Redis学习一:Redis两种持久化机制
申明
本文章首发自本人公众号:壹枝花算不算浪漫,如若转载请标明来源!
感兴趣的小伙伴可关注个人公众号:壹枝花算不算浪漫
 22.jpg
22.jpg
前言
Redis是基于内存来实现的NO SQL数据库,但是我么你都知道存储在内存中的数据,只要服务器关机,内存中的数据就会消失了。
为了避免内存中的数据丢失,Redis提供了对持久化的支持。Redis共有RDB和AOF两种持久化机制。
可以先看下两种持久化机制原理:
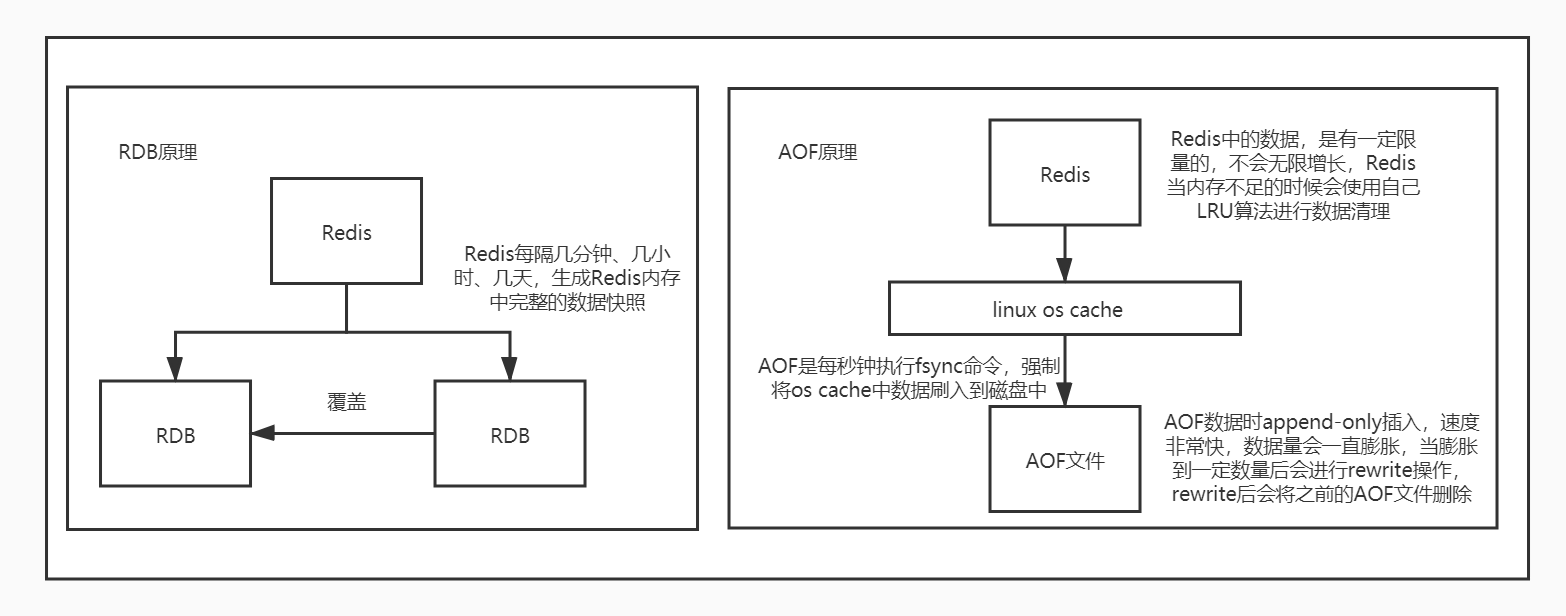 01_Redis中RDB和AOF.jpg
01_Redis中RDB和AOF.jpg
RDB和AOF两种持久化机制的介绍
RDB持久化机制,对redis中的数据执行周期性的持久化
AOF机制对每条写入命令作为日志,以append-only的模式写入一个日志文件中,在redis重启的时候,可以通过回放AOF日志中的写入指令来重新构建整个数据集
如果同时使用RDB和AOF两种持久化机制,那么在redis重启的时候,会使用AOF来重新构建数据,因为AOF中的数据更加完整
RDB持久化机制的优点
RDB非常适合做冷备,可以将这种完整的数据文件发送到一些远程的安全存储上去,比如云服务器。
RDB对redis对外提供的读写服务,影响非常小,可以让redis保持高性能,因为redis主进程只需要fork一个子进程,让子进程执行磁盘IO操作来进行RDB持久化即可
相对于AOF持久化机制来说,直接基于RDB数据文件来重启和恢复redis进程,更加快速
RDB持久化机制的缺点
- 如果想要在redis故障时,尽可能少的丢失数据,那么RDB没有AOF好。一般来说RDB数据快照文件,都是每隔5分钟,或者更长时间生成一次,这个时候就得接受一旦redis进程宕机,那么会丢失最近5分钟的数据
- RDB每次在fork子进程来执行RDB快照数据文件生成的时候,如果数据文件特别大,可能会导致对客户端提供的服务暂停数毫秒,或者甚至数秒
AOF持久化机制的优点
- AOF可以更好的保护数据不丢失,一般AOF会每隔1秒,通过一个后台线程执行一次fsync操作,最多丢失1秒钟的数据
- AOF日志文件以append-only模式写入,所以没有任何磁盘寻址的开销,写入性能非常高,而且文件不容易破损,即使文件尾部破损,也很容易修复
- AOF日志文件即使过大的时候,出现后台重写操作,也不回影响客户端的读写。因为再rewrite log的时候,会对其中的指令进行压缩,创建一份需要恢复数据的最小日志出来。再创建新日志文件的时候,老的日志文件还是照常写入。当新的merge后的日志文件ready的时候,再交换老日志文件即可
- AOF日志文件的命令通过非常可读的方式进行记录,这个特性非常适合做灾难性的误删除的紧急恢复。比如不小心使用flushall命令清空了所有数据,只要这个时候后台rewrite还没有发生,那么就可以立即拷贝AOF文件,将最后一条flushall命令给删除,然后再将AOF文件放回去,就可以通过恢复机制,自动恢复所有数据
AOF持久化机制的缺点
- 对于同一份数据来说,AOF日志文件通常比RDB数据快照文件更大
- AOF开启后,支持的写QPS会比RDB支持的写QPS低,因为AOF一般会配置成每秒fsync一次日志文件,当然,每秒一次fsync,性能也还是很高的
RDB和AOF到底该如何选择
- 不要仅仅使用RDB,因为那样会导致丢失很多数据
- 不要仅仅使用AOF,因为这样会有问题,第一:通过AOF做冷备,没有RDB做冷备,来的恢复速度更快。第二:RDB每次简单粗暴生成数据快照,更加健壮,可以避免AOF这种复杂的备份和恢复机制的bug
- 综合使用AOF和RDB两种持久化机制,用AOF来保证数据不丢失,作为数据恢复的第一选择;用RDB来做不同程度的冷备,在AOF文件都丢失或损坏不可用的时候,还可以使用RDB来进行快速的数据恢复
RDB 配置
// 900s内至少达到一条写命令
save 900 1
// 300秒内至少达到10条写命令
save 300 10
// 60秒内至少达到10000条写命令
save 60 10000
也可以手动调用save或者bgsave命令,同步或异步执行rdb快照生成
RDB持久化机制的工作流程
- redis根据配置自己尝试去生成rdb快照文件
- fork一个子进程出来
- 子进程尝试将数据dump到临时的rdb快照文件中
- 完成rdb快照文件的生成之后,就替换之前旧的快照文件
dump.rdb 每次生成一个新的快照,都会覆盖之前老的快照文件
AOF 持久化的配置
AOF持久化默认是关闭的,默认是打开RDB持久化配置的。
配置appendonly yes,可以打开AOF持久化
打开AOF持久化之后,redis每次接收一条写命令,就会写入日志文件中,当然是先写入os cache,然后每隔一定时间再fsync一下。
而且即使AOF和RDB都开启了,redis重启的时候也会优先选择AOF,因为AOF的数据比较完整
可以配置AOF的fsync策略,有三种策略可以选择:
- always:每次写入一条数据,立即将这个数据对应的写离职fsync到磁盘上去,性能非常差
- everysec:每秒将os cache中的数据fsync到磁盘,这个是最常用的,性能比较高
- no:仅仅redis负责将数据写入os cache就不需要管了,依赖os根据自己的策略将数据刷入到磁盘中
AOF rewrite
redis中的数据时有限的,很多数据可能会自动过期,可能会被用户删除,也有可能被redis用缓存清除的算法清理掉
redis中的数据会不断淘汰掉旧的数据,只有一部分常用的数据会自动保留在redis内存中
所以很可能之前已经被清理掉的数据,对应的写日志还停留在AOF中,AOF日志文件就一个,会不断的膨胀
所以基于上面的原因,AOF会自动在后台每隔一定时间做rewrite操作,比如日志里已经存放了针对100w数据的写日志,而redis内存中此时只有10w数据;rewrite会基于当前内存中10w数据构建一套最新的日志到AOF中,覆盖之前的老日志
在redis.conf中,可以配置rewrite的策略:
- auto-aof-rewrite-percentage 100
- auto-aof-rewrite-min-size 64mb
大小超过64mb,且比上次增长了100%才会触发一次rewrite
具体rewrite步骤:
- redis fork一个子进程
- 子进程基于当前内存中的数据,构建日志,开始往一个新的临时AOF文件中写入日志
- redis主进程,接收到client新的写操作之后,在内存中写入日志,同时新的日志也继续写入旧的AOF文件
- 用新的日志文件替换掉旧的日志文件
AOF破损文件的修复
如果redis在append数据到AOF文件时,机器宕机了,可能会导致AOF文件破损
用redis-check-aof --fix命令来修复破损的AOF文件
AOF和RDB同时工作
- 如果RDB在执行snapshotting操作,那么redis不会执行AOF rewrite操作。如果redis在执行AOF rewrite,那么就不会执行RDB snapshotting操作
- 如果RDB在执行snapshotting,此时用户执行BGREWRITEAOF命令,那么等RDB快照生成之后,才会去执行AOF rewrite
- 同时有RDB snapshot文件和AOF日志文件,那么redis重启的时候,会优先使用AOF进行数据恢复,因为其中的日志更完整
Redis学习一:Redis两种持久化机制的更多相关文章
- Redis系列之----Redis的两种持久化机制(RDB和AOF)
Redis的两种持久化机制(RDB和AOF) 什么是持久化 Redis的数据是存储在内存中的,内存中的数据随着服务器的重启或者宕机便会不复存在,在生产环境,服务器宕机更是屡见不鲜,所以,我们希望 ...
- 9. 图解分析Redis的RDB和AOF两种持久化机制的原理
1.RDB和AOF两种持久化机制的介绍 2.RDB持久化机制的优点3.RDB持久化机制的缺点4.AOF持久化机制的优点5.AOF持久化机制的缺点6.RDB和AOF到底该如何选择 我们已经知道对于一个企 ...
- 10.Redis的RDB和AOF两种持久化机制的优劣势对比
1.RDB和AOF两种持久化机制的介绍 2.RDB持久化机制的优点3.RDB持久化机制的缺点4.AOF持久化机制的优点5.AOF持久化机制的缺点6.RDB和AOF到底该如何选择 我们已经知道对于一个企 ...
- 详解Redis中两种持久化机制RDB和AOF(面试常问,工作常用)
redis是一个内存数据库,数据保存在内存中,但是我们都知道内存的数据变化是很快的,也容易发生丢失.幸好Redis还为我们提供了持久化的机制,分别是RDB(Redis DataBase)和AOF(Ap ...
- 详解Redis中两种持久化机制RDB和AOF
redis是一个内存数据库,数据保存在内存中,但是我们都知道内存的数据变化是很快的,也容易发生丢失.幸好Redis还为我们提供了持久化的机制,分别是RDB(Redis DataBase)和AOF(Ap ...
- redis的RDB和AOF两种持久化机制
思维导图:我的redis基础知识汇总 RDB持久化机制的优点 (1)RDB会生成多个数据文件,每个数据文件都代表了某一个时刻中redis的数据,这种多个数据文件的方式,非常适合做冷备,可以将这种完整的 ...
- Redis的两种持久化机制
Redis的两种持久化机制 1.持久化机制 client--->redis(内存)--->内存数据-数据持久化--->磁盘 两种方法 快照(Snapshot) AOF(Append ...
- 分析RedisRDB和AOF两种持久化机制的工作原理及优劣势
一.RDB和AOF两种持久化机制的介绍 RDB持久化机制,对redis中的数据执行周期性的持久化 AOF机制对每条写入命令作为日志,以append-only(追加)的模式写入一个日志文件中,在redi ...
- 01.图文理解RDB和AOF两种持久化机制
一.RDB和AOF两种持久化机制的介绍 RDB:对redis中的数据执行周期性的持久化,每隔一个时刻生成一个RDB文件,这个RDB文件包含这个时刻所有的数据. AOF:记录每条写入命令,以append ...
随机推荐
- LeetCode | 707. 设计链表
设计链表的实现.您可以选择使用单链表或双链表.单链表中的节点应该具有两个属性:val 和 next.val 是当前节点的值,next 是指向下一个节点的指针/引用.如果要使用双向链表,则还需要一个属性 ...
- 新文预览 | IoU-aware Single-stage Object Detector for Accurate Localization
论文基于RetinaNet提出了IoU-aware sinage-stage目标检测算法,该算法在regression branch接入IoU predictor head并通过加权分类置信度和IoU ...
- python 清空list的几种方法
本文介绍清空list的四种方法,以及 list=[ ] 和 list.clear() 在使用中的区别(坑). 1.使用clear()方法 lists = [1, 2, 1, 1, 5] lists.c ...
- python中使用openpyxl模块时报错: File is not a zip file
python中使用openpyxl模块时报错: File is not a zip file. 最大的原因就是不是真正的 xlsx文件, 如果是通过 库xlwt 新建的文件,或者是通过自己修改后缀名 ...
- SpringMVC最详细笔记partⅠ
一.springMVC-quickStar 解决maven加载项目过慢 archetypeCatalog internal 导入依赖 <!-- 版本锁定 --> <propertie ...
- JSP(二)----指令,注释,内置对象
## JSP 1.指令 * 作用:用于配置JSP页面,导入资源文件 * 格式: <%@ 指令名称 属性名1=属性值1 属性名2=属性值2 %> <%@ page con ...
- jvm:内存结构(堆、方法区、程序计数器、本地方法栈、虚拟机栈)
1.jvm内存结构 静态编译:把java源文件编译成字节码文件class,这个时候class文件以静态方式存在. 类加载器:把java字节码文件加载到内存中 方法区:将字节码放到方法区作为元数据(简单 ...
- Linux时间和现实时间不同步解决方案
输入三条命令 yum install ntpdate -y ntpdate tiger.sina.com.cnping tiger.sina.com.cn 然后输入date检查时间是否已经同步
- TensorFlow系列专题(十一):RNN的应用及注意力模型
磐创智能-专注机器学习深度学习的教程网站 http://panchuang.net/ 磐创AI-智能客服,聊天机器人,推荐系统 http://panchuangai.com/ 目录: 循环神经网络的应 ...
- 渗透测试之Web安全
写在前面: 渗透测试包含但不限于Web安全 渗透测试并不相当于Web渗透 Web安全学习是入门渗透测试最容易的途径,门槛最低 Web安全入门: 基础入门 整体框架 SQL注入 XSS攻击 业务逻辑漏洞 ...