Shift+W 关闭编辑器 ...
- linux 7 安装KVM
首先,在安装GUI的linux 7系统下,安装KVM 执行命令 #yum install qemu-kvm qemu-kvm-tools virt-manager libvirt virt-insta ...