SpringBoot 集成 Elasticsearch
前面在 ubuntu 完成安装 elasticsearch,现在我们SpringBoot将集成elasticsearch。
1、创建SpringBoot项目
我们这边直接引入NoSql中Spring Data Elasticsearch启动器。
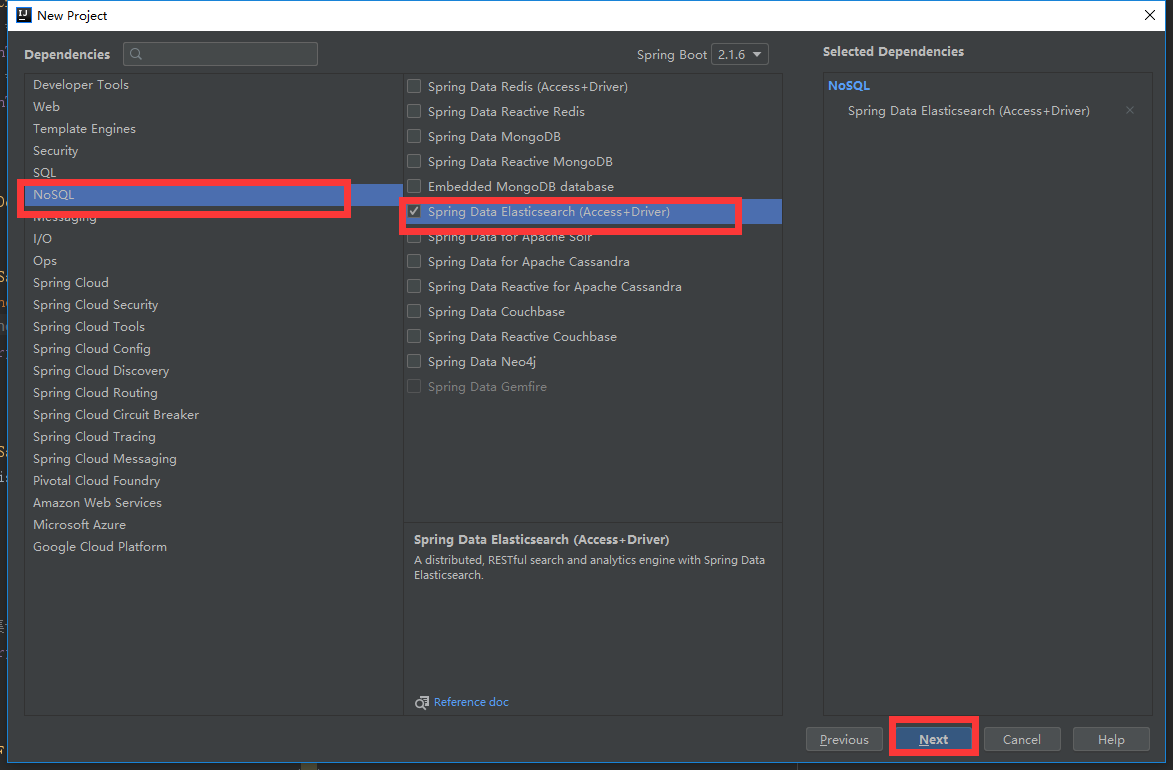
创建项目完成后。
项目结构:
pom文件:(新增 lombok 简化pojo)
<?xml version="1.0" encoding="UTF-8"?>
<project xmlns="http://maven.apache.org/POM/4.0.0" xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 http://maven.apache.org/xsd/maven-4.0.0.xsd">
<modelVersion>4.0.0</modelVersion>
<parent>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-parent</artifactId>
<version>2.1.6.RELEASE</version>
<relativePath/> <!-- lookup parent from repository -->
</parent>
<groupId>com.yatces.elasticsearch</groupId>
<artifactId>elasticsearch-demo</artifactId>
<version>0.0.1-SNAPSHOT</version>
<name>elasticsearch-demo</name>
<description>Demo project for Spring Boot</description> <properties>
<java.version>1.8</java.version>
</properties> <dependencies>
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-data-elasticsearch</artifactId>
</dependency> <dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-test</artifactId>
<scope>test</scope>
</dependency>
<!-- https://mvnrepository.com/artifact/org.projectlombok/lombok -->
<dependency>
<groupId>org.projectlombok</groupId>
<artifactId>lombok</artifactId>
<version>1.16.20</version>
<scope>provided</scope>
</dependency> </dependencies> <build>
<plugins>
<plugin>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-maven-plugin</artifactId>
</plugin>
</plugins>
</build> </project>
2、添加 elasticsearch 配置
本人习惯 yml 文件,将 application.properties 重命名为 application.yml
spring:
data:
elasticsearch:
cluster-name: elasticsearch
cluster-nodes: 192.168.78.130:
3、新增实体类
@Data
@NoArgsConstructor
@AllArgsConstructor
@Document(indexName = "product",type = "item",shards = 1,replicas = 0)
public class Item { @Id
Long id;
@Field(type = FieldType.Text,analyzer = "ik_max_word")
String title; //标题
@Field(type = FieldType.Keyword)
String category;// 分类
@Field(type = FieldType.Keyword)
String brand; // 品牌
@Field(type = FieldType.Double)
Double price; // 价格
@Field(index = false, type = FieldType.Keyword)
String images; // 图片地址
}
主要注解:
@Document 作用在类,标记实体类为文档对象,一般有四个属性
indexName:对应索引库名称
type:对应在索引库中的类型
shards:分片数量,默认5
replicas:副本数量,默认1
@Id 作用在成员变量,标记一个字段作为id主键
@Field 作用在成员变量,标记为文档的字段,并指定字段映射属性:
type:字段类型,取值是枚举:FieldType
index:是否索引,布尔类型,默认是true
store:是否存储,布尔类型,默认是false
analyzer:分词器名称:ik_max_word
4、编写测试
4.1新建ItemTest
用于测试 elasticsearch 的使用,使用 ElasticsearchTemplate 操作索引。
@RunWith(SpringRunner.class)
@SpringBootTest(classes = ElasticsearchDemoApplication.class)
public class ItemTest {
@Autowired
private ElasticsearchTemplate elasticsearchTemplate;
}
4.2创建索引和映射
@Test
public void testCreate(){
// 创建索引,会根据Item类的@Document注解信息来创建
elasticsearchTemplate.createIndex(Item.class);
// 配置映射,会根据Item类中的id、Field等字段来自动完成映射
elasticsearchTemplate.putMapping(Item.class);
}
在 Kibana通过 GET product/_mapping 查询结果
{
"product": {
"mappings": {
"item": {
"properties": {
"brand": {
"type": "keyword"
},
"category": {
"type": "keyword"
},
"images": {
"type": "keyword",
"index": false
},
"price": {
"type": "double"
},
"title": {
"type": "text",
"analyzer": "ik_max_word"
}
}
}
}
}
}
4.3删除索引
@Test
public void testDelete(){
//elasticsearchTemplate.deleteIndex(Item.class);
// indexName = "product"
elasticsearchTemplate.deleteIndex("product");
}
Kibana 再次查询,报404。
{
"error": {
"root_cause": [
{
"type": "index_not_found_exception",
"reason": "no such index",
"resource.type": "index_or_alias",
"resource.id": "product",
"index_uuid": "_na_",
"index": "product"
}
],
"type": "index_not_found_exception",
"reason": "no such index",
"resource.type": "index_or_alias",
"resource.id": "product",
"index_uuid": "_na_",
"index": "product"
},
"status": 404
}
4.4新建 ItemRepository
用于对 document 的操作测试
public interface ItemRepository extends ElasticsearchRepository<Item, Long>{
}
在 ItemTest 中注入 ItemRepository
@Autowired
private ItemRepository itemRepository;
4.5新增文档
修改和新增是同一个接口,区分的依据就是id,新增用POST 请求,修改用PUT请求。
@Test
public void testSaveDocument(){
Item item = new Item(1L, "小米手机7", " 手机", "小米", 3499.00, "13123.jpg");
itemRepository.save(item);
}
Kibana 通过GET product/_search 查询
{
"took": 1,
"timed_out": false,
"_shards": {
"total": 1,
"successful": 1,
"skipped": 0,
"failed": 0
},
"hits": {
"total": 1,
"max_score": 1,
"hits": [
{
"_index": "product",
"_type": "item",
"_id": "1",
"_score": 1,
"_source": {
"id": 1,
"title": "小米手机7",
"category": " 手机",
"brand": "小米",
"price": 3499,
"images": "13123.jpg"
}
}
]
}
}
4.6批量新增
@Test
public void testSaveDocumentList() {
List<Item> list = new ArrayList<>();
list.add(new Item(1L, "小米手机7", "手机", "小米", 3299.00, "13123.jpg"));
list.add(new Item(2L, "坚果手机R1", "手机", "锤子", 3699.00, "13123.jpg"));
list.add(new Item(3L, "华为META10", "手机", "华为", 4499.00, "13123.jpg"));
list.add(new Item(4L, "小米Mix2S", "手机", "小米", 4299.00, "13123.jpg"));
list.add(new Item(5L, "荣耀V10", "手机", "华为", 2799.00, "13123.jpg"));
// 接收对象集合,实现批量新增
itemRepository.saveAll(list);
}
Kibana 通过GET product/_search 再次查询,得到5个doc
4.7基本查询
在 ElasticsearchRepository 继承下来的查询方法
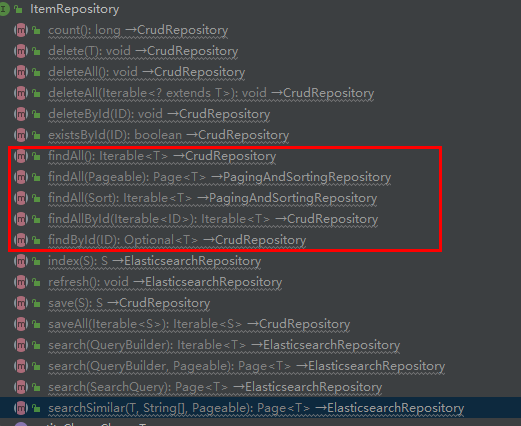
4.7.1根据Id查询
@Test
public void testFindById(){
Optional<Item> optional = itemRepository.findById(1l);
System.out.println(optional.get());
}
结果

4.7.2查询所有
@Test
public void testFindAll(){
// 查询所有,并根据 price 降序排序
Iterable<Item> items = itemRepository.findAll(Sort.by(Sort.Direction.DESC,"price"));
items.forEach(System.out::println);
}
结果

4.8自定义方法
Spring Data 的提供一个强大功能,是根据方法名称自动实现功能,下述自定义规范:


在ItemRepository定义一个方法findByPriceBetween,不用写这个方法的实现例如:根据价格区间查询所有 item
/**
* 根据价格区间查询
* @param price1
* @param price2
* @return
*/
List<Item> findByPriceBetween(double price1, double price2);
在 ItemTest 编写测试
@Test
public void testFindByPriceBetween(){
List<Item> list = this.itemRepository.findByPriceBetween(4000.00, 5000.00);
list.forEach(System.out::println);
}
结果

4.9高级查询
4.9.1基本查询
Repository 的 search 方法,使用 QueryBuilders 构建查询条件
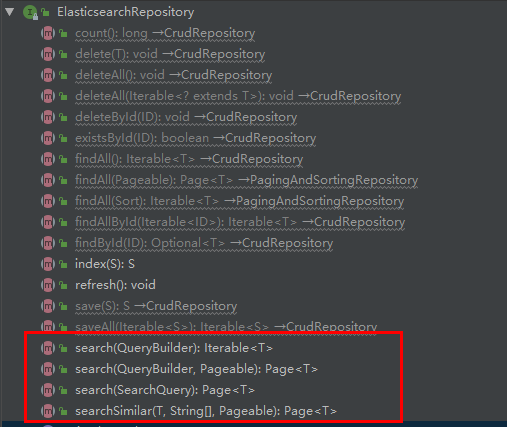
QueryBuilders 提供了大量的静态方法,用于生成各种不同类型的查询对象,例如:词条、模糊、通配符等QueryBuilder对象
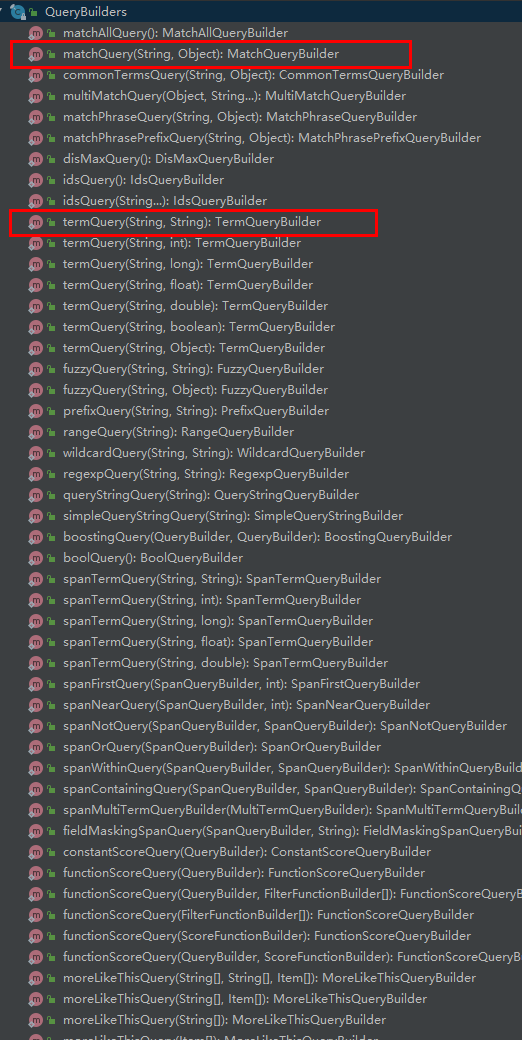
public void testQuery(){
// 词条查询
MatchQueryBuilder queryBuilder = QueryBuilders.matchQuery("title", "小米");
// 执行查询
Iterable<Item> items = this.itemRepository.search(queryBuilder);
items.forEach(System.out::println);
}
结果

4.9.2自定义查询
@Test
public void testNativeQuery(){
// 构建查询条件
NativeSearchQueryBuilder queryBuilder = new NativeSearchQueryBuilder();
// 添加基本的分词查询
queryBuilder.withQuery(QueryBuilders.matchQuery("title", "小米"));
// 执行搜索,获取结果
Page<Item> items = this.itemRepository.search(queryBuilder.build());
// 打印总条数
System.out.println(items.getTotalElements());
// 打印总页数
System.out.println(items.getTotalPages());
items.forEach(System.out::println);
}
结果

NativeSearchQueryBuilder:Spring提供的一个查询条件构建器,帮助构建json格式的请求体。
Page<item>:默认是分页查询,因此返回的是一个分页的结果对象,包含属性:
totalElements:总条数
totalPages:总页数
Iterator:迭代器,本身实现了Iterator接口,因此可直接迭代得到当前页的数据
4.9.3分页查询
利用NativeSearchQueryBuilder可以方便的实现分页
@Test
public void testNativePageQuery(){
// 构建查询条件
NativeSearchQueryBuilder queryBuilder = new NativeSearchQueryBuilder();
// 添加基本的分词查询
queryBuilder.withQuery(QueryBuilders.termQuery("category", "手机")); // 初始化分页参数
int page = 0;
int size = 3;
// 设置分页参数
queryBuilder.withPageable(PageRequest.of(page, size)); // 执行搜索,获取结果
Page<Item> items = this.itemRepository.search(queryBuilder.build());
// 打印总条数
System.out.println("总条数:"+items.getTotalElements());
// 打印总页数
System.out.println("总页数:"+items.getTotalPages());
// 每页大小
System.out.println("每页大小:"+items.getSize());
// 当前页
System.out.println("当前页:"+items.getNumber());
items.forEach(System.out::println);
}
结果:分页是从第0页开始

4.9.4排序
排序也通用通过NativeSearchQueryBuilder完成
@Test
public void testSortQuery(){
// 构建查询条件
NativeSearchQueryBuilder queryBuilder = new NativeSearchQueryBuilder();
// 添加基本的分词查询
queryBuilder.withQuery(QueryBuilders.termQuery("category", "手机")); // 排序
queryBuilder.withSort(SortBuilders.fieldSort("price").order(SortOrder.DESC)); // 执行搜索,获取结果
Page<Item> items = this.itemRepository.search(queryBuilder.build());
// 打印总条数
System.out.println("总条数:"+items.getTotalElements());
items.forEach(System.out::println);
}
结果

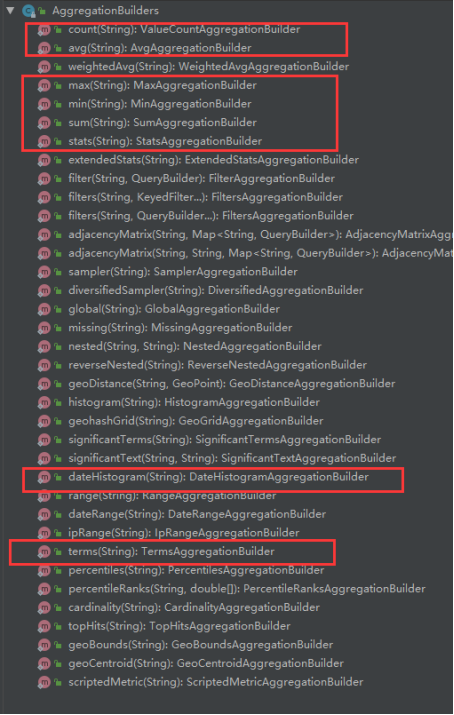
4.10聚合
4.10.1普通聚合
按照品牌brand进行分组
@Test
public void testBrandAgg(){
NativeSearchQueryBuilder queryBuilder = new NativeSearchQueryBuilder();
// 不查询任何结果
queryBuilder.withSourceFilter(new FetchSourceFilter(new String[]{""}, null));
// 1、添加一个新的聚合,聚合类型为terms,聚合名称为brands,聚合字段为brand
queryBuilder.addAggregation(
AggregationBuilders.terms("brands").field("brand"));
// 2、查询,需要把结果强转为AggregatedPage类型
AggregatedPage<Item> aggPage = (AggregatedPage<Item>) this.itemRepository.search(queryBuilder.build());
// 3、解析
// 3.1、从结果中取出名为brands的那个聚合,
// 因为是利用String类型字段来进行的term聚合,所以结果要强转为StringTerm类型
StringTerms agg = (StringTerms) aggPage.getAggregation("brands");
// 3.2、获取桶
List<StringTerms.Bucket> buckets = agg.getBuckets();
// 3.3、遍历
for (StringTerms.Bucket bucket : buckets) {
// 3.4、获取桶中的key,即品牌名称 和 文档数量
System.out.println(bucket.getKeyAsString() + ":" +bucket.getDocCount());
}
}
结果

AggregationBuilders.terms("brands").field("brand") 聚合的构建工厂类AggregationBuilders,所有聚合都由这个类来构建
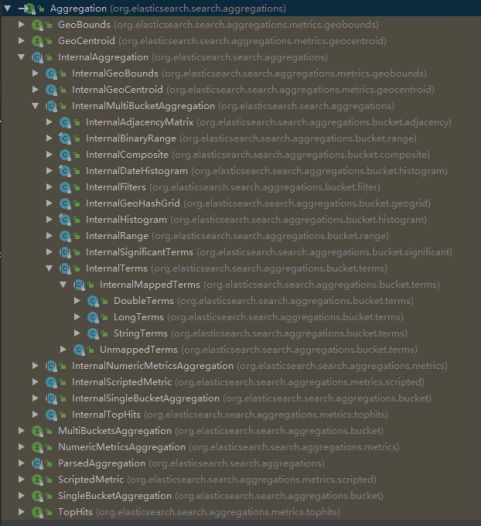
aggPage.getAggregation("brands")返回的结果都是Aggregation类型对象,不过根据字段类型不同,又有不同的子类表示
4.10.2嵌套聚合
@Test
public void testSubAvgAgg(){
NativeSearchQueryBuilder queryBuilder = new NativeSearchQueryBuilder();
// 不查询任何结果
queryBuilder.withSourceFilter(new FetchSourceFilter(new String[]{""}, null));
// 1、添加一个新的聚合,聚合类型为terms,聚合名称为brands,聚合字段为brand
queryBuilder.addAggregation(
AggregationBuilders.terms("brands").field("brand")
.subAggregation(AggregationBuilders.avg("avgPrice").field("price")) // 在品牌聚合桶内进行嵌套聚合,求平均值
);
// 2、查询,需要把结果强转为AggregatedPage类型
AggregatedPage<Item> aggPage = (AggregatedPage<Item>) this.itemRepository.search(queryBuilder.build());
// 3、解析
// 3.1、从结果中取出名为brands的那个聚合,
// 因为是利用String类型字段来进行的term聚合,所以结果要强转为StringTerm类型
StringTerms agg = (StringTerms) aggPage.getAggregation("brands");
// 3.2、获取桶
List<StringTerms.Bucket> buckets = agg.getBuckets();
// 3.3、遍历
buckets.forEach(bucket -> {
// 3.4、获取桶中的key,即品牌名称 ; 获取桶中的文档数量 ;获取平均值结果:
InternalAvg avg = (InternalAvg) bucket.getAggregations().asMap().get("avgPrice");
System.out.println(bucket.getKeyAsString() + "共" + bucket.getDocCount() +",平均售价:"+ avg.getValue() );
});
}
结果

SpringBoot 集成 Elasticsearch的更多相关文章
- springboot集成elasticsearch
在基础阶段学习ES一般是首先是 安装ES后借助 Kibana 来进行CURD 了解ES的使用: 在进阶阶段可以需要学习ES的底层原理,如何通过Version来实现乐观锁保证ES不出问题等核心原理: 第 ...
- springboot 集成elasticsearch
In this article, we will discuss about “How to create a Spring Boot + Spring Data + Elasticsearch Ex ...
- ElasticSearch(八):springboot集成ElasticSearch集群并使用
1. 集群的搭建 见:ElasticSearch(七) 2. springboot配置集群 2.1 创建springboot项目,使用idea创建,不过多介绍(创建项目时候建议不要勾选elastics ...
- springBoot集成Elasticsearch抛出Factory method 'restHighLevelClient' threw exception; nested exception is java.lang.NoSuchFieldError: IGNORE_DEPRECATIONS
org.springframework.beans.factory.BeanCreationException: Error creating bean with name 'restHighLeve ...
- ElasticSearch(十):springboot集成ElasticSearch集群完成数据的增,删,改
前言 之前介绍了使用devTools进行索引库数据的crud,这里使用的是java程序,使用中间件activeMQ进行数据库和索引库数据的同步.主要是用来完成对数据库的修改来完成对索引库的同步. 正文 ...
- Springboot 集成 ElasticSearch 踩坑
这里只涉及到基础使用 导包 <dependency> <groupId>org.springframework.boot</groupId> <artifac ...
- SpringBoot 集成Elasticsearch进行简单增删改查
一.引入的pom文件 <?xml version="1.0" encoding="UTF-8"?> <project xmlns=" ...
- springboot集成elasticsearch遇到的问题
public interface EsBlogRepository extends ElasticsearchRepository<EsBlog,String>{ Page<EsBl ...
- springboot集成elk 一: springboot + Elasticsearch
1.ELK介绍 1> Elasticsearch是实时全文搜索和分析引擎, 提供搜集.分析.存储数据三大功能: 是一套开放REST和JAVA API等结构提供高效搜索功能,可扩展的分布式系统. ...
随机推荐
- [kmp,不要过多调用strlen!!!] Codeforces 1200E Compress Words
题目:http://codeforces.com/contest/1200/problem/E Compress Words time limit per test 1 second memory l ...
- IO多路复用(IO Multiplexing)
什么是IO多路复用 为什么要有IO多路复用 作者总结 遵循学习新知识的三部曲:是什么?为什么?怎么用? 作者前言:IO多路复用本质上是网络通信过程中的一个技术名词. 什么是IO多路复用 一个用机场管理 ...
- Apache服务器故障排除攻略
Apache服务器故障排除攻略 应用服务器Apache浏览器配置管理网络应用 随着网络技术的普及.应用和Web技术的不断完善,Web服务已经成为互联网上重要的服务形式之一.原有的客户端/服务器模式正 ...
- 使用PyTorch建立图像分类模型
概述 在PyTorch中构建自己的卷积神经网络(CNN)的实践教程 我们将研究一个图像分类问题--CNN的一个经典和广泛使用的应用 我们将以实用的格式介绍深度学习概念 介绍 我被神经网络的力量和能力所 ...
- 服务器上安装.NET Framework 3.5 sp1
操作系统是Windows Server 2008 R2 或 Windows Server 2012 或 Windows Server 2012 R2,可以直接进入“服务器管理器”添加“功能”.
- ssh-add和ssh-agent
注: 因为在ssh-agent异常关闭或者新开窗口是会导致ssh-add找不到私钥,导致添加的私钥无效,所以下面使用keychain管理 ssh-add 参数 -l 查看代理中的私钥 -L 查看代理中 ...
- js定时器及定时器叠加问题
回武汉隔离的第二天打卡,武汉加油,逆战必胜!今天想和大家简单聊一下js定时器的问题. 1.setTimeout 延时器 在指定时间后执行一次,注意只会执行一次 当然有的时候我们想用延时器做出定时器的效 ...
- MATLAB实现一个EKF-2D-SLAM(已开源)
1. SLAM问题定义 同时定位与建图(SLAM)的本质是一个估计问题,它要求移动机器人利用传感器信息实时地对外界环境结构进行估计,并且估算出自己在这个环境中的位置,Smith 和Cheeseman在 ...
- 手工注入——sql server (mssql)注入实战和分析
前言 首先要对sql server进行初步的了解.常用的全部变量@@version:返回当前的Sql server安装的版本.处理器体系结构.生成日期和操作系统.@@servername:放回运行Sq ...
- 除了chrome、Firefox之外其他浏览器全都连不上网
在调试jsp时,总是会遇到eclipse打开jsp网页失败,没有网络,浏览器也除了chrome.Firefox之外其他浏览器全都连不上网,这里我也不清楚是什么问题,但是解决方法是: 打开Interne ...