python 爬取王者荣耀高清壁纸
一、前言
打过王者的童鞋一般都会喜欢里边设计出来的英雄吧,特别想把王者荣耀的英雄的高清图片当成电脑桌面
预览一下桌面吧:

是不是看着这样的桌面也很带感,_ (学会这个技术,你可以爬取其他网站的类似图片,哄妹子专用,O(∩_∩)O哈哈~)
二、程序实现
我们先去找一个靠谱的网站吧,自然而然的网站地址锁定在王者荣耀官网上,正好他给我们提供了壁纸页面 http://pvp.qq.com/web201605/wallpaper.shtml
一共14页构建我们的目标数据URL
随便多翻几页,用firebug 等调试工具,观察一下我们的请求列表,找到其中特别明显的图片list api
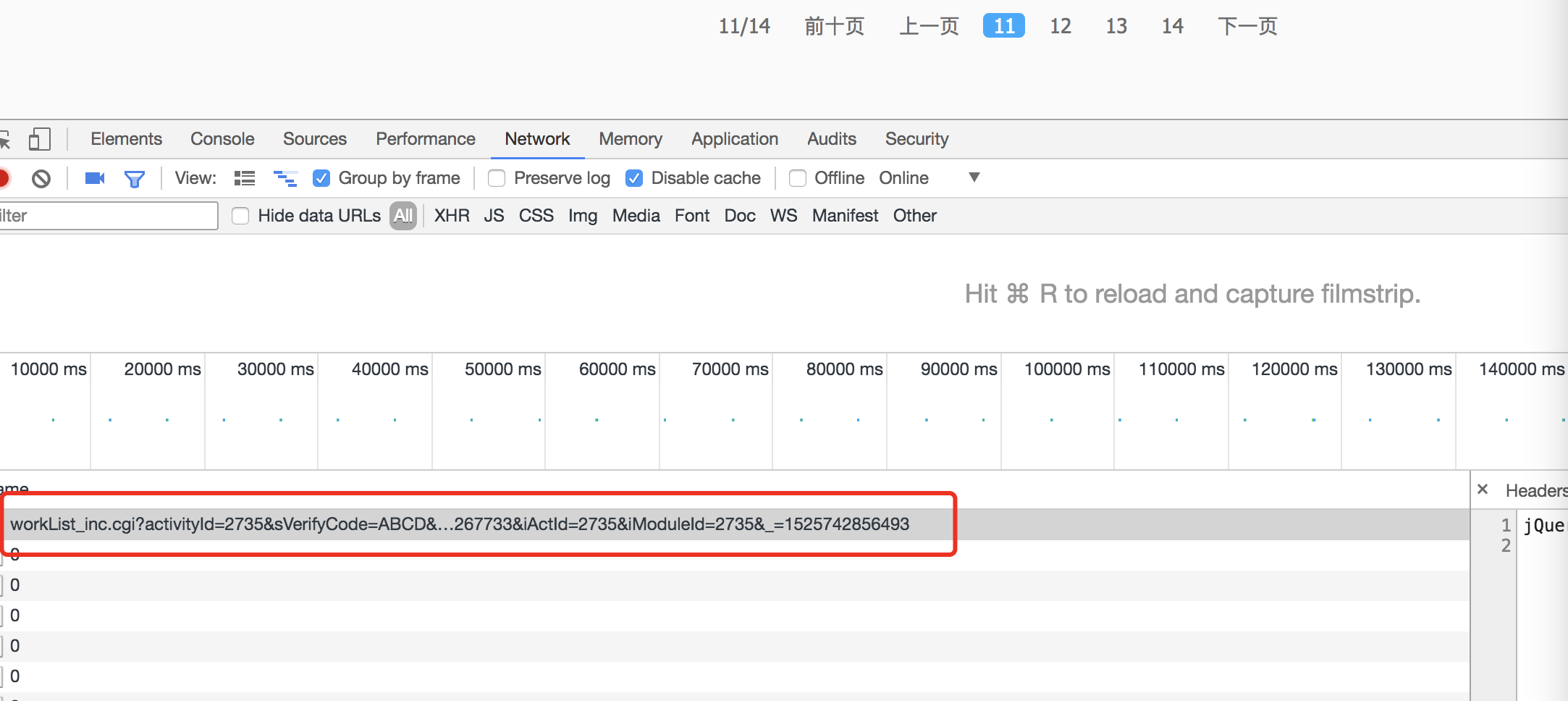
展开以后,特别详细的URL
http://apps.game.qq.com/cgi-bin/ams/module/ishow/V1.0/query/workList_inc.cgi?activityId=2735&sVerifyCode=ABCD&sDataType=JSON&iListNum=20&totalpage=0&page=10&iOrder=0&iSortNumClose=1&jsoncallback=jQuery17106927574791770883_1525742053044&iAMSActivityId=51991&everyRead=true&iTypeId=2&iFlowId=267733&iActId=2735&iModuleId=2735&=1525742856493
问题简单了就:
urls = [ "http://apps.game.qq.com/cgi-bin/ams/module/ishow/V1.0/query/workList_inc.cgi?activityId=2735&page=%d&sVerifyCode=ABCD&sDataType=JSON&iListNum=20&totalpage=0&iOrder=0&iSortNumClose=1&jsoncallback=jQuery1710881537174597735 6_1486710433816&iAMSActivityId=51991&_everyRead=true&iTypeId=2&iFlowId=267733&iActId=2735&iModuleId=2735&_=1486710458098" % (p) for p in range(0,14) ]
获取文档的内容:
这一步就比较简单了,requests 堪称写给人类的http 请求库,可以自己参看他的api 很强大,可以完成,任何手工在浏览器上的任何行为,用得好,你可以省掉很多的事儿,顺路贴一个api 链接吧 (http://www.python-requests.org/en/master/)[http://www.python-requests.org/en/master/]def loadUrlContent(url):
return requests.get(u).text解析文档内容 :
api 返回情况,大致如下: 是一个jsonp callback的返回
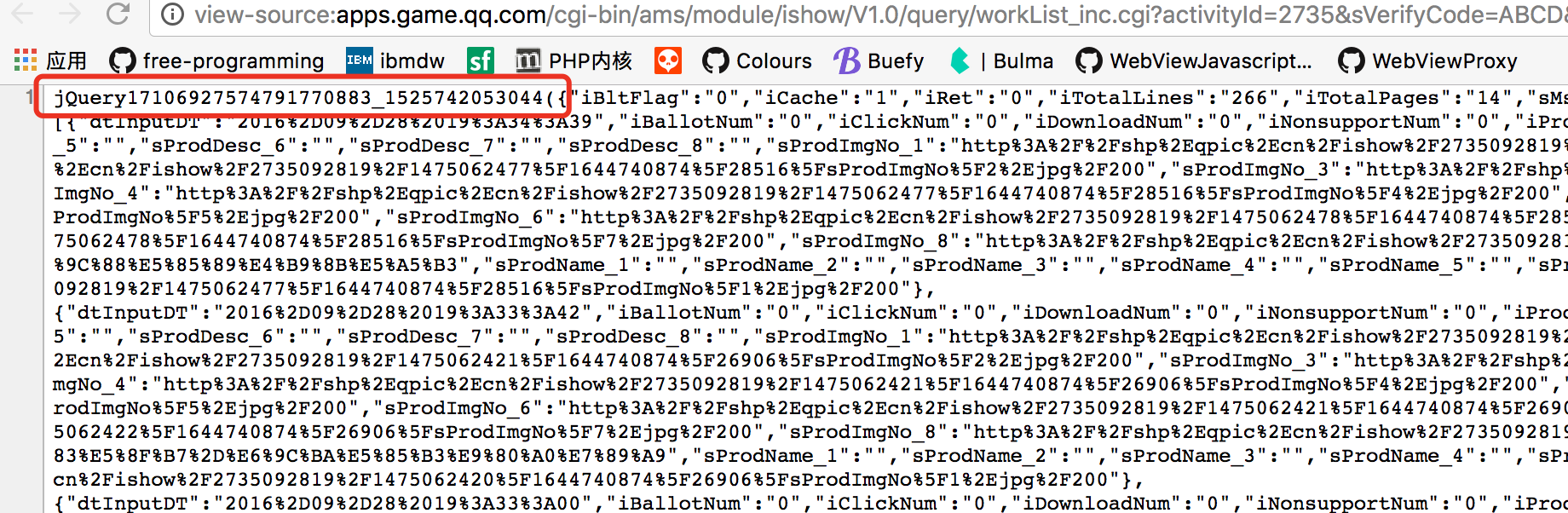
这种情况一般是callback后边对应了一个json对象,我们可以用python的 json 类库来解析:
解析数据千差万别,本文的数据相对简单,所以用了相对简单的处理方式:
## 这种解析数据的代码并不适用于所有的页面
def jsonContent(pageContent):
json_content = pageContent.split("(")[1].split(")")[0]
return json.loads(json_content)
解析完成以后的一个json对象属性如下:
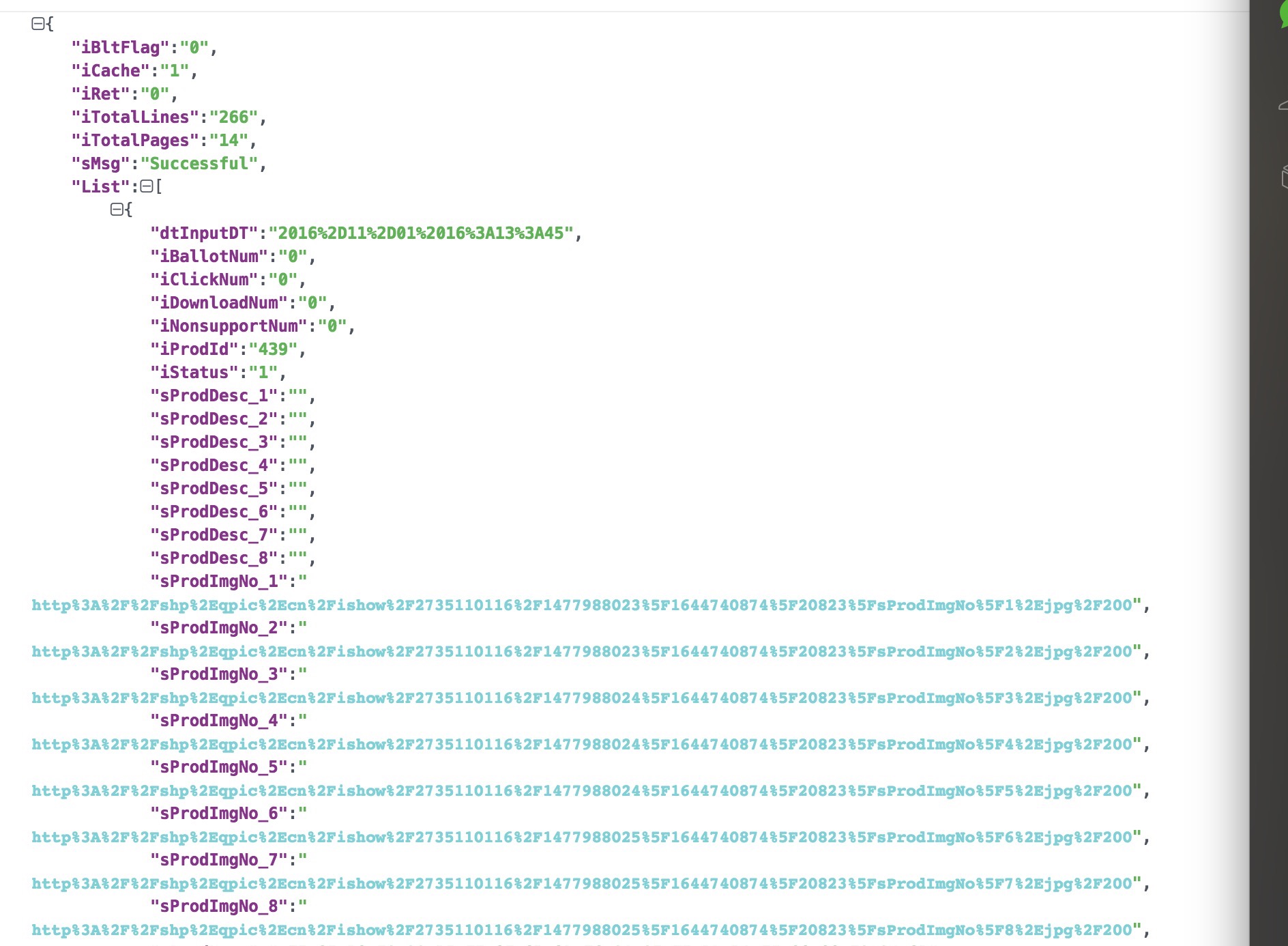
查看json 对象内容必备: https://www.json.cn/ 可以看到清晰的对象属性
很明显的,List 属性就是我们想要获取的壁纸对象了,然后,其中 sProdImgNo_1,2,3,4,5,6,7,8 中保存了,url 编码的图片url地址。
本实例为了演示我们只获取其中的 sProdImgNo_5 来做下载,大家可以根据需求做不同的遍历.
写一个简单的对象循环完成我们的子任务吧:
for item in pageJson['List']:
dealWithItem(item)
- 处理元素函数 , 下载文件图片:
观察发现图片url 是url编码好的地址: 我们可以用 urllib 的 unquote 方法转成原文:
获取的一个图片URL原文是这样的:

自行对比下,观测到的图片的真实地址如下:
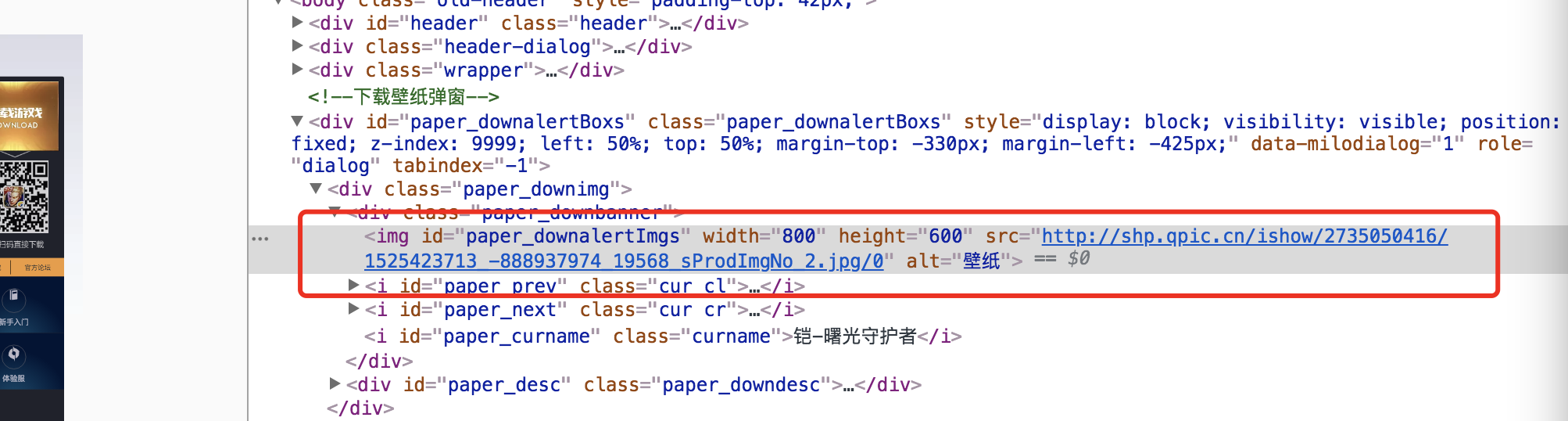
然后,我们只需要简单的把 200 replace 成0 就ok 了。
下载文件,直接通过requests get url 保存成文件就ok啦。
三、运行效果
- 最终展示下我们的成果吧:

四、项目文件结构

python 爬取王者荣耀高清壁纸
注:本文著作权归作者,由demo大师代发,拒绝转载,转载需要作者授权
python 爬取王者荣耀高清壁纸的更多相关文章
- Python 爬取 "王者荣耀.英雄壁纸" 过程中的矛和盾
1. 前言 学习爬虫,最好的方式就是自己编写爬虫程序. 爬取目标网站上的数据,理论上讲是简单的,无非就是分析页面中的资源链接.然后下载.最后保存. 但是在实施过程却会遇到一些阻碍. 很多网站为了阻止爬 ...
- Python爬取 | 王者荣耀英雄皮肤海报
这里只展示代码,具体介绍请点击下方链接. Python爬取 | 王者荣耀英雄皮肤海报 import requests import re import os import time import wi ...
- python 爬取王者荣耀英雄皮肤代码
import os, time, requests, json, re, sys from retrying import retry from urllib import parse "& ...
- 利用python爬取王者荣耀英雄皮肤图片
前两天看到同学用python爬下来LOL的皮肤图片,感觉挺有趣的,我也想试试,于是决定来爬一爬王者荣耀的英雄和皮肤图片. 首先,我们找到王者的官网http://pvp.qq.com/web201605 ...
- python爬取王者荣耀全英雄皮肤
import os import requests url = 'https://pvp.qq.com/web201605/js/herolist.json' herolist = requests. ...
- 20行Python代码爬取王者荣耀全英雄皮肤
引言王者荣耀大家都玩过吧,没玩过的也应该听说过,作为时下最火的手机MOBA游戏,咳咳,好像跑题了.我们今天的重点是爬取王者荣耀所有英雄的所有皮肤,而且仅仅使用20行Python代码即可完成. 准备工作 ...
- python爬虫---爬取王者荣耀全部皮肤图片
代码: import requests json_headers = { "User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win ...
- 手把手教大家如何用scrapy爬虫框架爬取王者荣耀官网英雄资料
之前被两个关系很好的朋友拉入了王者荣耀的大坑,奈何技术太差,就想着做一个英雄的随查手册,这样就可以边打边查了.菜归菜,至少得说明咱打王者的态度是没得说的,对吧?大神不喜勿喷!!!感谢!!废话不多说,开 ...
- Python爬虫-爬取科比职业生涯高清图集
前面学习了Python爬取豆瓣电影Top250的数据,爬取的信息是电影信息的文本信息,但是在互联网上流行的图片才有更大的吸引力,本篇我们来使用python爬取网页上的图片并保存在本地硬盘上,很兴奋吧, ...
随机推荐
- vi相关内容
vi显示行号: 第一种是,手动显示:在vim命令行模式下输入 :set nu 取消显示:在vim命令行模式下输入: set nonu 第二种是,永久自动显示:我们修改一个配置文件. 我们输入命令:vi ...
- mongodb复制集搭建
注:mongodb当前版本是3.4.3 1.准备三个虚拟机做服务器 192.168.168.129:27017 192.168.168.130:27017 192.168.168.131:27017 ...
- (11)python 模块和包
一.导入模块和包 模块相当于一个.py文件,包相当于带有个__init__.py一个文件夹,既可按模块导入也可按包导入. 1.导入模块或包 import 包名或模块名 (as 别名),包名或模块名 ( ...
- luogu P1802 5倍经验日
题目背景 现在乐斗有活动了!每打一个人可以获得5倍经验!absi2011却无奈的看着那一些比他等级高的好友,想着能否把他们干掉.干掉能拿不少经验的. 题目描述 现在absi2011拿出了x个迷你装药物 ...
- luogu P1215 [USACO1.4]母亲的牛奶 Mother's Milk
题目描述 农民约翰有三个容量分别是A,B,C升的桶,A,B,C分别是三个从1到20的整数, 最初,A和B桶都是空的,而C桶是装满牛奶的.有时,农民把牛奶从一个桶倒到另一个桶中,直到被灌桶装满或原桶空了 ...
- [HDU6268]Master of Subgraph
[HDU6268]Master of Subgraph 题目大意: 一棵\(n(n\le3000)\)个结点的树,每个结点的权值为\(w_i\).给定\(m(m\le10^5)\),对于任意\(i\i ...
- [CF911D]Inversion Counting
题目大意: 给你一个数列,翻转其中一个区间,问每次翻转过后逆序对个数的奇偶性. 思路: 首先树状数组求出一开始的奇偶性,然后考虑每次翻转对答案的贡献. 对于整个区间,我们可以把翻转转化成若干次交换. ...
- python3中的range函数
奇怪的现象 在paython3中 print(range(10)) 得出的结果是 range(0,10) ,而不是[0,1,2,3,4,5,6,7,8,9] ,为什么呢? 官网原话: In many ...
- Git学习笔记(二) 远程仓库及分支
添加远程仓库(以GitHub为例) 所谓的远程仓库,其实就和本地仓库一样,只是我们本地电脑可能会关机什么的.远程仓库的目的就是保证7*24小时开启状态.GitHub是一个很好的公共Git远程仓库(后面 ...
- WCF服务测试工具
官网地址:http://www.wcfstorm.com/wcf/home.aspx WCFStorm Lite 来进行接口查看及调试,如下所示.