常见的各类LLM基座模型(GPT、DeepSeek、Qwen等)模型解析以及对比
From: https://www.big-yellow-j.top/posts/2025/02/15/LLM.html
各类LLM模型技术汇总
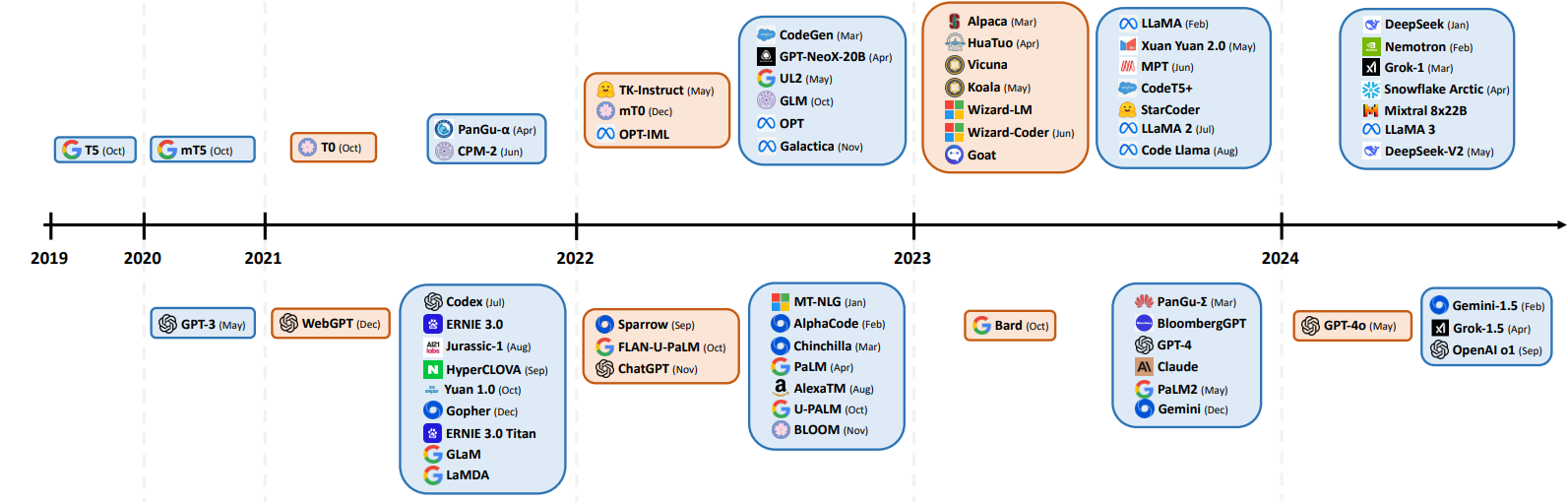
只去对比整体框架,对所采用的激活函数,归一化处理,位置编码等参考:
1、位置编码:https://www.big-yellow-j.top/posts/2025/02/03/pos-embedding.html
2、归一化处理:https://www.big-yellow-j.top/posts/2025/01/05/dl-norm.html
3、分布式训练:https://www.big-yellow-j.top/posts/2025/01/03/DistributeTraining.html
GPT系列
1.GPT v1
对于大部分的深度学习任务,需要大量的标记数据(labeled data),但是如果使用大量的标记数据就会导致一个问题:构建得到的模型缺少适用性(可以理解为模型的泛化性能可能不佳)。那么就尝试使用非标记的数据(unlabelled data)但是这样一来又会有一个新的问题:时间消费大(time-consuming and expensive)。所以目前学者提出:使用预训练的词嵌入来提高任务性能。使用 未标注的文本信息(word-level information from unlabelled text)可能会:1、不清楚那种优化目标(optimization objective)在学习对迁移有用的文本表示时最有效;2、如何将这些学习到的表征有效的迁移到目标任务(target task)中。
作者提出:1、无监督的预训练(unsupervised pre-training);2、监督的微调(supervised fine-tuning)
1、Unsupervised pre-training
给定一些列的的无标签的 token:\(U={u_1,...,u_n}\),构建自回归的模型:
\]
其中 \(\theta\)为模型的参数。作者在模型中使用 Transforme作为 decoder,在最后的模型上作者构建得到为:
h_l = transformer\_block(h_{l-1})\forall i \in [1,n]\\
P(u)=softmax(h_nW_e^T)
\]
其中\(n\)代表神经网路层的数目,\(W_e\)代表 token embedding matrix,\(W_p\)代表 position embedding matrix。对于无监督下的预训练:通过构建的数据集,去对模型的参数进行训练,得到模型的参数。
2、Supervised fine-tunning
作者在此部分提到:通过第一步得到的模型参数去对监督任务进行训练(采用的模型结构是没有变化的)。给定标签数据集\(C\),给定输入:\({x^1,...,x^m }\)以及其标签\(y\)。将数据投入到预训练得到的模型参数里面得到:\(h_l^m\),然后添加一个线性输出层(参数为:\(W_y\))去对\(y\)进行预测。
\]
对于上述两部分步骤直观上理解:人首先从外界获取大量信息:网络,书本等,把这些信息了解之后,然后去写作文或者去回答问题。
模型结构:

2.GPT v2
GPT v2区别前一个模型,区别在于将layer-norm 位置替换到每一个残差连接块的里面,也就是说在数据输入到 Multi-Head-Attention 以及 Feed-Forward 之前提前通过一层标准化处理。
3.GPT v3
DeepSeek系列
主要介绍DeepSeek v3(简称DS)各类技术细节,对于DS在模型结构上和之前迭代版本的 DS-2无太大区别,还是使用混合专家模型,只是补充一个辅助损失去平衡不同专家之间的不均衡问题。
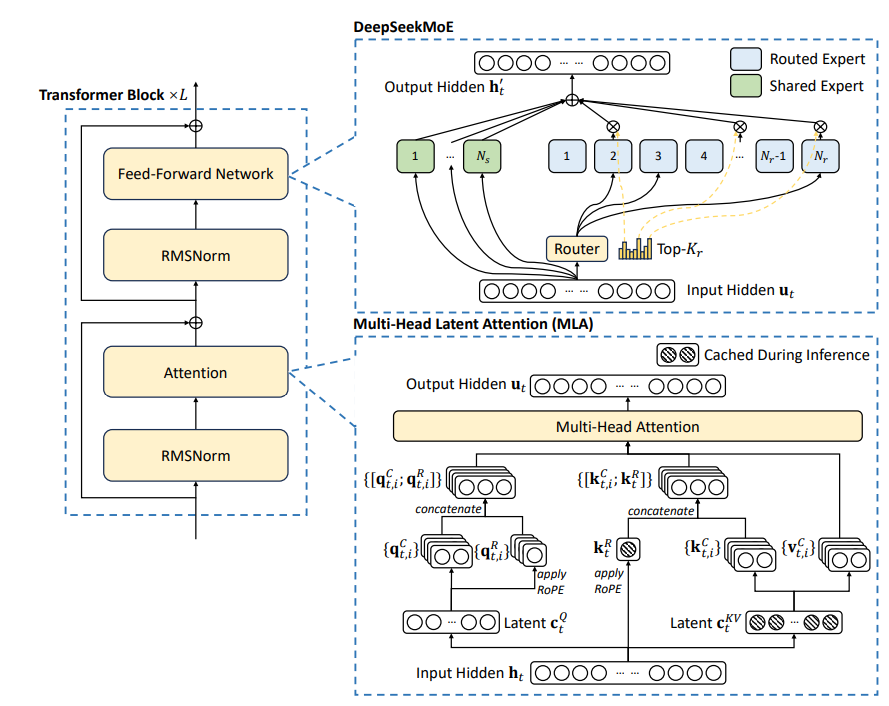
左侧结构和 GPT-2结构类似
在结构上DS主要的创新点在于:1、Multi-Head Latent Attention;2、DeepSeekMoE。前者为优化 KV-cache 操作,通过一个低秩的\(c_r^{KV}\)代替原本占用较高的QV的值(首先通过降维方式降低原本维度,这样一来在显存占用上就会降低,而后通过升维方式,恢复到原本的维度),后者为混合专家模型,不过区别于常用的MoE方法,在DS中将专家模型分为两类:1、Routed Expert;2、Shared Expert,前者直接将隐藏层的输入进行传入,后者则是通过门控网络筛选而后隐藏层的输入进行传入。
除此之外,在DS中使用Multi-Token Prediction(MTP:https://arxiv.org/pdf/2404.19737)技术

在DS中一个很耀眼的功能就是:DeepSeek-R1(一种思维链技术:CoT:Chain of Thought,在GPT-o1中也使用到这种技术)结合论文:https://arxiv.org/pdf/2201.11903;https://arxiv.org/pdf/2501.12948;中对 CoT技术的描述,可以简单的理解为:让LLM可以自主去思考问题,比如在论文中对 CoT技术的描述。
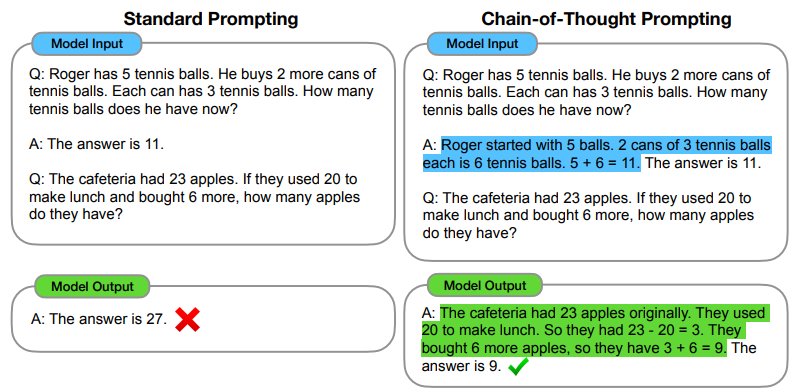
相较之直接让GPT输出答案,区别在于还要他给出推理过程。结合在 DS-R1中的描述对于 DS-R1整体过程理解如下:
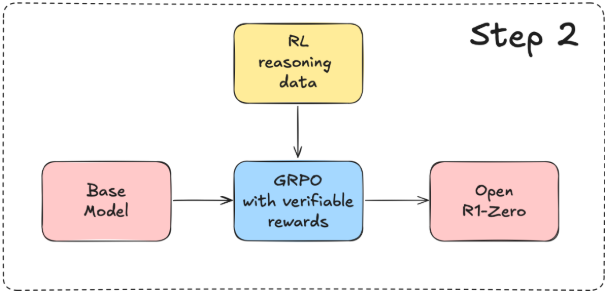
非常明显的一个强化学习过程,在论文里面提到的使用 Group Relative Policy Optimization(GRPO)策略进行优化

在 DS-R1中作者提到的使用的模板

对于上述优化过程理解:比如说对于一个数学问题:\(8+5=?\),这就是上面公式中所提到的question \(q\),按照上面的描述,将会生成一系列的输出:\({o_1,...,o_G}\)
Step-1:生成若干的回答。\({o_1,...,o_G}\)
Step-2:对于生成的回答进行评分。\({r_1,...,r_G}\),而后计算\(A_i=\frac{r_i- \text{mean}({r_1,...,r_G})}{\text{std}({r_,...,r_G})}\)
Step-3:使用裁剪更新策略:\(\text{clip}(\frac{\pi_{\theta}(o_i|q)}{\pi_{\theta_{old}(o_i|q)}},1-\epsilon,\epsilon)\)比如说:如果新策略开始给o1分配过高的概率,裁剪机制确保不会过度强调这个响应。这种方式保证了即使在像推理这样复杂的任务中,策略优化也能保持稳定和可靠。通过clip函数将内部值限定在\((1-\epsilon, 1+\epsilon)\)之间
Step-4:通过KL散度(用来度量两个概率分布相似度的指标)惩罚偏差
PPO和 GRPO
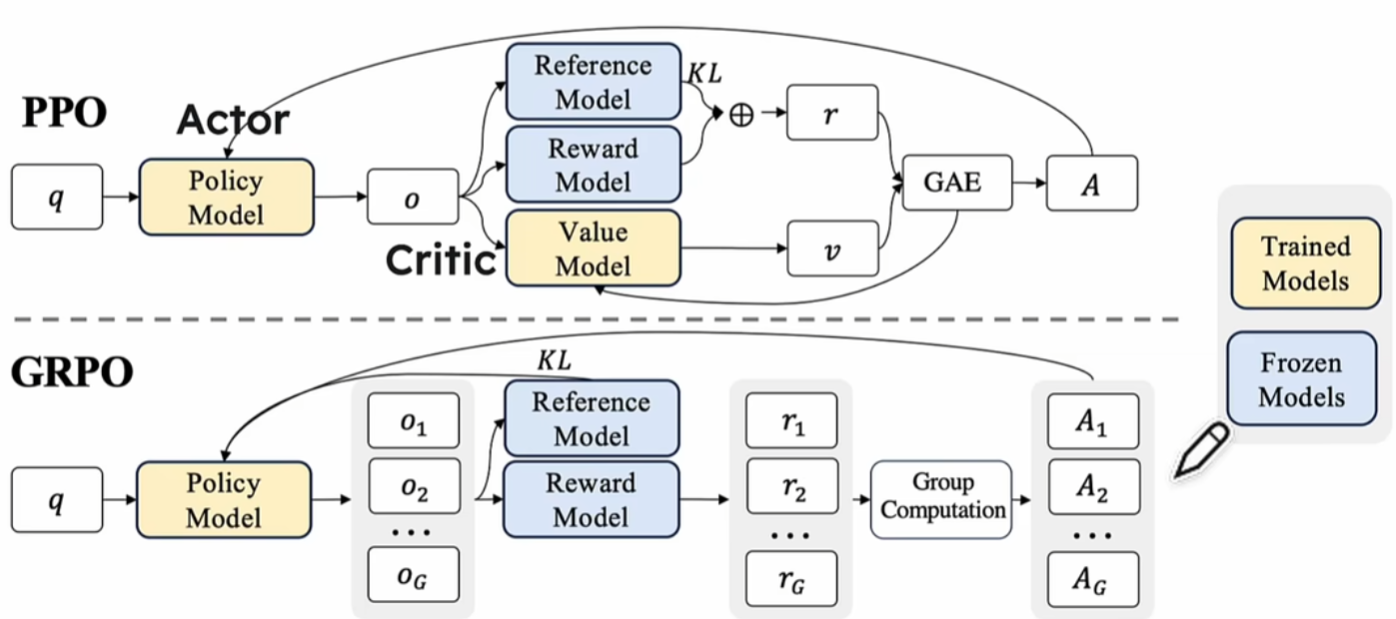
上面提到的几个模型:
1、Policy Model:我们需要优化的模型
2、Value Model:估计状态的价值,帮助指导策略优化
3、Reference Model:提供历史策略的参考,确保优化过程中策略变化不过度
4、Reward Model:定义奖励信号,用于强化学习中的奖励反馈
GRPO实现,参考腾讯以及 Github上实现代码,对于复现可以直接用Huggingface中的 trl来进行复现
LLama系列
1.LLama v1
LLaMA 所采用的 Transformer 结构和细节,与标准的 Transformer 架构不同的地方包括采用了前置层归一化(Pre-normalization)并使用 RMSNorm 归一化函数 (Normalizing Function)、激活函数更换为 SwiGLU,并使用了旋转位置嵌入(RoP),整体 Transformer 架构与 GPT-2 类似
2.LLama v2
区别于上一代的LLama v1改进如下几点(主要参考论文中的A.2.1中的描述):
1、序列长度:由原来的2048 tokens变化为4096 tokens
2、使用GQA:通过使用KV-cache可以加快模型生成速度,但是也会造成过大的显存占用,因此LLama v2使用GQA来减少这个过程中的显存占用。
GQA原理:https://www.big-yellow-j.top/posts/2025/01/29/Attention.html
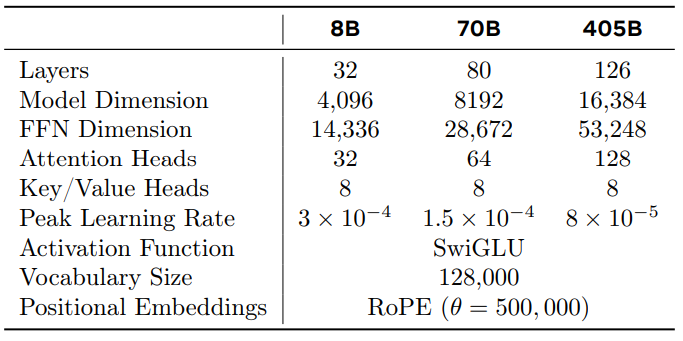
3.LLama v3
模型参数细节:
BERT
预训练阶段任务:
1、Masked LM(MLM)
MLM是一种预训练任务,通过随机掩蔽输入序列中的部分词元,模型根据上下文预测被掩蔽的词元,从而学习双向语言表示。在模型中作者按照:80:10:10的比例进行处理(80:将词元替换为[MASK];10:将词元替换为词汇表中随机选取的其他词。;10:保持原词元不变)
例子:
输入:“今天天气真好,我打算去[MASK]。”
模型的任务是根据上下文预测“[MASK]”应该是“公园”。
2、Next Sentence Prediction(NSP)
NSP是一种预训练任务,模型接收两个句子并预测第二个句子是否是第一个句子的后续。该任务帮助模型理解句子间的逻辑关系。
例子:
句子对:
句子1:“我喜欢去公园散步。”
句子2:“今天下午我会去跑步。”
模型的任务是判断第二个句子是否是第一个句子的自然延续,答案是“是”。
- 缺点
1、BERT neglects dependency between the masked positions and suffers from a pretrain-finetune discrepancy(忽略了屏蔽位置之间的依赖性,并遭受预训练微调差异的影响)
这是因为在 BERT模型中,在预训练阶段会添加 [MASK],但是在 下游任务(downsteram tasks)中并不会使用 [MASK]
HuggingFace-trl使用
参考:
1、https://blog.csdn.net/qq_38961840/article/details/145387854
2、https://huggingface.co/docs/trl/main/en/grpo_trainer
3、https://mp.weixin.qq.com/s/BYPKP5oXg1V4C_vg0VFGhw
参考
1、A Comprehensive Overview of Large Language Models
2、LLaMA: Open and Efficient Foundation Language Models
3、BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding
4、Llama 2: Open Foundation and Fine-Tuned Chat Models
5、The Llama 3 Herd of Models
6、Language Models are Unsupervised Multitask Learners
7、Better & Faster Large Language Models via Multi-token Prediction
8、DeepSeek-R1: Incentivizing Reasoning Capability in LLMs via Reinforcement Learning
11、Chain-of-Thought Prompting Elicits Reasoning in Large Language Models
12、The Math Behind DeepSeek: A Deep Dive into Group Relative Policy Optimization (GRPO)
13、https://www.youtube.com/watch?v=Yi1UCrAsf4o
14、Exploring the Limits of Transfer Learning with a Unified Text-to-Text Transformer
15、https://gist.github.com/willccbb/4676755236bb08cab5f4e54a0475d6fb
16、https://mp.weixin.qq.com/s/BYPKP5oXg1V4C_vg0VFGhw
17、https://huggingface.co/docs/trl/main/en/grpo_trainer
常见的各类LLM基座模型(GPT、DeepSeek、Qwen等)模型解析以及对比的更多相关文章
- 推荐系统[二]:召回算法超详细讲解[召回模型演化过程、召回模型主流常见算法(DeepMF_TDM_Airbnb Embedding_Item2vec等)、召回路径简介、多路召回融合]
1.前言:召回排序流程策略算法简介 推荐可分为以下四个流程,分别是召回.粗排.精排以及重排: 召回是源头,在某种意义上决定着整个推荐的天花板: 粗排是初筛,一般不会上复杂模型: 精排是整个推荐环节的重 ...
- java内存模型7-处理器内存模型
处理器内存模型 顺序一致性内存模型是一个理论参考模型,JMM和处理器内存模型在设计时通常会把顺序一致性内存模型作为参照.JMM和处理器内存模型在设计时会对顺序一致性模型做一些放松,因为如果完全按照顺序 ...
- TCP/IP四层协议模型与ISO七层模型
TCP/IP四层协议模型与ISO七层模型 在世界上各地,各种各样的电脑运行着各自不同的操作系统为大家服务,这些电脑在表达同一种信息的时候所使用的方法是千差万别.就好像圣经中上帝打乱了各地人的口音,让他 ...
- [并发并行]_[线程模型]_[Pthread线程使用模型之一管道Pipeline]
场景 1.经常在Windows, MacOSX 开发C多线程程序的时候, 经常需要和线程打交道, 如果开发人员的数量不多时, 同时掌握Win32和pthread线程 并不是容易的事情, 而且使用Win ...
- 001-OSI七层模型,TCP/IP五层模型
一.概述 OSI(Open System Interconnection)参考模型是国际标准化组织(ISO)制定的一个用于计算机或通信系统间互联的标准体系,一般称为OSI参考模型或七层模型. OSI/ ...
- 【ASE模型组】Hint::neural 模型与case study
模型 基于搜索的提示系统 我们的系统用Pycee针对语法错误给出提示.然而,对于语法正确.结果错误的代码,我们需要另外的解决方式.因此,我们维护一些 (错误代码, 相应提示) 的数据,该数据可以由我们 ...
- 网络基础:OSI 七层模型、TCP/IP 四层模型
1.Internet历史 1. 1968年由美国ARPA机构提出"资源共享计算机网络”,让ARPA的计算机互联起来,叫做阿帕网;2. 1974年,第一个TCP协议详细说明发布了.3. 一个 ...
- OSI七层模型与TCP/IP五层模型-(转自钛白Logic)
OSI七层模型与TCP/IP五层模型 博主是搞是个FPGA的,一直没有真正的研究过以太网相关的技术,现在终于能静下心学习一下,希望自己能更深入的掌握这项最基本的通信接口技术.下面就开始 ...
- OSI七层模型及TCP/IP四层模型
1) OSI七层模型及TCP/IP四层模型 OSI七层模型:是国际标准化组织(ISO)制定的一个用于计算机或通信系统间互联的标准体系.它是一个七层的.抽象的模型,不仅包括一系列抽象的术语或概念,也包 ...
- 树状结构Java模型、层级关系Java模型、上下级关系Java模型与html页面展示
树状结构Java模型.层级关系Java模型.上下级关系Java模型与html页面展示 一.业务原型:公司的组织结构.传销关系网 二.数据库模型 很简单,创建 id 与 pid 关系即可.(pid:pa ...
随机推荐
- Electron 通信
1.web向主进程发送消息 (单项) 使用ipcMain.on 监听事件 const hanle = (event, data) => { console.log(event) console. ...
- R数据分析:净重新分类(NRI)和综合判别改善(IDI)指数的理解
对于分类预测模型的表现评估我们最常见的指标就是ROC曲线,报告AUC.比如有两个模型,我们去比较下两个模型AUC的大小,进而得出两个模型表现的优劣.这个是我们常规的做法,如果我们的研究关注点放在&qu ...
- .NET Threadpool 饥渴,以及队列是如何使它更糟的
.NET Threadpool 饥渴,以及队列是如何使它更糟的 .NET Threadpool starvation, and how queuing makes it worse - Criteo ...
- 带宽计算-大B和小B的区别
在计算机网络.IDC机房中,其宽带速率的单位用bps(或b/s)表示:换算关系为:1Byte=8bit 1B=8b ---- 1B/s=8b/s(或1Bps=8bps) 1KB=1024B ...
- MAC brew install 跳过 update
相信很多用 MAC 小伙伴的小伙伴都对 HomeBrew 很熟悉. 但是! 都遇到过这样的问题, 每次安装新东西, 它都要先去 update 一下, 那个耗时啊-. 怎么才能不 update, 直接安 ...
- Qt编写安防视频监控系统46-视频存储
一.前言 在整个视频监控系统的开发迭代升级过程中,遇到过各种奇奇怪怪的需求,都是客户提出来的,有些需求很合理,有些就不那么的自然了,牢记这客户是上帝的原则,能满足的尽量满足.相信各位同行的研发人员都会 ...
- Abp vNext 扩展属性
扩展属性 我们发现abp的默认都会有一个ExtraProperties属性,那么他的作用是什么呢?当我们使用abp的时候,需要对其原有的表进行扩展或者添加我们想要的字段,又不想改源码,以最小的方式实现 ...
- linux下查看文件行数和列数
查看行数: wc -l 文件名 查看列数: cat 文件名 | awk '{print NF}' 注意:默认是\t分割 但是可以使用-F参数指定分隔符,例如以 | 进行分割: cat 文件名 | aw ...
- Mac_工具使用汇总
Mac安装低版本的Xcode后会出现各种问题,现汇总如下: 1. python3: error: unable to find utility "python3", not a ...
- 零基础学习Modbus通信协议
大家好!我是付工. 2012年开始接触Modbus协议,至今已经有10多年了,从开始的懵懂,到后来的顿悟,再到现在的开悟,它始终岿然不动,变化的是我对它的认知和理解. 今天跟大家聊聊关于Modbus协 ...