【Hbase一】基础
此笔记仅用于作者记录复习使用,如有错误地方欢迎留言指正,作者感激不尽,如有转载请指明出处
Hbase基础
Hbase定义
HBase是一个开源的非关系型分布式数据库(NoSQL),它参考了谷歌的BigTable建模,实现的编程语言为 Java。
是Apache软件基金会的Hadoop项目的一部分,运行于HDFS文件系统之上,因此可以容错地存储海量稀疏的数据
行存储 v s 列存储
行存储:
– 优点:写入一次性完成,保持数据完整性
– 缺点:数据读取过程中产生冗余数据,若有少量数据可以忽略列存储
– 优点:读取过程,不会产生冗余数据,特别适合对数据完整性要求不高的大数据领域
– 缺点:写入效率差,保证数据完整性方面差
Hbase数据模型
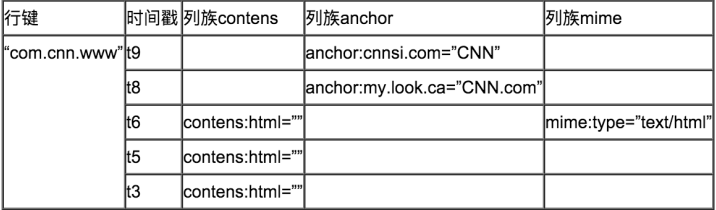
- RowKey:是Byte array,是表中每条记录的“主键”,方便快速查找,Rowkey的设计非常重要。
- Column Family:列族,拥有一个名称(string),包含一个或者多个相关列
- Column:属于某一个columnfamily,familyName:columnName,每条记录可动态添加
- Version Number:类型为Long,默认值是系统时间戳,可由用户自定义
- Value(Cell):Byte array
Hbase物理模型
Hbase一张表由一个或多个Hregion(Region)组成
记录之间按照Row Key的字典序排列
如图

Region按大小分割的,每个表一开始只有一个region,随着数据不断插入表,region不断增大,当增大到一个阀值的时候,Hregion就会等分会两个新的Hregion。当table中的行不断增多,就会有越来越多的Hregion。
如图:
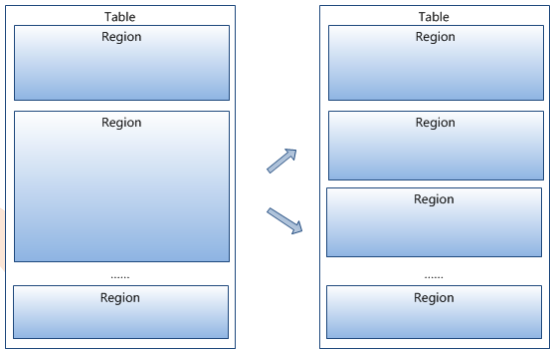
Region配置,默认大小10GB,如果在没有自定义配置的情况下,超过10GB就会自动分裂
当对某一行进行修改时,会锁定一整行数据,也就是对这一样进行加锁,当对某一行的某一个字段进行读操作时,其他字段也不允许被操作,
一个RegionServer可以包含多个Region,内部管理了一系列的HRegion
如图:
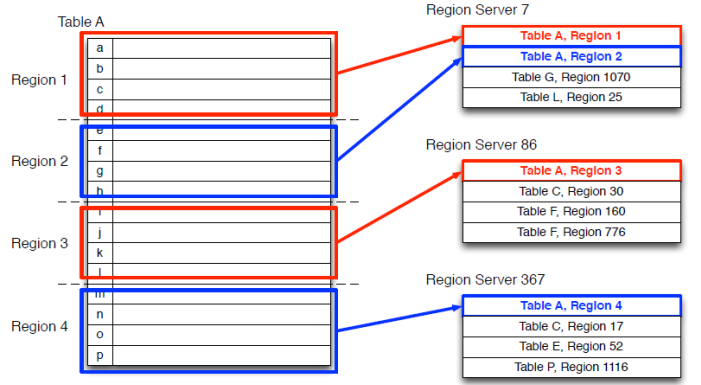
对应结构
表 -> HTable
• 按RowKey范围分的Region-> HRegion ->Region Servers
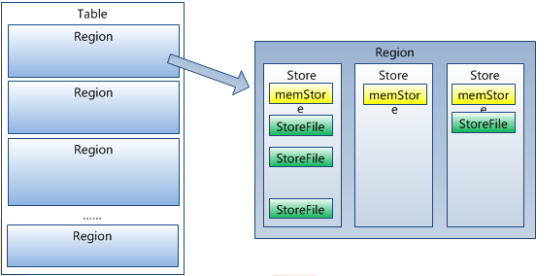
• HRegion按列族(Column Family) ->多个HStore
• HStore -> memstore(默认128M,超过128M就会自动往磁盘上split) + HFiles(均为有序的KV)
• HFiles -> HDFSHRegion是Hbase中分布式存储和负载均衡的最小单元,最小单元就表示不同的Hregion可以分布在不同的HRegion server上,但一个Hregion是不会拆分到多个server上的
如图:

HRegion虽然是分布式存储的最小单元,但并不是存储的最小单元
如图:
Hbase系统架构
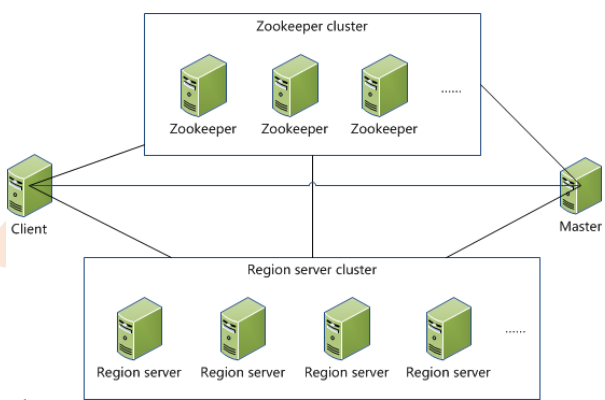
Client
– 访问Hbase的接口,并维护Cache加速Region Server的访问Master(主)
– 负载均衡,分配Region到RegionServer
– DLL,增删查改 -> table,cf,namespace
– 类似namenode,管理一些元数据
– ACL权限控制- HRegionServer(从)
- 维护Region,负责Region的IO请求
- 管理和存放本地的HRegion
- 读写HDFS,提供IO操作
- 本地化:HRegion的数据尽量和数据所属的DataNode在一起,但是这个本地化不能够总是满足和实现
- Zookeeper
- 保证集群中只有一个Master
- 存储所有Region的入口(ROOT)地址
- 实时监控Region Server的上下线信息,并通知Master

Hbase的容错
- ZooKeeper协调集群所有节点的共享信息,在HMaster和HRegionServer连接到ZooKeeper后创建Ephemeral节点,并使用Heartbeat机制维持这个节点的存活状态,如果某个Ephemeral节点实效,则HMaster会收到通知,并做相应的处理。
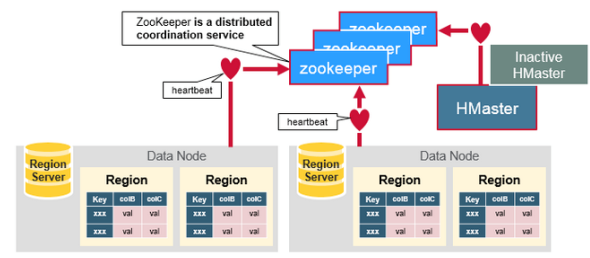
- 除了HDFS存储信息,HBase还在Zookeeper中存储信息,其中的znode信息:
- /hbase/root-region-server ,Root region的位置
- /hbase/table/-ROOT-,根元数据信息
- /hbase/table/.META.,元数据信息
- /hbase/master,当选的Mater
- /hbase/backup-masters,备选的Master
- /hbase/rs ,Region Server的信息
- /hbase/unassigned,未分配的Region
- Master容错:
- Zookeeper重新选择一个新的Master
- 无Master过程中,数据读取仍照常进行;
- 无master过程中,region切分、负载均衡等无法进行
- Zookeeper重新选择一个新的Master
- Region Server容错:
- 定时向Zookeeper汇报心跳,如果一旦时间内未出现心跳Master将该RegionServer上的Region重新分配到其他RegionServer上,失效服务器上“预写”日志由主服务器进行分割并派送给新的RegionServer
- Zookeeper容错:
- Zookeeper是一个可靠地服务,一般配置3或5个Zookeeper实例
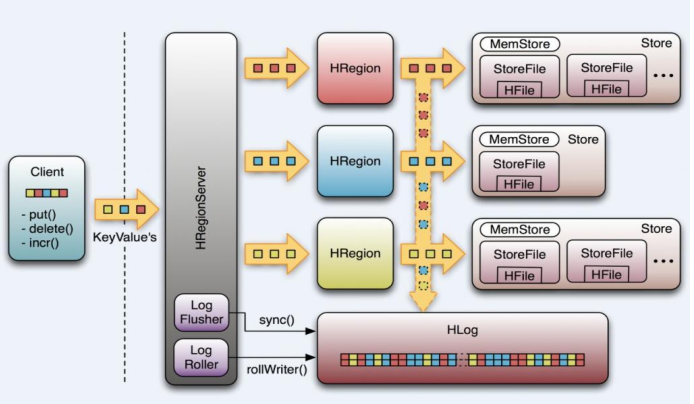
WAL(Write-Ahead-Log)预写
日志是Hbase的RegionServer在处理数据插入和删除的过程中用来记录操作内容的一种日志
在每次Put、 Delete等一条记录时,首先将其数据写入到RegionServer对应的HLog文
件的过程客户端往RegionServer端提交数据的时候,会写WAL日志,只有当WAL日志写成功以后,客户端才会被告诉提交数据成功,如果写WAL失败会告知客户端提交失败
数据落地的过程
在一个RegionServer上的所有的Region都共享一个HLog,一次数据的提交是先写WAL,写入成功后,再写memstore。当memstore值到达一定阈值,就会形成一个个StoreFile(理解为HFile格式的封装,本质上还是以HFile的形式存储的)
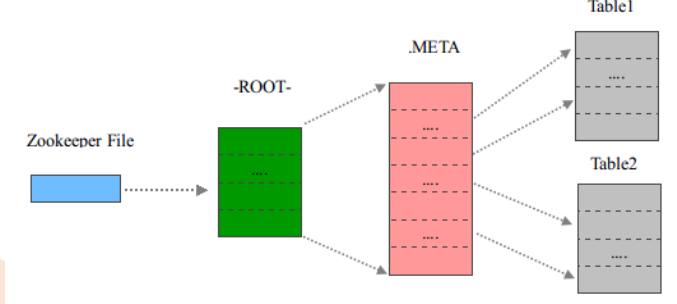
Hbase特殊的表
ROOT- 表和.META.表是两个比较特殊的表
.META.记录了用户表的Region信息,.META.可以有多个regoin。
-ROOT-记录了.META.表的Region信息,-ROOT-只有一个region,Zookeeper中记录了-ROOT-表的location
- Hbase 0.96之后去掉了-ROOT- 表,因为:
- 三次请求才能直到用户Table真正所在的位置也是性能低下的
- 即使去掉-ROOT- Table,也还可以支持2^17(131072)个Hregion,对于集群来说,存储空间也足够
- 所以目前流程为:
- 从ZooKeeper(/hbase/meta-region-server)中获取hbase:meta的位置(HRegionServer的位置),缓存该位置信息【没有图中绿色的部分】
- 从HRegionServer中查询用户Table对应请求的RowKey所在的HRegionServer,缓存该位置信息
- 从查询到HRegionServer中读取Row。
合并
region的合并:尽量把小的region合并到一个大的,理想情况下,每个region的请求量是一样的(不能保证数据量一样)
storefile的合并
如果Hbase当做MapReduce的输入源的话,一个map对应一个region
Hbase的Compaction和Split
问题:随着写入不断增多,flush次数不断增多,Hfile文件越来越多,所以Hbase需要对这些文件进行合并
Compaction会从一个region的一个store中选择一些hfile文件进行合并。合并说来原理很简单,先从这些待合并的数据文件中读出KeyValues,再按照由小到大排列后写入一个新的文件中。之后,这个新生成的文件就会取代之前待合并的所有文件对外提供服务
Minor Compaction:是指选取一些小的、相邻的StoreFile将他们合并成一个更大的StoreFile,在这个过程中不会处理已经Deleted或Expired的Cell。一次Minor Compaction的结果是更少并且更大的StoreFile
Major Compaction:是指将所有的StoreFile合并成一个StoreFile,这个过程还会清理三类无意义数据:被删除的数据、 TTL过期数据、版本号超过设定版本号的数据
- Major Compaction时间会持续比较长,整个过程会消耗大量系统资源,对上层业务有比较大的影响
- 因此线上业务都会将关闭自动触发Major Compaction功能,改为手动在业务低峰期触发
Compaction本质:使用短时间的IO消耗以及带宽消耗换取后续查询的低延迟
compact的速度远远跟不上HFile生成的速度,这样就会使HFile的数量会越来越多,导致读性能急剧下降。为了避免这种情况,在HFile的数量过多的时候会限制写请求的速度
- Split
- 当一个Region太大时,将其分裂成两个Region
Split和Major Compaction可以手动或者自动做
【Hbase一】基础的更多相关文章
- HBase零基础高阶应用实战(CDH5、二级索引、实践、DBA)
HBase是一个分布式的.面向列的开源数据库,该技术来源于 Fay Chang 所撰写的Google论文“Bigtable:一个结构化数据的分布式存储系统”.就像Bigtable利用了Google文件 ...
- HBase入门基础教程之单机模式与伪分布式模式安装(转)
原文链接:HBase入门基础教程 在本篇文章中,我们将介绍Hbase的单机模式安装与伪分布式的安装方式,以及通过浏览器查看Hbase的用户界面.搭建HBase伪分布式环境的前提是我们已经搭建好了Had ...
- HBase框架基础(五)
* HBase框架基础(五) 本节主要介绍HBase中关于分区的一些知识. * HBase的RowKey设计 我们为什么要讨论rowKey的设计?或者说为什么很多工作岗位要求有rowKey的优化设计经 ...
- HBase框架基础(四)
* HBase框架基础(四) 上一节我们介绍了如何使用HBase搞一些MapReduce小程序,其主要作用呢是可以做一些数据清洗和分析或者导入数据的工作,这一节我们来介绍如何使用HBase与其他框架进 ...
- HBase框架基础(三)
* HBase框架基础(三) 本节我们继续讨论HBase的一些开发常识,以及HBase与其他框架协调使用的方式.在开始之前,为了框架之间更好的适配,以及复习之前HBase的配置操作,请使用cdh版本的 ...
- HBase框架基础(一)
* HBase框架基础(一) 官方网址:http://hbase.apache.org/ * HBase是什么妖怪? 要解释HBase,我们就先说一说经常接触到的RDBMS,即关系型数据库: ** m ...
- HBase框架基础(二)
* HBase框架基础(二) 上一节我们了解了HBase的架构原理和模块组成,这一节我们先来聊一聊HBase的读写数据的过程. * HBase的读写流程及3个机制 HBase的读数据流程: 1.HRe ...
- 【CDN+】 Hbase入门 以及Hbase shell基础命令
前言 大数据的基础离不开Hbase, 本文就hbase的基础概念,特点,以及框架进行简介, 实际操作种需要注意hbase shell的使用. Hbase 基础 官网:https://hbase.ap ...
- HBase入门基础教程 HBase之单机模式与伪分布式模式安装
在本篇文章中,我们将介绍Hbase的单机模式安装与伪分布式的安装方式,以及通过浏览器查看Hbase的用户界面.搭建HBase伪分布式环境的前提是我们已经搭建好了Hadoop完全分布式环境,搭建Hado ...
- hbase shell基础和常用命令详解(转)
HBase shell的基本用法 hbase提供了一个shell的终端给用户交互.使用命令hbase shell进入命令界面.通过执行 help可以看到命令的帮助信息. 以网上的一个学生成绩表的例子来 ...
随机推荐
- 基本算法思想Java实现的详细代码
基本算法思想Java实现的详细代码 算法是一个程序的灵魂,一个好的算法往往可以化繁为简,高效的求解问题.在程序设计中算法是独立于语言的,无论使用哪一种语言都可以使用这些算法,本文笔者将以Java语言为 ...
- monkeyrunner之安卓开发环境搭建(二)
在上一篇文章-安卓开发环境搭建中,我们创建并启动了eclipse自带的安卓模拟器,该模拟器不仅启动慢,而且在使用过程中的反应速度也是出奇的差,经常出现卡机现象.为了解决这种现象,因此,我们又寻找到了更 ...
- Linux 配置 ss
Linux 配置 Shadowsocks 标签(空格分隔): ss VPS 1.首先安装 sudo pip install shadowsocks 2.然后在指定位置新建shadowsocks.jso ...
- 实验,暂停oracle后台进程
有时出于测试需求,需要暂停oracle的某些后台进程,此时以暂停lgwr进程为例 使用sysdba连接到数据库查询到LGWR进程的PID:SQL> select prc.pid from v$b ...
- CRM订单状态的Open, In process和Completed这些条目是从哪里来的
Service Order的状态字段里的这些字段从哪里带出来的?我们可能会想当然的认为是从后台配的Status profile里带出来的.事实并非如此. 这个transaction type根本没有分 ...
- 2016 China Collegiate Programming Contest Final
2016 China Collegiate Programming Contest Final Table of Contents 2016 China Collegiate Programming ...
- LocalDB的奇怪问题
属性 MasterDBPath 不可用于 信息“Microsoft.SqlServer.Management.Smo.Information”.该对象可能没有此属性,也可能是访问权限不足而无法检索. ...
- 随机森林算法-Deep Dive
0-写在前面 随机森林,指的是利用多棵树对样本进行训练并预测的一种分类器.该分类器最早由Leo Breiman和Adele Cutler提出.简单来说,是一种bagging的思想,采用bootstra ...
- centos7 编译安装nginx1.16.0( 完整版 )
一.安装依赖包 yum install -y gcc gcc-c++ pcre pcre-devel zlib zlib-devel openssl openssl-devel 依赖包说明: 1.编译 ...
- 【题解】P1516 青蛙的约会(Exgcd)
洛谷P1516:https://www.luogu.org/problemnew/show/P1516 思路: 设两只青蛙跳了T步 则A的坐标为X+mT B的坐标为Y+nT 要使他们相遇 则满足: ...