Redis的三大问题
一般我们对缓存读操作的时候有这么一个固定的套路:
- 如果我们的数据在缓存里边有,那么就直接取缓存的。
- 如果缓存里没有我们想要的数据,我们会先去查询数据库,然后将数据库查出来的数据写到缓存中。
- 最后将数据返回给请求
代码例子:
@Override
public R selectOrderById(Integer id) {
//查询缓存
Object redisObj = valueOperations.get(String.valueOf(id)); //命中缓存
if(redisObj != null) {
//正常返回数据
return new R().setCode(200).setData(redisObj).setMsg("OK");
}
Order order = orderMapper.selectOrderById(id);
if (order != null) {
valueOperations.set(String.valueOf(id), order); //加入缓存
return new R().setCode(200).setData(order).setMsg("OK");
}
return new R().setCode(500).setData(new NullValueResultDO()).setMsg("查询无果");
}
但这样写的代码是不行的,这代码里就有我们缓存的三大问题的两大问题.穿透,击穿.
一,缓存雪崩
1.1什么是缓存雪崩?
第一种情况:Redis挂掉了,请求全部走数据库.
第二种情况:缓存数据设置的过期时间是相同的,然后刚好这些数据删除了,全部失效了,这个时候全部请求会到数据库
缓存雪崩如果发生了,很有可能会把我们的数据库搞垮,导致整个服务器瘫痪.
1.2如何解决缓存雪崩?
对于第二种情况,非常好解决:
在存缓存的时候给过期时间加上一个随机值,这样大幅度的减少缓存同时过期.
第一种情况:
事发前:实现Redis的高可用(主从架构+Sentinel 或者Redis Cluster),尽量避免Redis挂掉这种情况发生。
事发中:万一Redis真的挂了,我们可以设置本地缓存(ehcache)+限流(hystrix),尽量避免我们的数据库被干掉(起码能保证我们的服务还是能正常工作的)
事发后:redis持久化,重启后自动从磁盘上加载数据,快速恢复缓存数据。
二,缓存穿透
2.1什么是缓存穿透?
比如你抢了你同事的女神,你同事很气,想搞你,在你的项目里,每次请求的ID为负数.这个时候缓存肯定是没有的,缓存就没用了,请求就会全部找数据库,但数据库也没用这个值.所以每次返回空出去.
缓存穿透是指查询一个一定不存在的数据。由于缓存不命中,并且出于容错考虑,如果从数据库查不到数据则不写入缓存,这将导致这个不存在的数据每次请求都要到数据库去查询,失去了缓存的意义。
这就是缓存穿透:
请求的数据在缓存大量不命中,导致请求走数据库。
缓存穿透如果发生了,也可能把我们的数据库搞垮,导致整个服务瘫痪!
2.2如何解决缓存穿透?
解决缓存穿透也有两种方案:
- 由于请求的参数是不合法的(每次都请求不存在的参数),于是我们可以使用布隆过滤器(BloomFilter)或者压缩filter提前拦截,不合法就不让这个请求到数据库层!
- 当我们从数据库找不到的时候,我们也将这个空对象设置到缓存里边去。下次再请求的时候,就可以从缓存里边获取了。这种情况我们一般会将空对象设置一个较短的过期时间。
缓存空对象代码例子:
public R selectOrderById(Integer id) {
return cacheTemplate.redisFindCache(String.valueOf(id), 10, TimeUnit.MINUTES, new CacheLoadble<Order>() {
@Override
public Order load() {
return orderMapper.selectOrderById(id);
}
},false);
}
public R redisFindCache(String key, long expire, TimeUnit unit, CacheLoadble<T> cacheLoadble, boolean b) {
//查询缓存
Object redisObj = valueOperations.get(String.valueOf(key));
//命中缓存
if (redisObj != null) {
if(redisObj instanceof NullValueResultDO){
return new R().setCode(500).setData(new NullValueResultDO()).setMsg("查询无果");
}
//正常返回数据
return new R().setCode(200).setData(redisObj).setMsg("OK");
}
try {
T load = cacheLoadble.load();//查询数据库
if (load != null) {
valueOperations.set(key, load, expire, unit); //加入缓存
return new R().setCode(200).setData(load).setMsg("OK");
}else{
valueOperations.set(key,new NullValueResultDO(),expire,unit);
}
} finally {
}
return new R().setCode(500).setData(new NullValueResultDO()).setMsg("查询无果");
}
这里封装了一个模板redisFindCache,不然每一个方法都要写这个流程.注意在命中缓存时,要判断数据是否是空对象.
空对象:
@Getter
@Setter
@ToString
public class NullValueResultDO{ }
缓存空对象的缺点:有大量的空数据占用redis的内存.治标不治本.
布隆过滤器:
有谷歌的guava,但是是单机版的,不支持分布式.
也可以用redis的位数组bit手写一个分布式布隆过滤器,代码就不写了.过程就是先把id(比如你是用id为key的)存进布隆过滤器(会经过特定的算法),当我们请求接口的时候先让它查询布隆过滤器,判断数据是否存在.
上面的代码还有个缓存击穿(缓存当中没有,数据库中有)问题,就是并发的时候.比如99个人同时请求,还是会打印99条sql语句,还是会找数据库.
这里的代码是用的分布式锁(互斥锁)
public R redisFindCache(String key, long expire, TimeUnit unit, CacheLoadble<T> cacheLoadble,boolean b){
//判断是否走过滤器
if(b){
//先走过滤器
boolean bloomExist = bloomFilter.isExist(String.valueOf(key));
if(!bloomExist){
return new R().setCode(600).setData(null).setMsg("查询无果");
}
}
//查询缓存
Object redisObj = valueOperations.get(String.valueOf(key));
//命中缓存
if(redisObj != null) {
//正常返回数据
return new R().setCode(200).setData(redisObj).setMsg("OK");
}
// RLock lock0 = redisson.getLock("{taibai0}:" + key);
// RLock lock1 = redisson.getLock("{taibai1}:" + key);
// RLock lock2 = redisson.getLock("{taibai2}:" + key);
// RedissonMultiLock lock = new RedissonMultiLock(lock0,lock1, lock2);
try {
redisLock.lock(key);//上锁
// lock.lock();
//查询缓存
redisObj = valueOperations.get(String.valueOf(key));
//命中缓存
if(redisObj != null) {
//正常返回数据
return new R().setCode(200).setData(redisObj).setMsg("OK");
}
T load = cacheLoadble.load();//查询数据库
if (load != null) {
valueOperations.set(key, load,expire, unit); //加入缓存
return new R().setCode(200).setData(load).setMsg("OK");
}
return new R().setCode(500).setData(new NullValueResultDO()).setMsg("查询无果");
}finally {
redisLock.unlock(key);//解锁
// lock.unlock();
}
}
三,缓存与数据库双写一致
3.1什么是缓存与数据库双写一致问题?
如果仅仅查询的话,缓存的数据和数据库的数据是没问题的。但是,当我们要更新时候呢?各种情况很可能就造成数据库和缓存的数据不一致了。
- 这里不一致指的是:数据库的数据跟缓存的数据不一致
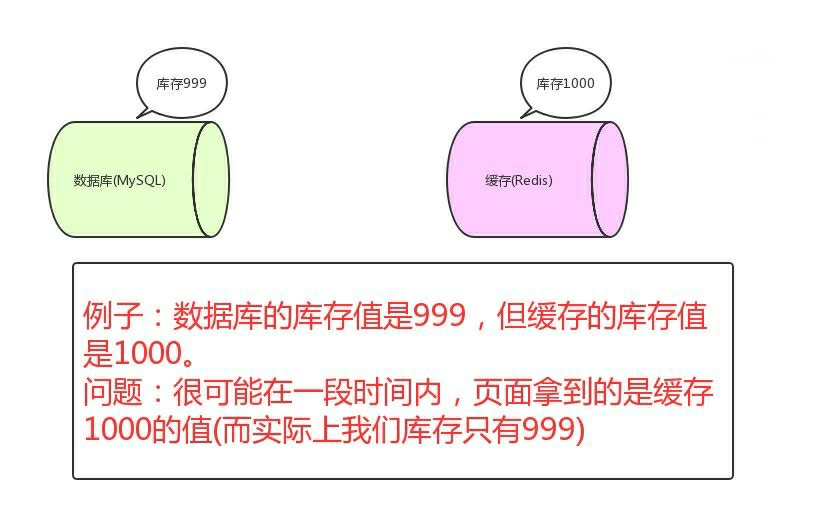
从理论上说,只要我们设置了键的过期时间,我们就能保证缓存和数据库的数据最终是一致的。因为只要缓存数据过期了,就会被删除。随后读的时候,因为缓存里没有,就可以查数据库的数据,然后将数据库查出来的数据写入到缓存中。
除了设置过期时间,我们还需要做更多的措施来尽量避免数据库与缓存处于不一致的情况发生。
3.2对于更新操作
一般来说,执行更新操作时,我们会有两种选择:
- 先操作数据库,再操作缓存
- 先操作缓存,再操作数据库
首先,要明确的是,无论我们选择哪个,我们都希望这两个操作要么同时成功,要么同时失败。所以,这会演变成一个分布式事务的问题。
所以,如果原子性被破坏了,可能会有以下的情况:
- 操作数据库成功了,操作缓存失败了。
- 操作缓存成功了,操作数据库失败了。
如果第一步已经失败了,我们直接返回Exception出去就好了,第二步根本不会执行。
下面我们具体来分析一下吧。
3.2.1操作缓存
操作缓存也有两种方案:
- 更新缓存
- 删除缓存
一般我们都是采取删除缓存缓存策略的,原因如下:
- 高并发环境下,无论是先操作数据库还是后操作数据库而言,如果加上更新缓存,那就更加容易导致数据库与缓存数据不一致问题。(删除缓存直接和简单很多)
- 如果每次更新了数据库,都要更新缓存【这里指的是频繁更新的场景,这会耗费一定的性能】,倒不如直接删除掉。等再次读取时,缓存里没有,那我到数据库找,在数据库找到再写到缓存里边(体现懒加载)
基于这两点,对于缓存在更新时而言,都是建议执行删除操作!
3.2.2先更新数据库,再删除缓存
正常情况是这样的:
- 先操作数据库,成功
- 在删除缓存,也成功
如果原子性被破坏了:
- 第一步成功(操作数据库),第二步失败(删除缓存),会导致数据库里是新数据,而缓存里是旧数据。
- 如果第一步(操作数据库)就失败了,我们可以直接返回错误(Exception),不会出现数据不一致。
如果在高并发的场景下,出现数据库与缓存数据不一致的概率特别低,也不是没有:
- 缓存刚好失效
- 线程A查询数据库,得一个旧值
- 线程B将新值写入数据库
- 线程B删除缓存
- 线程A将查到的旧值写入缓存
要达成上述情况,还是说一句概率特别低:
因为这个条件需要发生在读缓存时缓存失效,而且并发着有一个写操作。而实际上数据库的写操作会比读操作慢得多,而且还要锁表,而读操作必需在写操作前进入数据库操作,而又要晚于写操作更新缓存,所有的这些条件都具备的概率基本并不大。
对于这种策略,其实是一种设计模式:Cache Aside Pattern

删除缓存失败的解决思路:
- 将需要删除的key发送到消息队列中
- 自己消费消息,获得需要删除的key
- 不断重试删除操作,直到成功
3.2.3先删除缓存,在更新数据库
正常情况是这样的:
- 先删除缓存,成功;
- 再更新数据库,也成功;
如果原子性被破坏了:
- 第一步成功(删除缓存),第二步失败(更新数据库),数据库和缓存的数据还是一致的。
- 如果第一步(删除缓存)就失败了,我们可以直接返回错误(Exception),数据库和缓存的数据还是一致的。
看起来是很美好,但是我们在并发场景下分析一下,就知道还是有问题的了:
- 线程A删除了缓存
- 线程B查询,发现缓存已不存在
- 线程B去数据库查询得到旧值
- 线程B将旧值写入缓存
- 线程A将新值写入数据库
所以也会导致数据库和缓存不一致的问题。
并发下解决数据库与缓存不一致的思路:
- 将删除缓存、修改数据库、读取缓存等的操作积压到队列里边,实现串行化。
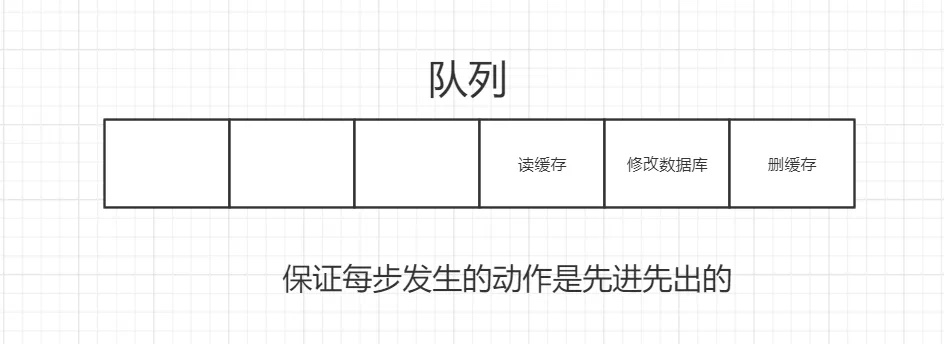
3.2.4对比着两种策略
我们可以发现,两种策略各自有优缺点:
- 先删除缓存,再更新数据库
在高并发下表现不如意,在原子性被破坏时表现优异
- 先更新数据库,再删除缓存(Cache Aside Pattern设计模式)
在高并发下表现优异,在原子性被破坏时表现不如意
3.2.5其他保障数据一致的方案与资料
可以用databus或者阿里的canal监听binlog进行更新。
参考资料:
- 缓存更新的套路
https://coolshell.cn/articles/17416.html
- 如何保证缓存与数据库双写时的数据一致性?
https://github.com/doocs/advanced-java/blob/master/docs/high-concurrency/redis-consistence.md
- 分布式之数据库和缓存双写一致性方案解析
https://zhuanlan.zhihu.com/p/48334686
- Cache Aside Pattern
https://blog.csdn.net/z50l2o08e2u4aftor9a/article/details/81008933
Redis的三大问题的更多相关文章
- 看完这篇Redis缓存三大问题,保你面试能造火箭,工作能拧螺丝。
前言 日常的开发中,无不都是使用数据库来进行数据的存储,由于一般的系统任务中通常不会存在高并发的情况,所以这样看起来并没有什么问题. 一旦涉及大数据量的需求,如一些商品抢购的情景,或者主页访问量瞬间较 ...
- 【原创】分布式之redis的三大衍生数据结构
引言 说起redis的数据结构,大家可能对五大基础数据类型比较熟悉:String,Hash,List,Set,Sorted Set.那么除此之外,还有三大衍生数据结构,大家平时是很少接触的,即:bit ...
- Redis学习基础二
回顾:上一基础中已了解 ( 什么是redis .redis 的三大特点.安装,和数据配置) 接下来浅尝Redis的数据类型,时间煮雨...... 一.Redis数据类型 redis支持五中数据类型(s ...
- Redis学习基础一
今天开始系统的学习redis基础知识,以往只是看redis的手册,貌似总是记不住.这次尝试手记笔记,使得印象更加深刻,从零开始学习.看是很慢,其实很快哟. 一.什么是Redis 至于什么是redis, ...
- Redis的持久化——RDB
前面说到redis的三大特性:缓存.分布式内存数据库.持久化,所以今天将为大家介绍redis的两种数据持久化技术RDB和AOF, 先介绍RDB吧. 一.RDB是什么? 1.RDB全称redis dat ...
- [Redis] 万字长文带你总结Redis,助你面试升级打怪
文章目录 Redis的介绍.优缺点.使用场景 Linux中的安装 常用命令 Redis各个数据类型及其使用场景 Redis字符串(String) Redis哈希(Hash) Redis列表(List) ...
- 都在讲Redis主从复制原理,我来讲实践总结
摘要:本文将演示主从复制如何配置.实现以及实现原理,Redis主从复制三大策略,全量复制.部分复制和立即复制. 本文分享自华为云社区<Redis主从复制实践总结>,原文作者:A梦多啦A . ...
- 基于.NetCore的Redis5.0.3(最新版)快速入门、源码解析、集群搭建与SDK使用【原创】
1.[基础]redis能带给我们什么福利 Redis(Remote Dictionary Server)官网:https://redis.io/ Redis命令:https://redis.io/co ...
- django面试四
Django的优点 功能完善.要素齐全:自带大量常用工具和框架(比如分页,auth,权限管理), 适合快速开发企业级网站. 完善的文档:经过十多年的发展和完善,Django有广泛的实践案例和完善的在线 ...
随机推荐
- IDEA2019.3激活使用
IDEA2019.3激活使用 1.下载idea: https://www.jetbrains.com/idea/download/ 下载 .exe或者.Zip都可以 2. 启动:点击下载好的id ...
- SpringBoot中遇到的一些问题
1.JQuery和bootstrap报404的问题 在html页面导入的js和css的时候,不要加static这级目录,直接跳过即可,例如 导入的时候不需要加static目录,直接导入js/和css/ ...
- 《java编程思想》多态与接口
向上转型 定义:把某个对象的引用视为对其基类类型的引用的做法被称为向上转型方法调用绑定 将一个方法调用同一个方法主体关联起来被称作绑定. 前期绑定:程序执行前进行的绑定叫做前期绑定,前期绑定也是jav ...
- 利用Python批量重命名文件夹下文件
#!/usr/bin/python # -*- coding: UTF-8 -*- # -*- coding:utf8 -*- import os from string import digits ...
- SWUST OJ 1012哈希表(链地址法处理冲突)
哈希表(链地址法处理冲突) 1000(ms) 10000(kb) 2676 / 6911 采用除留余数法(H(key)=key %n)建立长度为n的哈希表,处理冲突用链地址法.建立链表的时候采用尾插法 ...
- Golang入门(4):并发
摘要 并发程序指同时进行多个任务的程序,随着硬件的发展,并发程序变得越来越重要.Web服务器会一次处理成千上万的请求,这也是并发的必要性之一.Golang的并发控制比起Java来说,简单了不少.在Go ...
- .NET Core项目部署到Linux(Centos7)(八)为.NET Core项目创建Supervisor进程守护监控
目录 1.前言 2.环境和软件的准备 3.创建.NET Core API项目 4.VMware Workstation虚拟机及Centos 7安装 5.Centos 7安装.NET Core环境 6. ...
- 详细解析 HBASE 配置的各种要点
文章更新于:2020-04-06 安装惯例,需要的文件附上链接放在文首. 文件名:hbase-2.2.4-bin.tar.gz 文件大小:213.24 MB 下载链接:http://download. ...
- Django -->admin后台(后台管理可以直接往数据库添加数据)
一.使用pymysql时,必须加这两行(#如果使用mysql的数据库,请进行伪装 pymysql伪装为MySQLdb) import pymysqlpymysql.install_as_MySQLdb ...
- python3(三十二) try except
""" 异常处理 """ __author__on__ = 'shaozhiqi 2019/9/19' # 大量的代码来判断是否出错: # ...