EM算法浅析(二)-算法初探
EM算法浅析,我准备写一个系列的文章:
一、EM算法简介
在EM算法之一--问题引出中我们介绍了硬币的问题,给出了模型的目标函数,提到了这种含隐变量的极大似然估计要用EM算法解决,继而罗列了EM算法的简单过程,当然最后看到EM算法时内心是懵圈的,我们也简要的分析了一下,希望你在看了前一篇文章后,能大概知道E步和M步的目的和作用。为了加深一下理解,我们回过头来,重新看下EM算法的简单介绍:
输入:观测变量数据Y,隐变量数据Z,联合分布$P(Y,Z|\theta)$,条件分布$P(Z|Y,\theta)$
输出:模型参数$\theta$
(1)选择参数初值$\theta^{(0)}$,进行迭代;
(2)E步:记$\theta^{(i)}$为第i次迭代参数$\theta$的估计值,在i+1次迭代的E步,计算:$$Q(\theta,\theta^{(i)}) =E_Z[logP(Y,Z | \theta)|\color{red}{Y,\theta^{(i)}}]\ =\sum_Z{[logP(Y,Z|\theta)]\color{red}{[P(Z|Y,\theta^{(i)})]}} \tag{1}$$
(3)M步:求使得$Q(\theta,\theta^{(i)})$极大化的$\theta$,确定i+1次迭代的参数估计值$\theta^{(i+1)}$
$$\theta^{(i+1)}=argmax_\theta Q(\theta,\theta^{(i)}) \tag{2}$$
(4)重复第(2)步和第(3)步,直到收敛
上述E步中的函数$Q(\theta,\theta^{(i)})$是EM算法的核心,称之为Q函数(Q function)。
Q函数是完全数据的对数似然函数$logP(Y,Z | \theta)$关于在给定观测数据$Y$和当前参数$\theta^{(i)}$下,对未观测数据Z的条件概率分布$P(Z|Y,\theta^{(i)})$的期望。
让我们且慢下来看下Q函数,这里重点词很多。首先,很显然Q函数是个期望,这没有问题;其次这个期望是某个函数(完全数据下的对数似然函数)关于某个概率分布(在xxx条件下,未观测数据Z的条件概率分布)的期望。读到这里的你可能对函数关于某个概率分布的期望不太明白。我就在这个插个小插曲介绍下,懂的可以略过:
知识点一:条件数学期望
上面牵扯到的函数关于某个概率分布的期望,在数学中叫条件数学期望。
首先,条件概率我们已经熟悉,就是在事件$ {X=x_i}$已经发生的条件下,事件${Y=y_j}$发生的概率,记作$P { Y=y_j|X=x_i } $;
而条件期望是一个实数随机变量的相对于一个条件概率分布的期望值。设X和Y是离散随机变量,则X的条件期望在给定事件Y = y条件下是x的在Y的值域的函数:
(3)
个人感觉可以理解为在各个条件概率分布下的加权平均值。
那么继续理解Q函数,看E步中公式(1),函数$logP(Y,Z| \theta)$是关于Z的,而在$Y,\theta^{(i)}$的条件下就是指隐含变量Z在此条件下,也就是在概率分布$P(Z|Y,\theta^{(i)})$条件下,所以公式1中红色部分的变形就很好理解了。对数似然函数$logP(Y,Z| \theta)$就是完全数据的对数似然函数,里面有隐变量Z,所以想要求此函数中Z的条件数学期望就要加入对Z的条件概率分布。
在E步获得了隐含变量的条件数学期望后,我们要做的就是拿着个值取求模型参数$\theta$使得Q函数的值最大(极大似然估计求导)。所以,在M步中,对于$Q(\theta,\theta^{(i)})$求极大值,得到$\theta^{(i+1)}$,完成一次迭代$\theta^{(i)} \to \theta^{(i+1)}$,我们之后在证明每次迭代必定会使得Q函数值增大或者能达到局部最优(第二部分提供证明)。最后,停止的迭代条件一般是要求设置比较小的值$\epsilon_1,\epsilon_2$,若满足$||\theta^{(i+1)}-\theta^{(i)}||<\epsilon_1$或者$||Q(\theta^{(i+1)},\theta^{(i+1)})-Q(\theta^{(i)},\theta^{(i)})||<\epsilon_2$。
二、EM算法导出
为什么EM算法能近似实现观测数据的极大似然估计呢?我们面对一个含有隐变量的概率模型,目标是极大化观测数据(不完全数据)Y关于参数$\theta$的对数似然函数,即最大化:
$$L(\theta) =logP(Y|\theta) =log\sum_Z{P(Y,Z|\theta)} =log(\sum_Z{P(Y|Z,\theta)P(Z|\theta)}) \tag{4}$$
这个式子的困难就是公式(4)中含有未观测数据,而且含有和(或者积分)的对数。
而EM算法是通过迭代逐步近似极大化$L(\theta)$的。这里假设第i此迭代后$\theta$的估计值是$\theta^{(i)}$,那么我们计算下新的估计值$\theta$能否使得$L(\theta)$增加,即$L(\theta)>L(\theta^{(i)})$,并逐步到达最大值?于是我们考虑两者的差值:
$$L(\theta)-L(\theta^{(i)})=log \left( \sum_Z{P(Y|Z,\theta)P(Z|\theta)} \right)-logP(Y|\theta^{(i)}) \tag{5}$$
对于公式(5)我们需要一个变形,但是变形需要知道Jensen inequality。
知识点二:Jensen inequality(詹森不等式)
$$log\sum_{j}{\lambda_{j}y_j} \ge \sum_j{\lambda_j logy_j}$$,其中$\lambda_j \ge 0, \sum_j{\lambda_j = 1}$
稍微了解完Jensen不等式,我们继续来看公式(5),首先把公式(5)变形,前部分中分子分母同时乘以一个$\color{blue}{P(Y|Z,\theta^{(i)})}$,清晰起见,我们标上蓝色和中括号,如下:
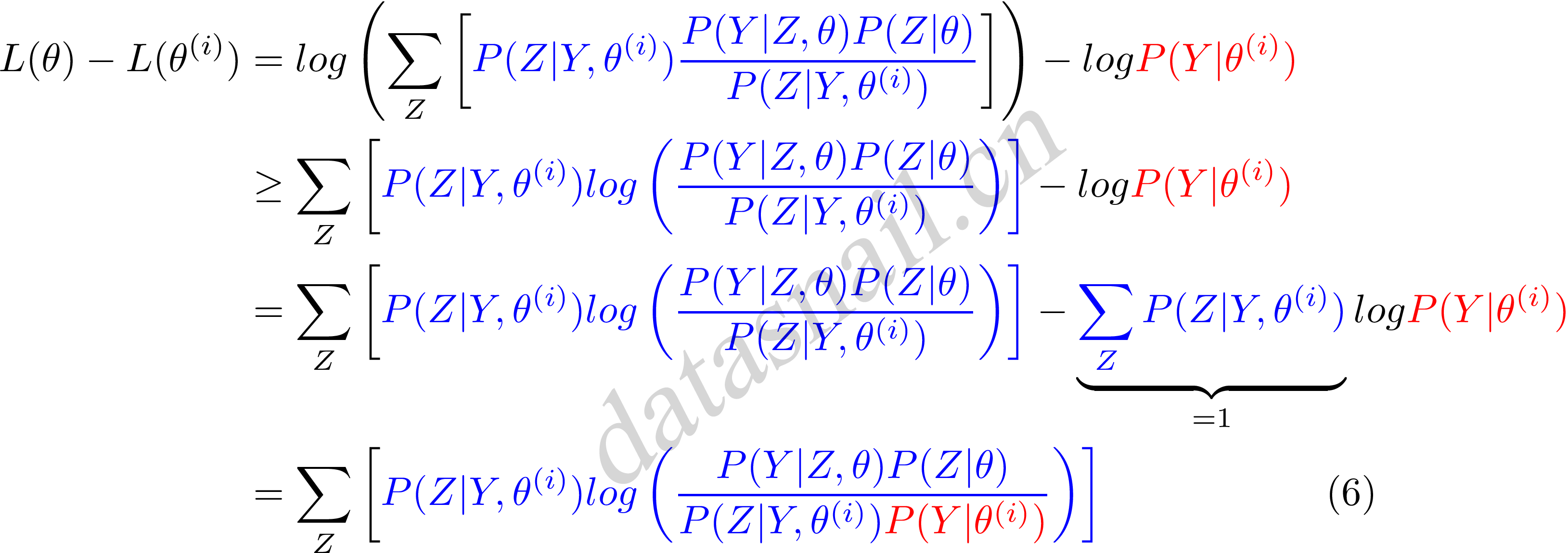
这里我们令
$$B(\theta,\theta^{(i)}) = L(\theta^{(i)}) + \sum_Z \left[ \color{blue}{P(Z|Y,\theta^{(i)})} log \left( \frac{P(Y|Z,\theta)P(Z|\theta)}{\color{blue}{P(Z|Y,\theta^{(i)})}\color{ForestGreen}{P(Y|\theta^{(i)})}} \right) \right] \tag{7}$$
则可以得到:
$$L(\theta) \ge B(\theta,\theta^{(i)}) \tag{8}$$
可以知道$B(\theta,\theta^{(i)})$函数是$L(\theta)$的一个下界,且由公式(7)可知:
$$L(\theta^{(i)}) = B(\theta^{(i)},\theta^{(i)})$$
因此,任何可以使得$B(\theta,\theta^{(i)})$增大的$\theta$,也可以使$L(\theta)$增大。为了使得$L(\theta)$有尽可能的大的增长,选择$\theta^{(i+1)}$使$B(\theta,\theta^{(i)})$达到极大,即:
$$\theta^{(i+1)}=argmax_\theta B(\theta,\theta^{(i)}) \tag{9}$$
现在求$\theta^{(i+1)}$,省略常数化项:
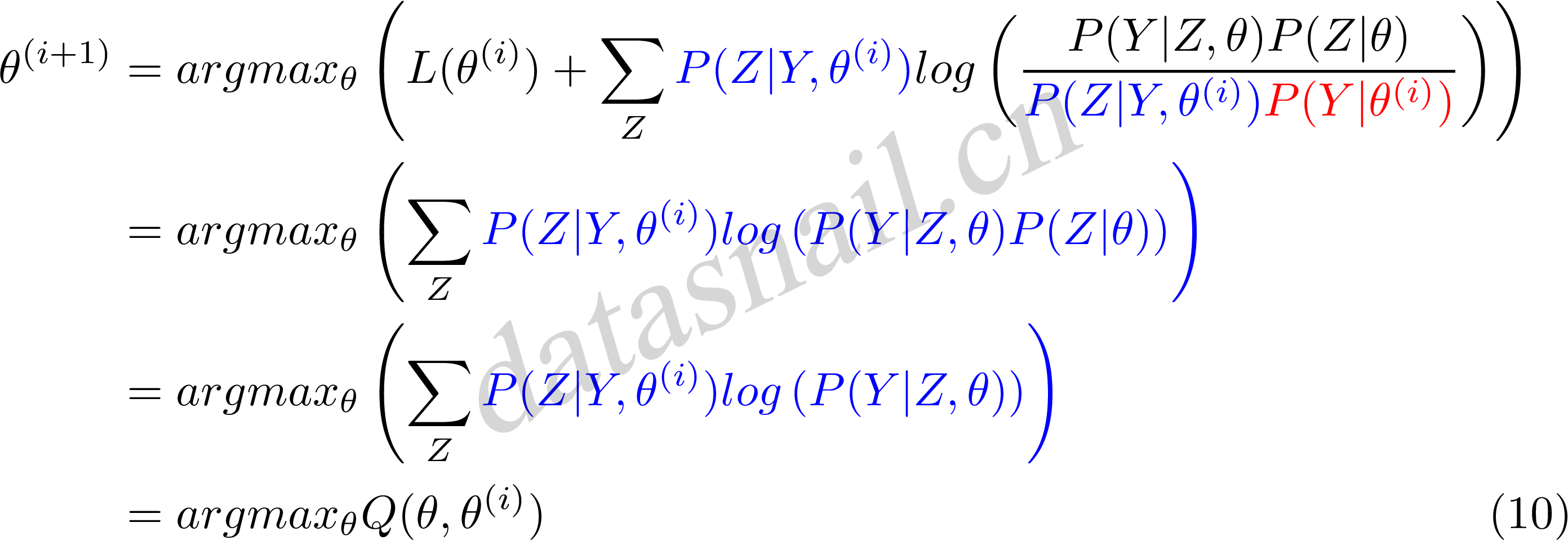
公式(10)中等价于EM算法的一次迭代,即求Q函及其极大化。所以,我们看到EM算法是通过不断求解下界的极大化逼近求解对数似然函数极大化的算法。就是一种局部的下限的不断构造,然后进一步求解。
三、EM算法应用
EM算法有很多应用,求分类、回归、标注等任务。比较广泛的就是GMM混合高斯模型、HMM隐马尔可夫训练问题等等。
EM算法浅析(二)-算法初探的更多相关文章
- AI算法测评(二)--算法测试流程
根据算法测试过程中遇到的一些问题和管理规范, 梳理出算法测试工作需要关注的一些点: 编号 名称 描述信息 备注 1 明确算法测试需求 明确测试目的 明确测试需求, 确认测试需要的数据及场景 明确算法服 ...
- EM算法浅析(一)-问题引出
EM算法浅析,我准备写一个系列的文章: EM算法浅析(一)-问题引出 EM算法浅析(二)-算法初探 一.基本认识 EM(Expectation Maximization Algorithm)算法即期望 ...
- 张洋:浅析PageRank算法
本文引自http://blog.jobbole.com/23286/ 很早就对Google的PageRank算法很感兴趣,但一直没有深究,只有个轮廓性的概念.前几天趁团队outing的机会,在动车上看 ...
- 算法(二)之遗传算法(SGA)
算法(二)之遗传算法(SGA) 遗传算法(Genetic Algorithm)又叫基因进化算法或进化算法,是模拟达尔文的遗传选择和自然淘汰的生物进化过程的计算模型,属于启发式搜索算法一种. 下面通过下 ...
- 70 数组的Kmin算法和二叉搜索树的Kmin算法对比
[本文链接] http://www.cnblogs.com/hellogiser/p/kmin-of-array-vs-kmin-of-bst.html [分析] 数组的Kmin算法和二叉搜索树的Km ...
- 浅析KMP算法
浅析KMP算法 KMP算法是一种线性字符串的匹配算法,将主串S与模式串T匹配. 首先朴素算法大家都会,就是直接从S的每一个位置开始,枚举比较,时间效率为O(nm),现在要想到一种化简的方式,使得时间复 ...
- 浅析PageRank算法
很早就对Google的PageRank算法很感兴趣,但一直没有深究,只有个轮廓性的概念.前几天趁团队outing的机会,在动车上看了一些相关的资料(PS:在动车上看看书真是一种享受),趁热打铁,将所看 ...
- 浅析nodeJS中的Crypto模块,包括hash算法,HMAC算法,加密算法知识,SSL协议
node.js的crypto在0.8版本,这个模块的主要功能是加密解密. node利用 OpenSSL库(https://www.openssl.org/source/)来实现它的加密技术, 这是因为 ...
- java排序算法(二):直接选择排序
java排序算法(二) 直接选择排序 直接选择排序排序的基本操作就是每一趟从待排序的数据元素中选出最小的(或最大的)一个元素,顺序放在已排好序的数列的最后,直到全部待排序的数据元素排完,它需要经过n- ...
随机推荐
- 【题解】洛谷P1445 [Violet]樱花 (推导+约数和)
洛谷P1445:https://www.luogu.org/problemnew/show/P1445 推导过程 1/x+1/y=1/n! 设y=n!+k(k∈N∗) 1/x+1/(n!+k)=1 ...
- ECMAScript6
ECMAScript6介绍 # ECMAScript 和 JavaScript 的关系是,前者是后者的规格,后者是前者的一种实现 # 有利于保证这门语言的开放性和中立性. # 标准在每年的 6 月份正 ...
- 7.Vue-Quill-Editor图片插入自定义
Vue-Quill-Editor图片插入自定义 前言: 因为在项目中前端采用了Vue来实现,正好用到了富文本编辑器这一块,于是,经过技术上的选择,决定使用Vue-Quill-Editor. 使用的过程 ...
- Qt学习交流(广告)
最近全面学习QT与c++,希望同行能够指教,于是打算建个群QQ群:85439482,欢迎大家,本群主要专注于QT皮肤库积累,软件架构以及标准c++学习.
- 寻找AP数
题目背景 正整数n是无穷的,但其中有些数有神奇的性质,我们给它个名字--AP数. 题目描述 对于一个数字i是AP数的充要条件是所有比它小的数的因数个数都没有i的因数个数多.比如6的因数是1 2 3 6 ...
- Super Reduced String
https://www.hackerrank.com/challenges/reduced-string/problem He wants to reduce the string to its sh ...
- webpack和sass功能简介
1.webpack webpack 是一个打包工具,为什么需要打包?因为有的人的脚本开发语言可能是 CoffeeScript 或者是 TypeScript,样式开发工具可能是 Less 或者 Sass ...
- Windows环境下安装redis及PHP Redis扩展
附带管理工具安装教程 安装环境 WNMP环境 参考教程:WIN10下WNMP开发环境部署 安装windows的redis服务 安装包下载 选择msi安装包下载并安装,下载可能会有点慢,请自行使用梯子. ...
- 微信小程序图片上传
uploadImage : function (){ wx.chooseImage({ count: 9, // 默认9 sizeType: ['original', 'compressed'], / ...
- Hive初识(一)
LOAD DATA语句 一般来说,在SQL创建表后,我们就可以使用INSERT语句插入数据.但在Hive中,可以使用LOAD DATA语句来插入数据. LOAD DATA [LOCAL] INPATH ...