Flink学习笔记:Connectors概述
本文为《Flink大数据项目实战》学习笔记,想通过视频系统学习Flink这个最火爆的大数据计算框架的同学,推荐学习课程:
Flink大数据项目实战:http://t.cn/EJtKhaz
1. 各种Connector
1.1Connector是什么鬼
Connectors是数据进出Flink的一套接口和实现,可以实现Flink与各种存储、系统的连接
注意:数据进出Flink的方式不止Connectors,还有:
1.Async I/O(类Source能力):异步访问外部数据库
2.Queryable State(类Sink能力):当读多写少时,外部应用程序从Flink拉取需要的数据,而不是Flink把大量数据推入外部系统(后面再讲)
1.2哪些渠道获取connector
预定义Source和Sink:直接就用,无序引入额外依赖,一般用于测试、调试。
捆绑的Connectors:需要专门引入对应的依赖(按需),主要是实现外部数据进出Flink
1.Apache Kafka (source/sink)
2.Apache Cassandra (sink)
3.Amazon Kinesis Streams (source/sink)
4.Elasticsearch (sink)
5.Hadoop FileSystem (sink)
6.RabbitMQ (source/sink)
7.Apache NiFi (source/sink)
8.Twitter Streaming API (source)
Apache Bahir
1.Apache ActiveMQ (source/sink)
2.Apache Flume (sink)
3.Redis (sink)
4.Akka (sink)
5.Netty (source)
1.3预定义Source
预定义Source包含以下几类:
1.基于文件
readTextFile
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnviro nment();
DataStream<String> lines = env.readTextFile("file:///path");
readFile
DataStream<String> lines = env.readFile(inputFormat, "file:///path");
2.基于Socket
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnviro nment();
DataStream<String> socketLines = env .socketTextStream("localhost", 9998);
3.基于Elements 和Collections
fromElements
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnviro nment();
DataStream<String> names = env.fromElements("hello", "world", "!");
fromCollections
List<String> list = new ArrayList<String>(); list.add("Hello"); list.add("world");
list.add("!");
DataStream<String> names = env.fromCollection(list);
使用场景: 应用本地测试,但是流处理应用会出现Finished的状态
1.4预定义Sink
stream.print() /printToErr()(注: 线上应用杜绝使用,采用抽样打印或者日志的方式)
stream.writeAsText("/path/to/file")/ TextOutputFormat
stream.writeAsCsv(“/path/to/file”)/ CsvOutputFormat
writeUsingOutputFormat() / FileOutputFormat
stream.writeToSocket(host, port, SerializationSchema)
1.5队列系统Connector(捆绑)
支持Source 和 Sink
需要专门引入对应的依赖(按需),主要是实现外部数据进出Flink
1.Kafka(后续专门讲)
2.RabbitMQ
1.6存储系统Connector(捆绑)
只支持Sink
1.HDFS
2.ElasticSearch
3.Redis
4.Apache Cassandra
1.7 Source容错性保证

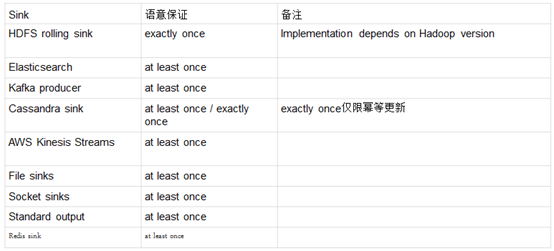
1.8 Sink容错性保证
2. 自定义Source与Sink
2.1自定义Source
1.实现SourceFunction(非并行,并行度为1)
1)适用配置流,通过广播与时间流做交互
2)继承SourceFuncion, 实现run 方法
3)cancel 方法需要处理好(cancel 应用的时候,这个方法会被调用)
4)基本不需要做容错性保证
2.实现ParallelSourceFunction
1)实现ParallelSourceFunction类或者继承RichParallelSourceFunction。
2)实现切分数据的逻辑
3)实现CheckpointedFunction接口,来保证容错保证。
4)Source 拥有回溯读取,可以减少的状态的保存。
3.继承RichParallelSourceFunction
2.2自定义Sink
1)实现SinkFunction 接口或者继承RichSinkFunction。
2)实现CheckpointedFunction, 做容错性保证。

Flink学习笔记:Connectors概述的更多相关文章
- Apache Flink学习笔记
Apache Flink学习笔记 简介 大数据的计算引擎分为4代 第一代:Hadoop承载的MapReduce.它将计算分为两个阶段,分别为Map和Reduce.对于上层应用来说,就要想办法去拆分算法 ...
- Flink学习笔记:Connectors之kafka
本文为<Flink大数据项目实战>学习笔记,想通过视频系统学习Flink这个最火爆的大数据计算框架的同学,推荐学习课程: Flink大数据项目实战:http://t.cn/EJtKhaz ...
- Flink学习笔记-新一代Flink计算引擎
说明:本文为<Flink大数据项目实战>学习笔记,想通过视频系统学习Flink这个最火爆的大数据计算框架的同学,推荐学习课程: Flink大数据项目实战:http://t.cn/EJtKh ...
- Flink学习笔记:Flink开发环境搭建
本文为<Flink大数据项目实战>学习笔记,想通过视频系统学习Flink这个最火爆的大数据计算框架的同学,推荐学习课程: Flink大数据项目实战:http://t.cn/EJtKhaz ...
- flink学习笔记:DataSream API
本文为<Flink大数据项目实战>学习笔记,想通过视频系统学习Flink这个最火爆的大数据计算框架的同学,推荐学习课程: Flink大数据项目实战:http://t.cn/EJtKhaz ...
- flink学习笔记-数据源(DataSource)
说明:本文为<Flink大数据项目实战>学习笔记,想通过视频系统学习Flink这个最火爆的大数据计算框架的同学,推荐学习课程: Flink大数据项目实战:http://t.cn/EJtKh ...
- flink学习笔记-各种Time
说明:本文为<Flink大数据项目实战>学习笔记,想通过视频系统学习Flink这个最火爆的大数据计算框架的同学,推荐学习课程: Flink大数据项目实战:http://t.cn/EJtKh ...
- Flink学习笔记:Flink Runtime
本文为<Flink大数据项目实战>学习笔记,想通过视频系统学习Flink这个最火爆的大数据计算框架的同学,推荐学习课程: Flink大数据项目实战:http://t.cn/EJtKhaz ...
- Flink学习笔记:Flink API 通用基本概念
本文为<Flink大数据项目实战>学习笔记,想通过视频系统学习Flink这个最火爆的大数据计算框架的同学,推荐学习课程: Flink大数据项目实战:http://t.cn/EJtKhaz ...
随机推荐
- 安卓Animation类与xml制作动画
有时要对控件添加一点动画效果,在安卓中,动画效果也是一个类,也就是Animation类.把动画效果这个类弄好后,在与控件类关联到一起,就可以实现控件有一些动作特效这样的效果了.动画效果的定义,要在xm ...
- cuteFTP软件往linux中上传文件时报…
我是在win7和VM中的ubuntu传输文件: 使用一个客户端,可以正常的连接,但是当上传文件时,总是报553 Could not create file错误信息. 主要原因是新建的文件夹没有更改权限 ...
- Nginx配置之基于域名的虚拟主机
1.配置好DNS解析 大家好,今天我给大家讲解下在Linux系统下DNS服务器的基本架设,正向解析,反向解析,负载均衡,还有从域以及一个服务器两个域或者多个域的情况. 实验环境介绍:1.RHEL5.1 ...
- 2014蓝桥杯B组初赛试题《奇怪的分式》
题目描述: 上小学的时候,小明经常自己发明新算法.一次,老师出的题目是: 1/4 乘以 8/5 小明居然把分子拼接在一起,分母拼接在一起,答案是:18/45 (参见图1.png) ...
- AlphaPose ubuntu16 python2安装
#https://www.tensorflow.org/install/install_linux#ValidateYourInstallation #https://github.com/MVIG- ...
- PCL struct“flann::SearchParams参数错误
最近在使用PCL的KdTreeFLANN的时候报错:error C2079: “pcl::KdTreeFLANN<PointT>::param_radius_”使用未定义的 struct“ ...
- Django框架 之 Auth用户认证
Django框架 之 Auth用户认证 浏览目录 auth模块 user对象 一.auth模块 1 from django.contrib import auth django.contrib.aut ...
- glib hash库GHashTable的使用实例
前言 hash表是一种key-value访问的数据结构,hash表存储的数据能够很快捷和方便的去查询.在很多工程项目都需要使用到hash表来存储数据.对于hash表的详细说明这里就不进行阐述了,不了解 ...
- 解决IE与FF 中 input focus 光标移动在最后的方案
只要把input元素的id传进来即可 function moveCursor(id) { var id = document.getElementById(id); id.focus(); var ...
- SQLServer查询所有子节点
用CTE递归 ;with f as ( select * from tab where id=1 union all select a.* from tab as a inner join f as ...