NLP(二十七)开放领域的三元组抽取的一次尝试
当我写下这篇文章的时候,我的内心是激动的,这是因为,自从去年6月份写了文章利用关系抽取构建知识图谱的一次尝试 后,我就一直在试图寻找一种在开放领域能够进行三元组抽取的办法,也有很多读者问过我这方面的问题,今天,笔者将给出答复,虽然不是正确答案(现在也没有正确答案),但至少,我写下了自己的答案。
离我想出这个抽取系统虽然才过去不久,但我的心情,已经由开始的激动狂喜,转化为后来的平淡,直到现在的不满。事实证明,开放领域的三元组抽取实在太难,以笔者个人的努力和智商,实在没法给出完美的答案,所以,文章的题目是尝试,仅仅作为尝试,并不能解决好这个问题。但,我还是想写些什么,希望能够对笔者有一点点启发,同时,也是对自己近半年的探寻做一个总结。
关于三元组抽取的基本介绍和常用办法,笔者之前已经在不少文章中描述过,这里不再过多介绍,有兴趣的读者可以参考文章利用关系抽取构建知识图谱的一次尝试 和 NLP(二十六)限定领域的三元组抽取的一次尝试 。本文将会介绍笔者在开放领域做三元组抽取的一次尝试。
本项目已经开源至Github,文章最后会给出相应的网址。本项目的项目结构如下:
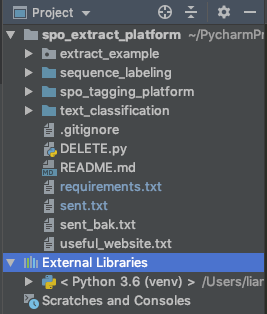
本项目一共分为四部分,主要模块介绍如下:
- extract_example: 利用训练好的模型对基本小说和新闻进行三元组抽取,形成知识图谱例子;
- sequence_labeling:训练标注,对标注的实体数据进行序列标注算法训练;
- spo_tagging_platform:标注平台,标注subject,predicate和object以及三元组是否有效;
- text_classification:文本分类,用于判别抽取的三元组是否有效。
本项目的抽取系统流程图如下:
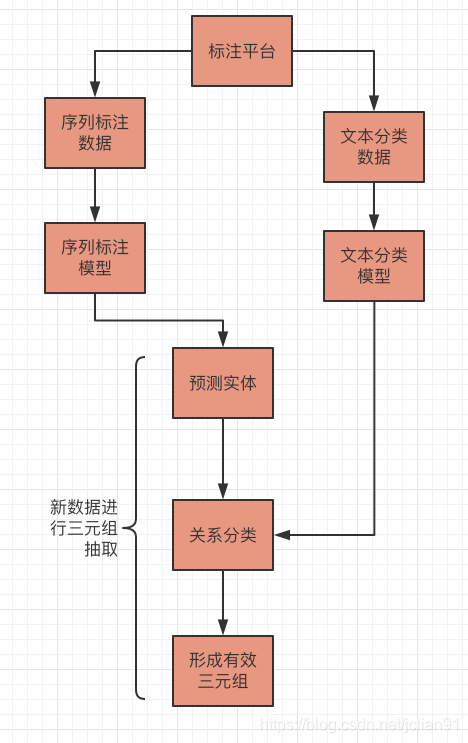
接下来笔者将逐一介绍。
标注平台
笔者用tornado搭建了简易的标注平台,在标注页面中,标注人员需要输入标注的句子(句子级别的抽取)以及subject,predicate,object,点击“显示SPO”,将有效的三元组标注为1,无效的三元组标注为0。之所以采取这种标注方法,是因为我们可以在句子中标注subject,predicate,object,这些标注的实体就会形成可能的三元组组合,再利用0,1来标注这种三元组是否有效,这样就能做到在开放领域进行三元组抽取。
一个简单的标注例子如下:
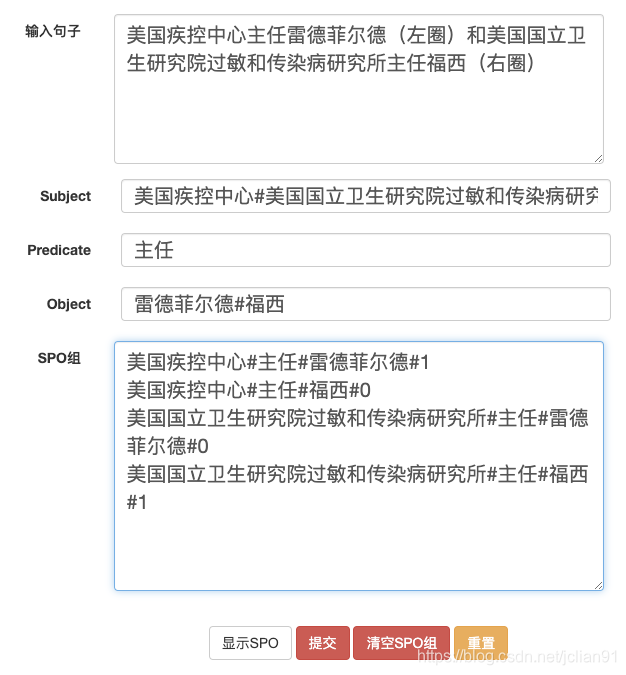
再对以上的标注结果做一些说明,我们的标注是以句子为单位,进行句子级别的标注,不同要素在标注的时候加#区分,标注了两个subject,1个predicate(共用)和2个object,其中predidate是这些subject和object公用的,所以只需要标注一次。这样,点击“显示SPO”,一共会显示4个三元组,s,p,o用#隔开,0,1表示是否是有效三元组,默认为0。
笔者利用空余时间,一共标注了3200多个样本,对于序列标注来说,就是3200多个样本,对于文本分类来说,就是9000多个样本了。
序列标注
对于上述的标注例子,会形成如下的标注序列:
美 B-SUBJ
国 I-SUBJ
疾 I-SUBJ
控 I-SUBJ
中 I-SUBJ
心 I-SUBJ
主 B-PRED
任 I-PRED
雷 B-OBJ
德 I-OBJ
菲 I-OBJ
尔 I-OBJ
德 I-OBJ
( O
左 O
圈 O
) O
和 O
美 B-SUBJ
国 I-SUBJ
国 I-SUBJ
立 I-SUBJ
卫 I-SUBJ
生 I-SUBJ
研 I-SUBJ
究 I-SUBJ
院 I-SUBJ
过 I-SUBJ
敏 I-SUBJ
和 I-SUBJ
传 I-SUBJ
染 I-SUBJ
病 I-SUBJ
研 I-SUBJ
究 I-SUBJ
所 I-SUBJ
主 B-PRED
任 I-PRED
福 B-OBJ
西 I-OBJ
( O
右 O
圈 O
) O
将数据集分为训练集和测试集,比例为8:2.采用经典的深度学习模型ALBERT+Bi-LSTM+CRF进行实体识别,设置最大文本长度为128,训练100个epoch。关于该模型的介绍,可以参考文章NLP(二十五)实现ALBERT+Bi-LSTM+CRF模型 。
在测试集上的训练结果如下:
accuracy: 93.69%; precision: 76.26%; recall: 82.33%; FB1: 79.18
OBJ: precision: 80.47%; recall: 88.81%; FB1: 84.44 927
PRED: precision: 76.89%; recall: 83.69%; FB1: 80.14 1021
SUBJ: precision: 71.72%; recall: 75.32%; FB1: 73.48 983
在测试集上的总体F1值接近80%。
文本分类
关于文本分类,需要多做一些说明。
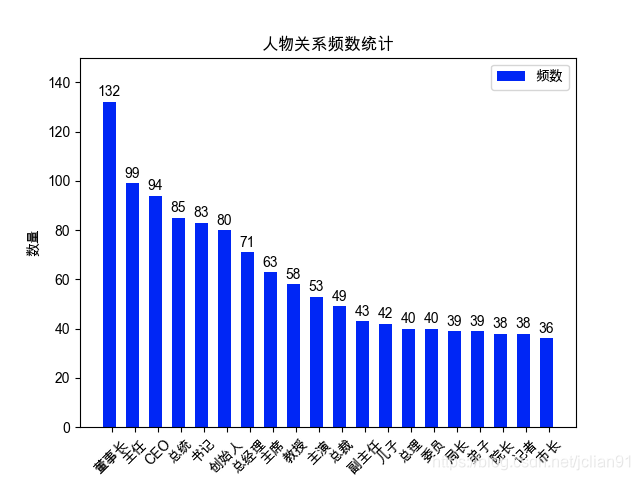
虽然本文的题目是关于在开发领域的三元组抽取的尝试,但实际我在标注的时候,还是更多地标注人物头衔,人物关系,公司与人的关系,影视剧主演、导演信息等。形成的有效的文本分类的样本为9000多个,一共有关系1365个,数量最多的前20个关系如下图:
以上述的标注数据为例,形成的标注数据如下:
美国疾控中心#主任#雷德菲尔德#1#美国疾控中心主任雷德菲尔德(左圈)和美国国立卫生研究院过敏和传染病研究所主任福西(右圈)
美国疾控中心#主任#福西#0#美国疾控中心主任雷德菲尔德(左圈)和美国国立卫生研究院过敏和传染病研究所主任福西(右圈)
美国国立卫生研究院过敏和传染病研究所#主任#雷德菲尔德#0#美国疾控中心主任雷德菲尔德(左圈)和美国国立卫生研究院过敏和传染病研究所主任福西(右圈)
美国国立卫生研究院过敏和传染病研究所#主任#福西#1#美国疾控中心主任雷德菲尔德(左圈)和美国国立卫生研究院过敏和传染病研究所主任福西(右圈)
在实际模型训练的时候,会将原文中的subject用S*len(subject)代替,predicate用P,object用O。
将数据集分为训练集和测试集,比例为8:2。采用经典的深度学习模型ALBERT+Bi-GRU+ATT+FC,设置文本的最大长度为为128,训练30个epoch,采用early stopping机制,训练过程的loss和acc图像如下:
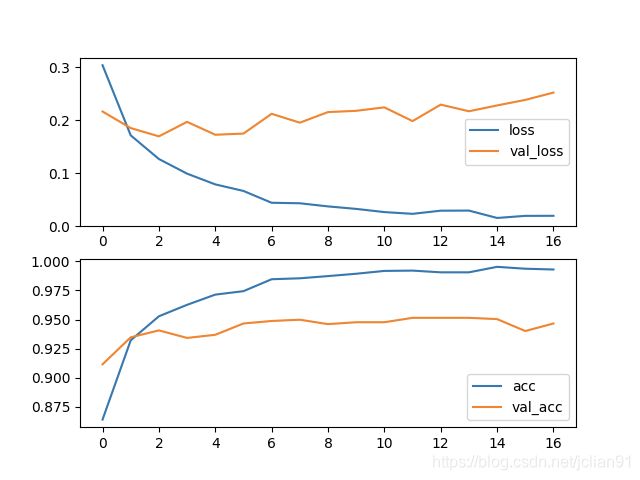
最终在测试集上的accuracy约为96%。
新数据进行三元组抽取
上述的模型训练完毕后,我们就可以将其封装成HTTP服务。对于新输入的句子,我们先利用序列标注模型预测出其中的subject,predicate和object,组合成三元组与句子的拼接,输入到文本分类模型,判别该三元组是否有效,0为无效,1为有效。
从网上找几个例子,预测的结果如下:
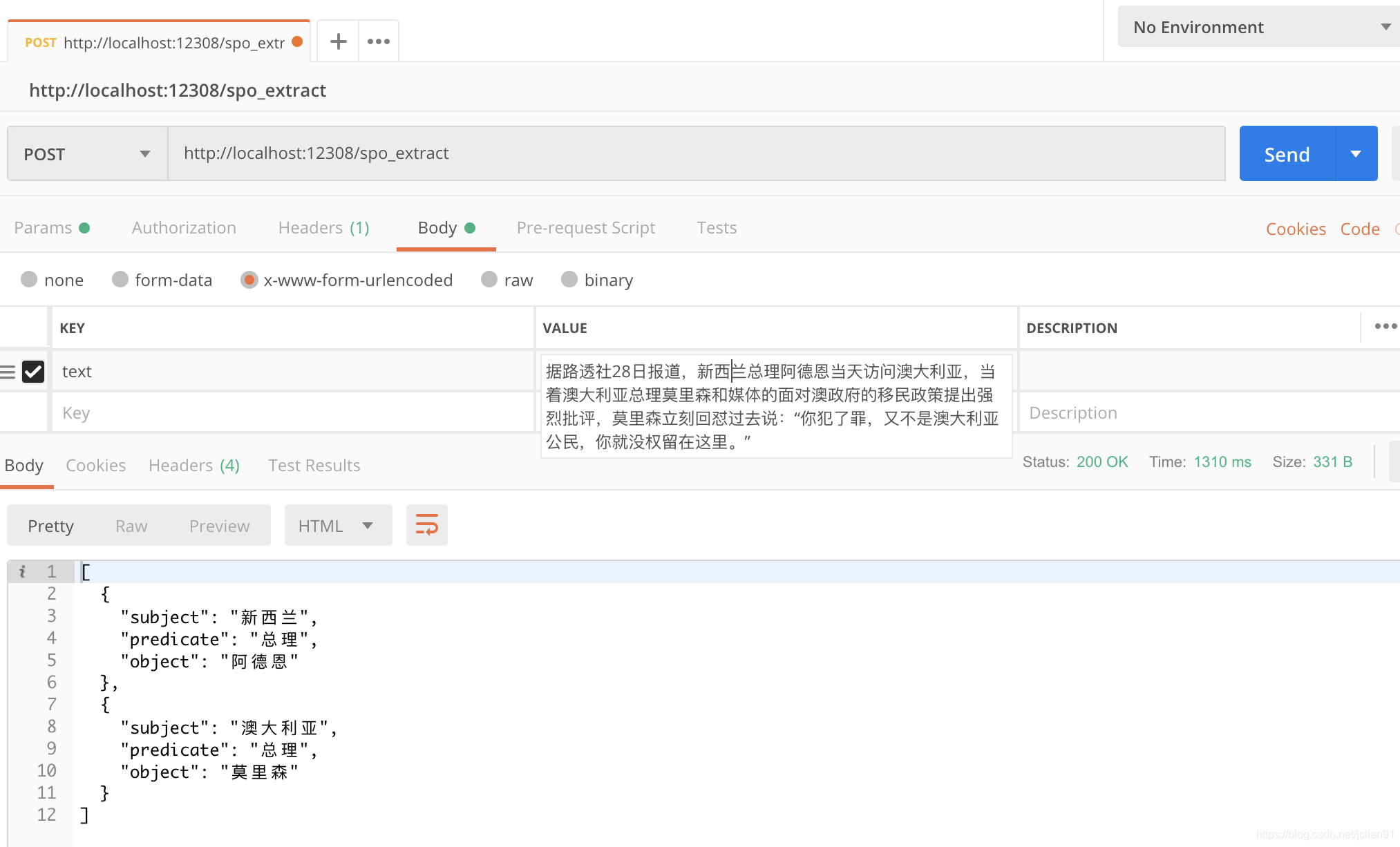
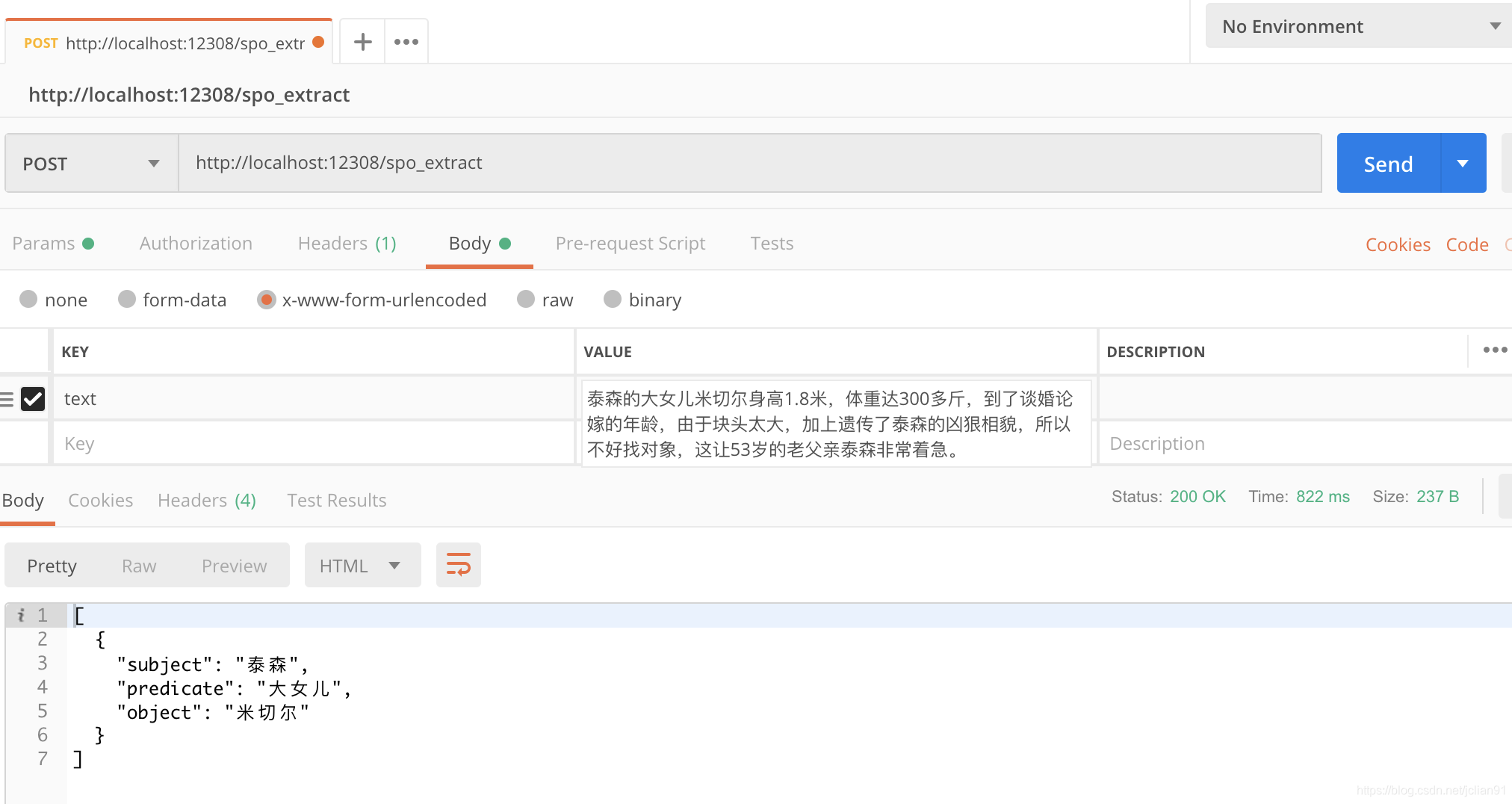
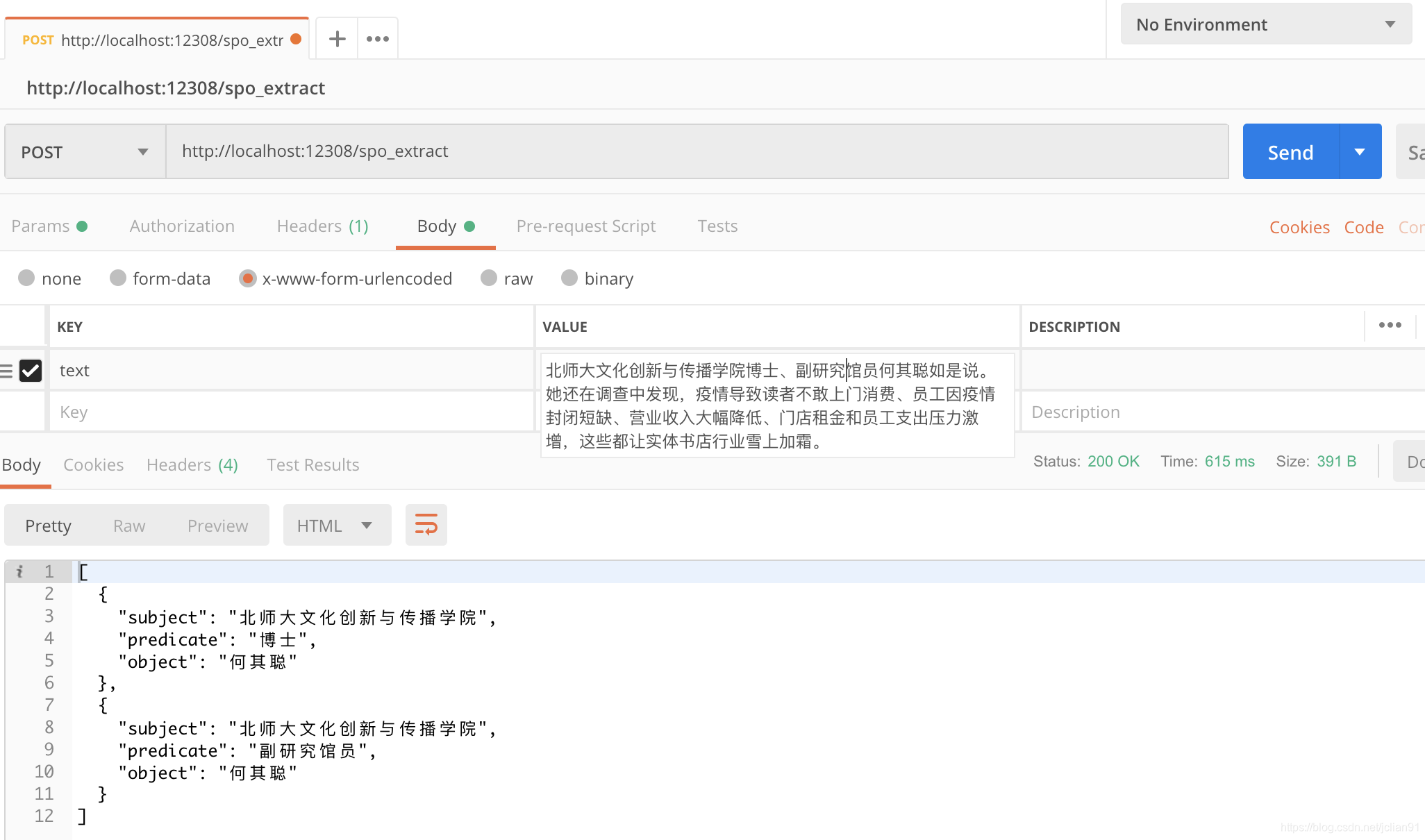
extract_example目录中为抽取的效果,包括几本小说和一些新闻上的效果,关于这方面的演示,可以参考另一个项目:https://github.com/percent4/knowledge_graph_demo 。也可以参考文章知识图谱构建举例 中给出的几个知识图谱的建构的例子。
总结
本文写的过程较为简单,也没有代码,这是因为笔者在之前的文章中做了大量的铺垫,主要是集中在模型方面。况且,这个项目比较大,也不适合在这里详细讲述,笔者只在这里给出思路和大概的处理流程,具体的实现代码可以参考下方的Github地址。
在实际的抽取过程中,一些句子也存在抽取出大量无用的三元组的情况,导致召回率高,这是因为本项目针对的是开放领域的三元组抽取,因此效果比不会有想象中的那么好,提升抽取效果的办法如下:
- 增加数据标注量,目前序列标注算法的样本仅3200多个;
- 模型方面:现在是pipeline形式,各自的效果还行,但总体上不如Joint形式好;
- 对于自己想抽的其他三元组的情形,建议增加这方面的标注;
- 文本预测耗时长(该问题已经解决)。
本项目作为笔者在开放领域的三元组抽取的一次尝试,在此之前关于这方面的文章或者项目还很少,因此可以说是探索阶段。
源码和数据已经在Github项目中给出,网址为 https://github.com/percent4/spo_extract_platform 。
本人的微信公众号为Python爬虫与算法,欢迎关注~
参考文献
- 利用关系抽取构建知识图谱的一次尝试: https://www.cnblogs.com/jclian91/p/11107323.html
- NLP(二十六)限定领域的三元组抽取的一次尝试: https://blog.csdn.net/jclian91/article/details/104874488
- NLP(二十五)实现ALBERT+Bi-LSTM+CRF模型: https://blog.csdn.net/jclian91/article/details/104826655
- 知识图谱构建举例: https://blog.csdn.net/jclian91/article/details/104685424
- NLP(二十一)人物关系抽取的一次实战:https://blog.csdn.net/jclian91/article/details/104380371
- 《知识图谱 方法、实践与应用》 王昊奋、漆桂林、陈华钧著,中国工信出版集团、电子工业出版社出版。
NLP(二十七)开放领域的三元组抽取的一次尝试的更多相关文章
- NLP(二十六)限定领域的三元组抽取的一次尝试
本文将会介绍笔者在2019语言与智能技术竞赛的三元组抽取比赛方面的一次尝试.由于该比赛早已结束,笔者当时也没有参加这个比赛,因此没有测评成绩,我们也只能拿到训练集和验证集.但是,这并不耽误我们在这 ...
- Bootstrap<基础二十七> 多媒体对象(Media Object)
Bootstrap 中的多媒体对象(Media Object).这些抽象的对象样式用于创建各种类型的组件(比如:博客评论),我们可以在组件中使用图文混排,图像可以左对齐或者右对齐.媒体对象可以用更少的 ...
- Web 开发精华文章集锦(jQuery、HTML5、CSS3)【系列二十七】
<Web 前端开发精华文章推荐>2014年第6期(总第27期)和大家见面了.梦想天空博客关注 前端开发 技术,分享各类能够提升网站用户体验的优秀 jQuery 插件,展示前沿的 HTML5 ...
- Citrix 服务器虚拟化之二十七 XenApp6.5发布服务器桌面
Citrix 服务器虚拟化之二十七 XenApp6.5发布服务器桌面 XenApp可发布以下类型的资源向用户提供信息访问,这些资源可在服务器或桌面上虚拟化: 1) 服务器桌面:发布场中服务器的整个 ...
- 转:二十七、Java图形化界面设计——容器(JFrame)
转:http://blog.csdn.net/liujun13579/article/details/7756729 二十七.Java图形化界面设计——容器(JFrame) 程序是为了方便用户使用的, ...
- 二十七、Java图形化界面设计——容器(JFrame)
摘自http://blog.csdn.net/liujun13579/article/details/7756729 二十七.Java图形化界面设计--容器(JFrame) 程序是为了方便用户使用的, ...
- WCF技术剖析之二十七: 如何将一个服务发布成WSDL[基于HTTP-GET的实现](提供模拟程序)
原文:WCF技术剖析之二十七: 如何将一个服务发布成WSDL[基于HTTP-GET的实现](提供模拟程序) 基于HTTP-GET的元数据发布方式与基于WS-MEX原理类似,但是ServiceMetad ...
- WCF技术剖析之二十七: 如何将一个服务发布成WSDL[基于WS-MEX的实现](提供模拟程序)
原文:WCF技术剖析之二十七: 如何将一个服务发布成WSDL[基于WS-MEX的实现](提供模拟程序) 通过<如何将一个服务发布成WSDL[编程篇]>的介绍我们知道了如何可以通过编程或者配 ...
- WCF技术剖析之二十七: 如何将一个服务发布成WSDL[编程篇]
原文:WCF技术剖析之二十七: 如何将一个服务发布成WSDL[编程篇] 对于WCF服务端元数据架构体系来说,通过MetadataExporter将服务的终结点导出成MetadataSet(参考< ...
随机推荐
- python&&Java&&jsp+servlet连接数据库报错收藏(sql server,mysql)
写在最前面:sql server和mysql 是不同的东西... 我在完成java连接数据库的时候把这俩当成一个东西,结果下的mysql的jar包. 但自己的sql是server.. 然后尝试用 py ...
- XML的四种解析器(dom_sax_jdom_dom4j)原理及性能比较[收藏]
1)DOM(JAXP Crimson解析器) DOM是用与平台和语言无关的方式表示XML文档的官方W3C标准.DOM是以层次结构组织的节点或信息片断的集合.这个层次结构允许开发人员在树中寻找特定 ...
- java对象POJO和JavaBean的区别
"Plain Ordinary Java Object",简单普通的java对象.主要用来指代那些没有遵循特定的java对象模型,约定或者框架的对象.POJO的内在含义是指那些:有 ...
- AWS CloudFront / 亚马逊CDN使用教程
步骤: 1. 打开CloudFront服务之后,首先需要选择分发类型.分发类型分为一般的静态文件分发和流媒体分发,即Web和RTMP,我的站点即选择Web类型. 2. CDN回源设定. a. 首先要填 ...
- angular知识点(2)
angular知识点(2) 1.为了代码规范,对于需要自动加载的依赖,需要在前面加上注释,注释为://@ngInject 或者是/*@ngInject*/ 2.ngSwitch的应用 在需要用到选择出 ...
- android framework 之JNI
Java Native Interface ( JN I)是Java本地接口,所谓的本地(native) —般是指C/C++ ( 以下统称C)语言.当使用Java进行程序设计时,一般主要有三种情况需要 ...
- Python——12类的继承
*/ * Copyright (c) 2016,烟台大学计算机与控制工程学院 * All rights reserved. * 文件名:text.cpp * 作者:常轩 * 微信公众号:Worldhe ...
- P1097 统计数字
P1097题库链接:https://www.luogu.org/problem/P1097 难度:普及- 算法标签:模拟,排序,概率论 1.桶模拟 O(n) 得分20 由于题目让统计数出现的次数,并按 ...
- sql的练习题
表名和字段 –1.学生表 Student(s_id,s_name,s_birth,s_sex) --学生编号,学生姓名, 出生年月,学生性别 –2.课程表 Course(c_id,c_name,t_i ...
- Linux永久开放端口
/sbin/iptables -I INPUT -p tcp --dport 80 -j ACCEPT /sbin/iptables -I INPUT -p tcp --dport 3306 -j A ...