『Plotly实战指南』--Plotly与Pandas的深度融合
在数据分析的世界中,数据处理与可视化是密不可分的两个环节。
Pandas作为Python数据处理的核心工具,以其强大的数据清洗、转换和分析能力,成为数据科学家和分析师的必备利器;
而Plotly则是交互式可视化的佼佼者,能够将复杂的数据以直观、动态的方式呈现出来。
当我们将Pandas与Plotly深度融合时,就能无缝衔接数据清洗、分析与可视化的全流程,大幅提升数据分析的效率和效果。
1. 从Pandas数据结构到Plotly图表
1.1. Series 与 DataFrame 数据创建图表
Plotly提供了强大的plotly.express模块,能够直接读取Pandas的数据结构,如Series和DataFrame,并快速生成各种交互式图表。
例如,使用px.line(df)可以将一个时间序列的DataFrame转换为折线图,而px.bar(series)则可以将一个Series转换为条形图。
import pandas as pd
import numpy as np
import plotly.express as px
# 创建一个示例 DataFrame
data = {
"date": pd.date_range(start="2024-01-01", periods=100),
"sales": np.random.randint(100, 500, size=100),
}
df = pd.DataFrame(data)
# 使用 Plotly Express 创建折线图
fig = px.line(df, x="date", y="sales", title="时间序列销售数据")
fig.show()
在这个例子中,x='date'和y='sales'将DataFrame的列名映射到了图表的坐标轴上。
将数据中的某个列(Series)取出来,可以直接绘制条形图。
series = df["sales"]
fig = px.bar(series)
fig.show()
1.2. 索引与绘图的关联
Pandas的索引(如时间戳、分类标签)在绘图中也扮演着重要角色。
我们可以直接将Pandas索引作为图表的坐标轴,从而简化数据处理过程。
比如,如果一个DataFrame的索引是时间戳,那么它默认就成为X轴。
data = {
"date": pd.date_range(start="2024-01-01", periods=100),
"sales": np.random.randint(100, 500, size=100),
}
df = pd.DataFrame(data)
# 将日期设置为索引
df.set_index('date', inplace=True)
# 绘制图表,不需要指定X轴
fig = px.line(df, y='sales', title='以索引为时间轴的销售数据')
fig.show()
对于多级索引(MultiIndex)数据,Plotly也提供了强大的支持。
我们可以利用多级索引来生成分面图(Facet Plot)或动态筛选图表。
# 创建多级索引
df = df.reset_index()
df["region"] = ["North", "South"] * 50
df.set_index(["region", "date"], inplace=True)
# 绘制分面图
fig = px.line(
df.reset_index(),
x="date",
y="sales",
facet_col="region",
title="按地区分面的销售数据",
)
fig.show()
在处理多级索引时,需要注意索引重置与列名转换的问题。
上面的示例中,我们先将date索引转换为普通列,然后把普通列region和date一起转换为多级索引。
2. 数据预处理与可视化的交响曲
2.1. 数据清洗与验证可视化
在实际的数据分析中,数据往往存在缺失值和异常值。
Pandas提供了丰富的数据清洗工具,而Plotly可以将清洗前后的数据可视化出来,让我们更好的把握数据的变化。
首先,生成包含客户年龄(含缺失值和异常值)、销售额(对数正态分布)和区域的模拟数据集。
import pandas as pd
import numpy as np
import plotly.express as px
# 模拟含噪声数据
np.random.seed(42)
dates = pd.date_range('2023-01-01', periods=100)
# Customer_Age 年龄包含异常值(生成平均40,标准差30的数据)
df = pd.DataFrame({
'Date': dates,
'Customer_Age': np.random.normal(40, 30, 100),
})
# 人为添加缺失值
df.loc[np.random.choice(100, 15), 'Customer_Age'] = np.nan
故意添加15%的年龄缺失值,并设置年龄范围异常(生成年龄的部分中有异常的年龄)。
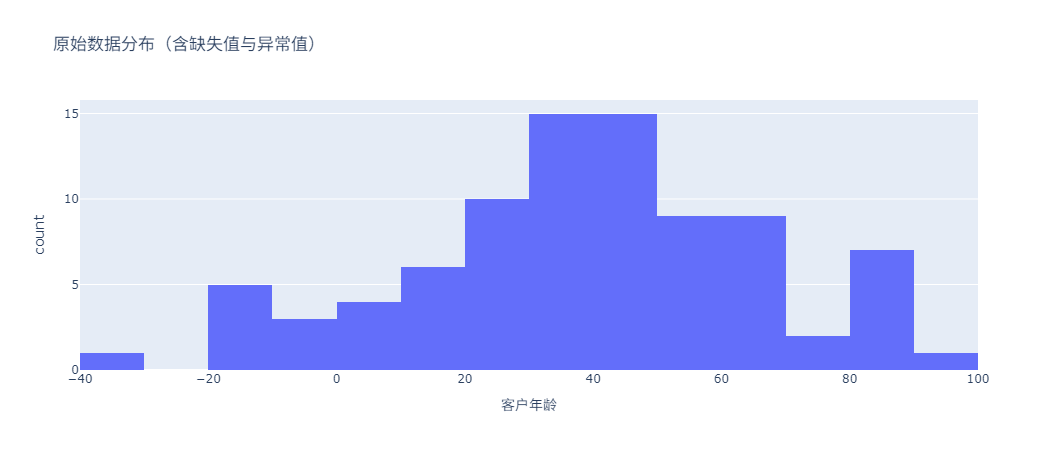
然后,绘制原始数据的分布图:
# 原始数据分布
raw_hist = px.histogram(
df,
x='Customer_Age',
title='原始数据分布(含缺失值与异常值)',
labels={'Customer_Age': '客户年龄'},
nbins=20
)
raw_hist.show()
接下来,开始清洗数据:
dropna():删除年龄缺失的行query():过滤年龄异常值(保留18-65岁)
# 清洗数据
clean_df = (
df
.dropna(subset=['Customer_Age']) # 删除缺失值
.query('18 <= Customer_Age <= 65') # 过滤异常值
)
清洗之后再次绘制分布图:
# 清洗后分布
clean_hist = px.histogram(
clean_df,
x='Customer_Age',
title='清洗后数据分布',
labels={'Customer_Age': '客户年龄'},
nbins=20,
color_discrete_sequence=['#2ca02c']
)
clean_hist.show()
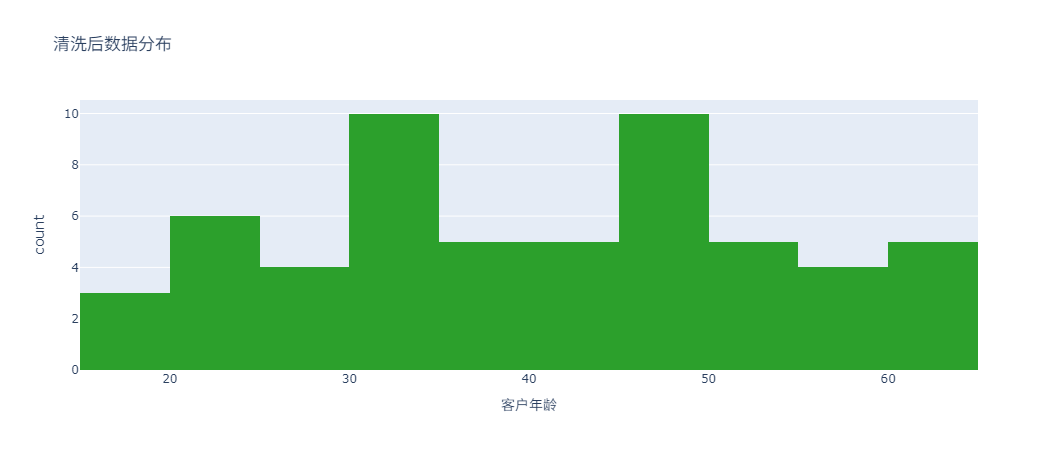
通过这种方式,我们可以直观地看到数据清洗的效果,从而更好地评估数据的质量。
2.2. 数据聚合与高级可视化
Pandas的groupby()和pivot_table()是数据聚合的强大工具。
我们可以利用Pandas进行数据重塑,然后用Plotly来绘制重塑之后数据的高级可视化,甚至是通过自定义动画控制按钮增强交互体验。
下面的示例中,我们先生成一些销售示例数据:
# 模拟数据
np.random.seed(42)
dates = pd.date_range('2023-01-01', periods=100)
df = pd.DataFrame({
'Date': dates,
'Sales': np.random.lognormal(3, 0.5, 100),
'Region': np.random.choice(['北部', '南部', '东部', '西部'], 100)
})
# 对销售额进行对数转换(解决右偏分布)
df["Sales"] = np.log(df["Sales"])
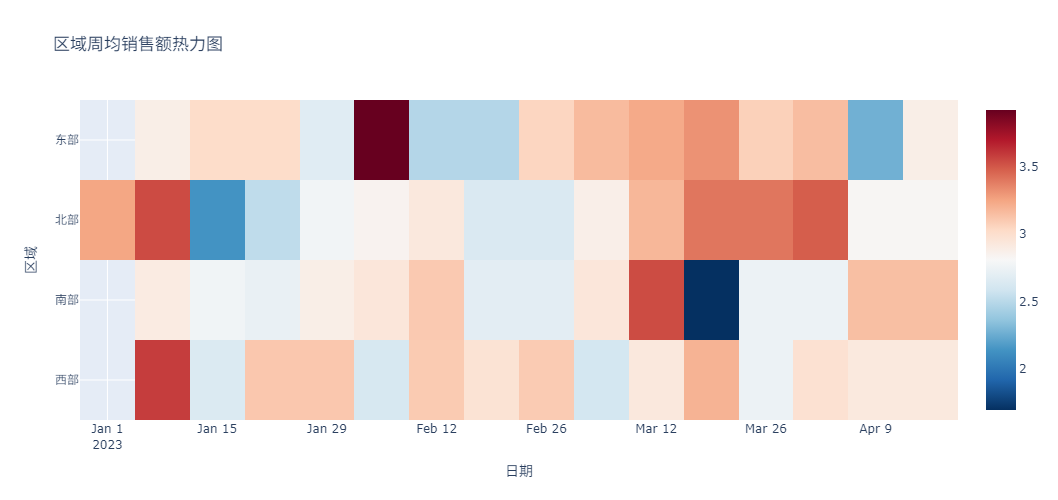
然后,生成透视数据并绘制热力图。
# 生成透视数据
pivot_df = df.pivot_table(
index=pd.Grouper(key='Date', freq='W'), # 按周聚合
columns='Region',
values='Sales',
aggfunc='mean'
).ffill() # 前向填充缺失值
# 热力图
heatmap = px.imshow(
pivot_df.T, # 转置使时间为X轴
x=pivot_df.index.strftime('%Y-%m-%d'),
y=pivot_df.columns,
labels={'x': '日期', 'y': '区域'},
color_continuous_scale='RdBu_r',
title='区域周均销售额热力图'
)
heatmap.update_layout(height=500)
heatmap.show()
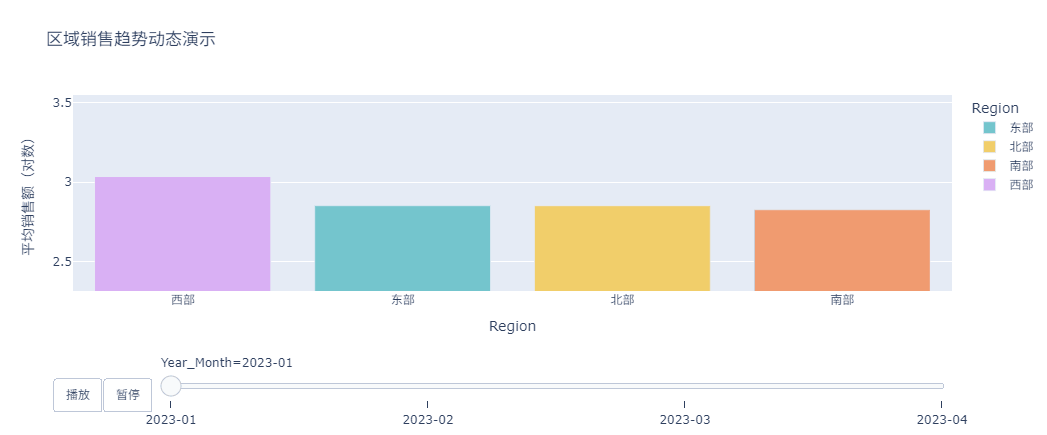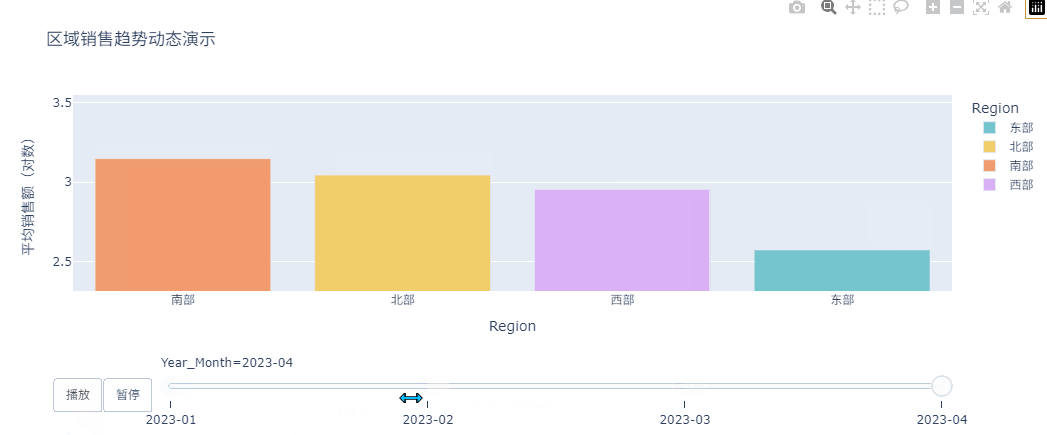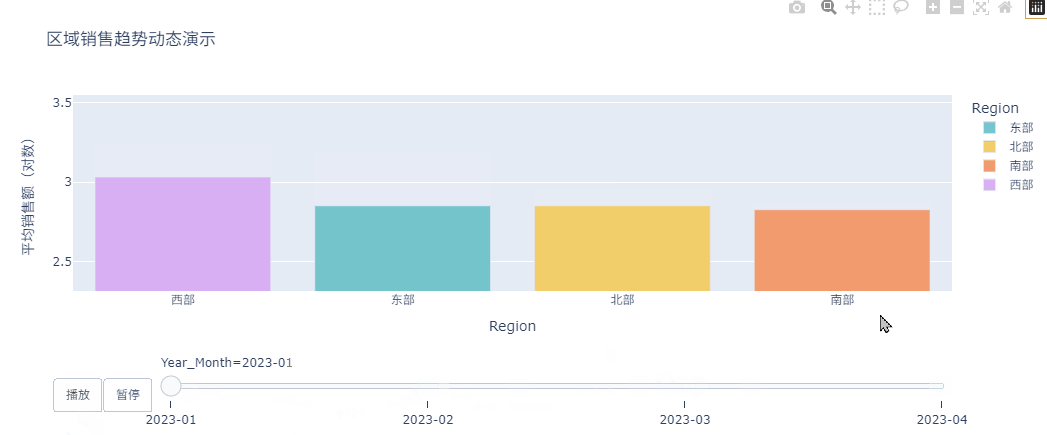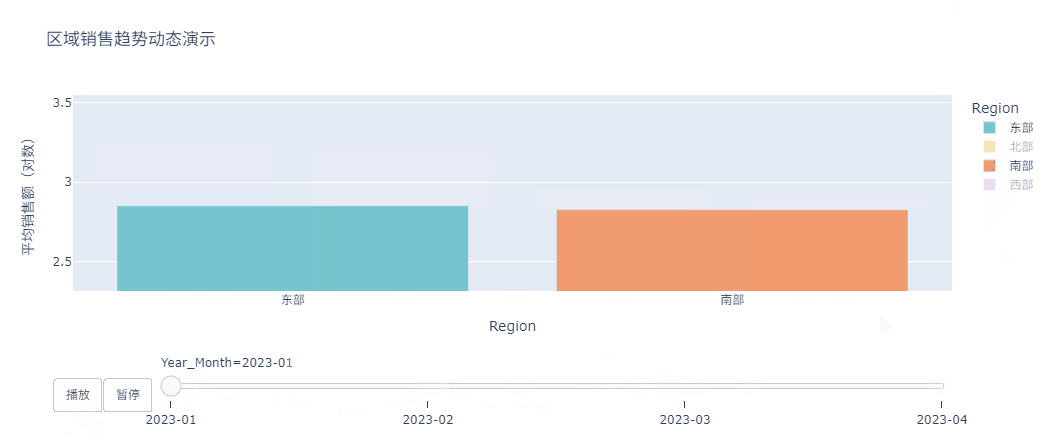
最后,按照月份聚合数据,并生成动态分层柱状图,看各个区域随着时间变化销售额是如何变化的。
# 动态分层柱状图
# 生成聚合数据
agg_df = (
df
.assign(Year_Month=lambda x: x['Date'].dt.to_period('M'))
.groupby(['Year_Month', 'Region'], as_index=False)
['Sales'].mean()
.assign(Year_Month=lambda x: x['Year_Month'].dt.to_timestamp())
)
# 创建动画图表
animated_bar = px.bar(
agg_df,
x='Region',
y='Sales',
animation_frame=agg_df['Year_Month'].dt.strftime('%Y-%m'),
range_y=[agg_df['Sales'].min()*0.9, agg_df['Sales'].max()*1.1],
labels={'Sales': '平均销售额(对数)'},
title='区域销售趋势动态演示',
color='Region',
color_discrete_sequence=px.colors.qualitative.Pastel
)
# 优化动画设置
animated_bar.update_layout(
xaxis={'categoryorder': 'total descending'},
hovermode='x unified',
updatemenus=[{
"buttons": [
{
"args": [None, {"frame": {"duration": 500, "redraw": True},
"fromcurrent": True,
"transition": {"duration": 300}}],
"label": "播放",
"method": "animate"
},
{
"args": [[None], {"frame": {"duration": 0, "redraw": True},
"mode": "immediate",
"transition": {"duration": 0}}],
"label": "暂停",
"method": "animate"
}
],
"direction": "left",
"pad": {"r": 10, "t": 87},
"showactive": False,
"type": "buttons",
"x": 0.1,
"xanchor": "right",
"y": 0,
"yanchor": "top"
}]
)
animated_bar.show()
3. 总结
Plotly与Pandas的深度融合为数据分析提供了一个强大的工具链。
从脏数据到洞察力,Pandas 负责数据的清洗和预处理,而 Plotly 则负责将处理后的数据以直观、动态的方式呈现出来。
这种协同工作模式不仅提升了数据分析的效率,还帮助我们更好地理解数据背后的含义。
在实际应用中,数据处理与可视化的不可分割性至关重要。
高质量的图表依赖于高质量的数据,而 Plotly 与 Pandas 的结合正是实现这一目标的最佳选择。
『Plotly实战指南』--Plotly与Pandas的深度融合的更多相关文章
- 『Numpy学习指南』Matplotlib绘图
数据生成: import numpy as np import matplotlib.pyplot as plt func = np.poly1d(np.array([,,,])) func1 = f ...
- 『Numpy学习指南』排序&索引&抽取函数介绍
排序: numpy.lexsort(): numpy.lexsort()是个排字典序函数,因为很有意思,感觉也蛮有用的,所以单独列出来讲一下: 强调一点,本函数只接受一个参数! import nump ...
- 【阿里云产品公测】以开发者角度看ACE服务『ACE应用构建指南』
作者:阿里云用户mr_wid ,z)NKt# @I6A9do 如果感觉该评测对您有所帮助, 欢迎投票给本文: UO<claV RsfTUb)< 投票标题: 28.[阿里云 ...
- 2017-2018-2 20155303『网络对抗技术』Exp6:信息收集与漏洞扫描
2017-2018-2 20155303『网络对抗技术』 Exp6:信息收集与漏洞扫描 --------CONTENTS-------- 一.原理与实践说明 1.实践内容 2.基础问题 二.实践过程记 ...
- 2018-2019-2 20165316 『网络对抗技术』Exp3:免杀原理与实践
2018-2019-2 20165316 『网络对抗技术』Exp3:免杀原理与实践 一 免杀原理与实践说明 (一).实验说明 任务一:正确使用msf编码器,msfvenom生成如jar之类的其他文件, ...
- 2017-2018-2 20155303『网络对抗技术』Final:Web渗透获取WebShell权限
2017-2018-2 『网络对抗技术』Final:Web渗透获取WebShell权限 --------CONTENTS-------- 一.Webshell原理 1.什么是WebShell 2.We ...
- 2017-2018-2 20155303 『网络对抗技术』Exp3:免杀原理与实践
2017-2018-2 20155303 『网络对抗技术』Exp3:免杀原理与实践 --------CONTENTS-------- 1. 免杀原理与实践说明 实验说明 基础问题回答 2. 使用msf ...
- 『力荐汇总』这些 VS Code 快捷键太好用,忍不住录了这34张gif动图
之前写过三篇文章,收获了极其不错的阅读量与转发量: 你真的会用 VS Code 的 Ctrl.Shift和Alt吗?高效易用的快捷键:多光标.跳转引用等轻松搞定 VS Code 中的 Vim 操作 | ...
- 大数据存储:MongoDB实战指南——常见问题解答
锁粒度与并发性能怎么样? 数据库的读写并发性能与锁的粒度息息相关,不管是读操作还是写操作开始运行时,都会请求相应的锁资源,如果请求不到,操作就会被阻塞.读操作请求的是读锁,能够与其它读操作共享,但是当 ...
- js实现『加载更多』功能实例
DEMO : 滚动加载示例 关于如何实现『加载更多』功能,网上有插件可用,例如比较著名的使用iscroll.js实现的上拉加载更多.下拉刷新功能. 但实际用起来却是很麻烦.由于是第三方插件,要按照对方 ...
随机推荐
- 微信分享前端开发全程详解含iOS、安卓、H5、ReactNative以及微信开放标签的适配和使用
2024年9月,本人在做微信分享前端部分的iOS.安卓和H5的页面和功能时踩了不少坑,于是写了这篇文章,内容包括微信分享在上面三个端的技术点和坑点.解决办法,微信开放标签的相关适配,以及ReactNa ...
- linux的使用(3)
1.tar 包 压缩和解压 (1)tar -cvf 打包 (2)tar -xvf 解压压缩包 图片 (3)tar.gz 打包 案例:tar -zcvf ys.tar.gz aa bb hh tt (4 ...
- ruoyi-vue axios通过接口请求wav、mp3音频二进制数据
实现方式 在axios请求中注明responseType: 'blob',headers的Accept: 'audio/wav'不清楚要不要写,我加上了(请求接口) 在接口返回值中,使用Blob的构造 ...
- vue3项目中环境变量使用技巧
在Vue 3项目中,环境变量是管理不同环境下配置的强大工具.以下是一些关于如何在Vue 3项目中有效地定义.访问和使用环境变量的技巧,以及如何在不同环境下管理这些变量的最佳实践. 一.定义环境变量 在 ...
- FastAPI 表单参数与文件上传完全指南:从基础到高级实战 🚀
title: FastAPI 表单参数与文件上传完全指南:从基础到高级实战 date: 2025/3/8 updated: 2025/3/8 author: cmdragon excerpt: 本教程 ...
- python 二级 基本数据类型
1.思维导图 需要特殊记忆知识点 -1.01E-3值为 0.00101 基本运算一共9个: 取整 a//b 取余数 a%b x的y次幂 :x**y 数值运算函数 format 格式的控制 常用的操作 ...
- 给react native 添加transform translateY动画报错:Transform with key of "translateY" must be a number:{translateY“:0}
初学react native,想实现一个相机扫描功能时,报错,报错描述如标题 这是我的主要逻辑代码 const fadeAnim = useRef(new Animated.Value(0)).cur ...
- Window10永久暂停(禁用)自动更新
终于彻底设置window10不自动更新了(禁用自动更新) 设置成功后的标识 设置成功后,重启电脑再打开就会显示这样的,这个才是禁用成功的标识: 之前安装了window 10 ,但是window 10 ...
- IvorySQL 4.0 之兼容 Oracle 包功能设计思路解读
日前,IvorySQL 4.0 发布,该版本新增了兼容 Oracle 包功能的新特性. 为了大家能够更好地理解和使用 IvorySQL 4.0,本文将简要介绍实现此功能时的设计思路. Oracle 的 ...
- vSphere是什么,你了解么?
最近这两周都在学习VMware vSphere相关知识,昨天在做了一个项目后,VMware虚拟化之旅暂告一段落了.晚上一个人闲下来时回想了之前所学,忆起vSphere时,大脑一片空白... 我突然发现 ...