使用HuggingFace 模型并预测
下载HuggingFace 模型
首先打开网址:https://huggingface.co/models 这个网址是huggingface/transformers支持的所有模型,目前大约一千多个。搜索gpt2(其他的模型类似,比如bert-base-uncased等),并点击进去。
进入之后,可以看到gpt2模型的说明页,点击页面中的list all files in model,可以看到模型的所有文件。
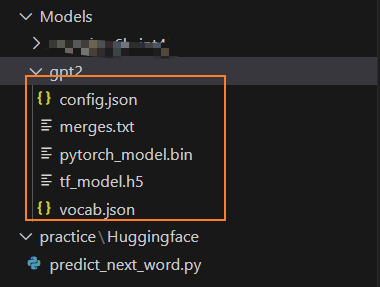
通常需要把保存的是三个文件以及一些额外的文件
- 配置文件 -- config.json
- 词典文件 -- vocab.json
- 预训练模型文件
pytorch -- pytorch_model.bin文件
tensorflow 2 -- tf_model.h5文件
额外的文件,指的是merges.txt、special_tokens_map.json、added_tokens.json、tokenizer_config.json、sentencepiece.bpe.model等,这几类是tokenizer需要使用的文件,如果出现的话,也需要保存下来。没有的话,就不必在意。如果不确定哪些需要下,哪些不需要的话,可以把图1中类似的文件全部下载下来。
看下这几个文件都是什么:
config.json配置文件
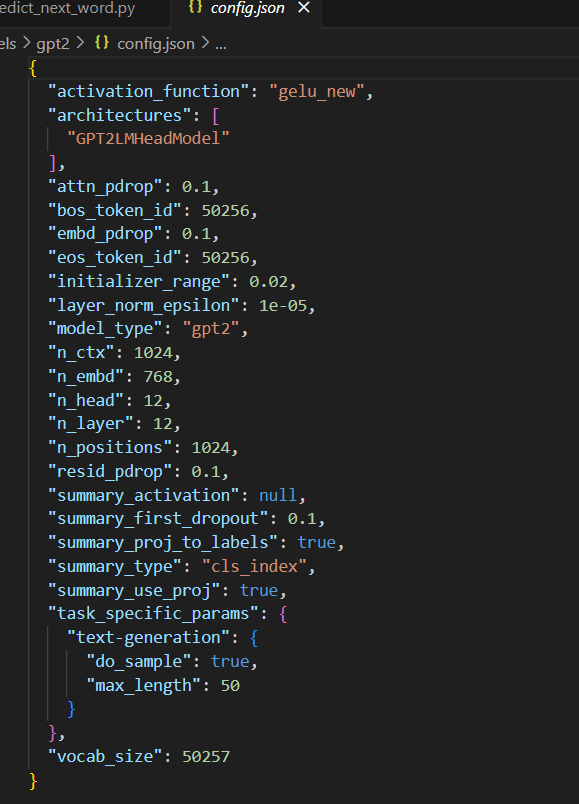
包含了模型的类型、激活函数等配置信息vocab.json 词典文件
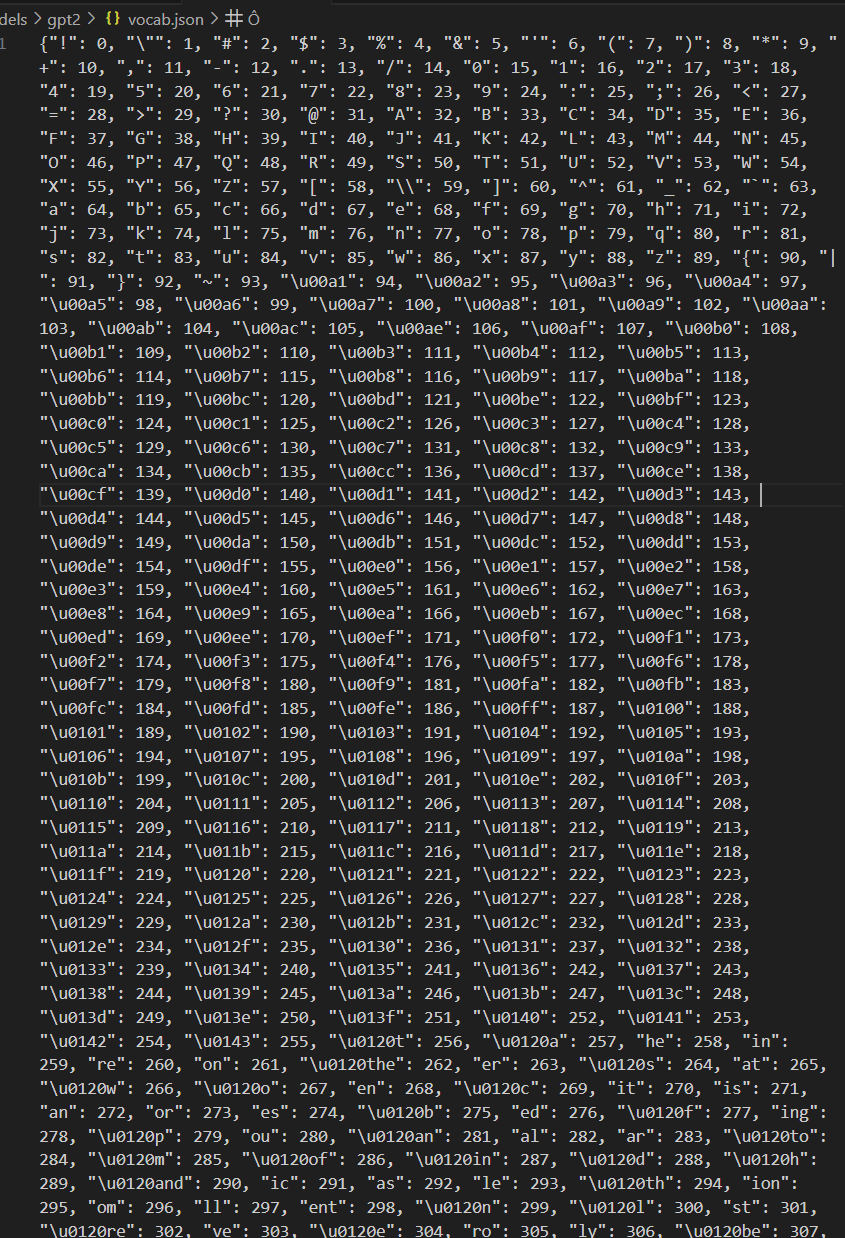
merges.txt
使用HuggingFace模型
将上述下载的模型存储在本地:
加载本地HuggingFace模型
- 导入依赖
import torch
from transformers import GPT2Tokenizer, GPT2LMHeadModel
导入PyTorch框架和HuggingFace Transformers库的GPT-2组件
- 初始化分词器
tokenizer = GPT2Tokenizer.from_pretrained("../../Models/gpt2/")
text = "Who was Jim Henson ? Jim Henson was a"
indexed_tokens = tokenizer.encode(text)
print(indexed_tokens) # [8241, 373, 5395, 367, 19069, 5633]
# 转换为torch Tensor
token_tensor = torch.tensor([indexed_tokens])
print(token_tensor) # tensor([[ 8241, 373, 5395, 367, 19069, 5633]])
tokenizer.encode(text)执行流程如下:
分词器处理:
首先将文本分词为子词(subwords),如:
"Who was Jim Henson ?" → ['Who', 'Ġwas', 'ĠJim', 'ĠHen', 'son', '?']
ID转换:
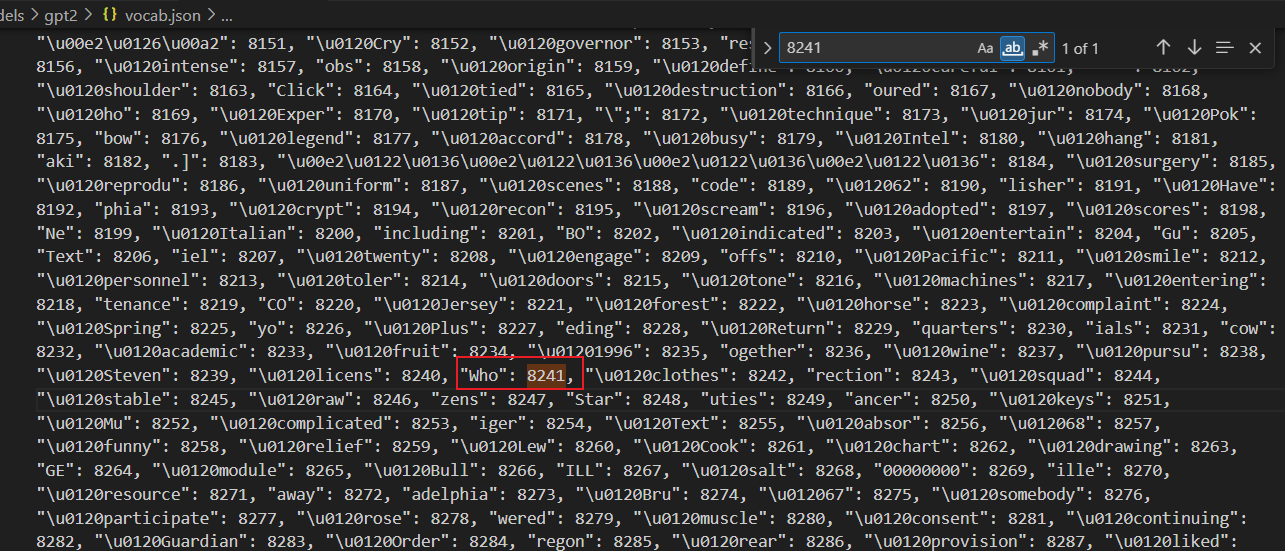
然后将每个子词转换为对应的整数ID(来自vcab.json),如:
['Who', 'Ġwas', 'ĠJim', 'ĠHen', 'son', '?'] -> [8241, 373, 5395, 367, 19069, 5633]
可以查看vcab.json文件:
返回的是 token ID 列表(整数列表),而非词向量
- 加载预训练模型并预测
# 加载预训练模型
model = GPT2LMHeadModel.from_pretrained("../../Models/gpt2/")
# print(model)
model.eval()
with torch.no_grad():
outputs = model(token_tensor)
predictions = outputs[0]
# 我们需要预测下一个单词,所以是使用predictions第一个batch,最后一个词的logits去计算
# predicted_index = 582,通过计算最大得分的索引得到的
predicted_index = torch.argmax(predictions[0, -1, :]).item()
# 反向解码为我们需要的文本
predicted_text = tokenizer.decode(indexed_tokens + [predicted_index])
# 解码后的文本:'Who was Jim Henson? Jim Henson was a man'
# 成功预测出单词 'man'
print(predicted_text)
输出结果:

使用HuggingFace 模型并预测的更多相关文章
- Python之逻辑回归模型来预测
建立一个逻辑回归模型来预测一个学生是否被录取. import numpy as np import pandas as pd import matplotlib.pyplot as plt impor ...
- 迁移学习——使用Tensorflow和VGG16预训模型进行预测
使用Tensorflow和VGG16预训模型进行预测 from:https://zhuanlan.zhihu.com/p/28997549 fast.ai的入门教程中使用了kaggle: dogs ...
- matlab(5) : 求得θ值后用模型来预测 / 计算模型的精度
求得θ值后用模型来预测 / 计算模型的精度 ex2.m部分程序 %% ============== Part 4: Predict and Accuracies ==============% Af ...
- R语言利用ROCR评测模型的预测能力
R语言利用ROCR评测模型的预测能力 说明 受试者工作特征曲线(ROC),这是一种常用的二元分类系统性能展示图形,在曲线上分别标注了不同切点的真正率与假正率.我们通常会基于ROC曲线计算处于曲线下方的 ...
- Keras 构建DNN 对用户名检测判断是否为非法用户名(从数据预处理到模型在线预测)
一. 数据集的准备与预处理 1 . 收集dataset (大量用户名--包含正常用户名与非法用户名) 包含两个txt文件 legal_name.txt ilegal_name.txt. 如下图所 ...
- 用交叉验证改善模型的预测表现-着重k重交叉验证
机器学习技术在应用之前使用“训练+检验”的模式(通常被称作”交叉验证“). 预测模型为何无法保持稳定? 让我们通过以下几幅图来理解这个问题: 此处我们试图找到尺寸(size)和价格(price)的关系 ...
- 学习ML.NET(2): 使用模型进行预测
训练模型 在上一篇文章中,我们已经通过LearningPipeline训练好了一个“鸢尾花瓣预测”模型, var model = pipeline.Train<IrisData, IrisPre ...
- Machine Learning for hackers读书笔记(五)回归模型:预测网页访问量
线性回归函数 model<-lm(Weight~Height,data=?) coef(model):得到回归直线的截距 predict(model):预测 residuals(model):残 ...
- SVM模型进行分类预测时的参数调整技巧
一:如何判断调参范围是否合理 正常来说,当我们参数在合理范围时,模型在训练集和测试集的准确率都比较高:当模型在训练集上准确率比较高,而测试集上的准确率比较低时,模型处于过拟合状态:当模型训练集和测试集 ...
- 深度学习利器:TensorFlow在智能终端中的应用——智能边缘计算,云端生成模型给移动端下载,然后用该模型进行预测
前言 深度学习在图像处理.语音识别.自然语言处理领域的应用取得了巨大成功,但是它通常在功能强大的服务器端进行运算.如果智能手机通过网络远程连接服务器,也可以利用深度学习技术,但这样可能会很慢,而且只有 ...
随机推荐
- STC内部扩展RAM的应用
RAM是用来在程序运行中存放随机变量的数据空间,51单片机默认的内部RAM只有128字节,52单片机增加至256字节,STC89C52增加到512字节,STC89C54.55.58.516等增加到12 ...
- 基于正则化的图自编码器在推荐算法中的应用 Application of graph auto-encoders based on regularization in recommendation algorithms
引言 看过的每一篇文章,都是对自己的提高.不积跬步无以至千里,不积小流无以成江海,积少成多,做更好的自己. 本文基于2023年4月6日发表于SCIPEERJ COMPUTER SCIENCE(PEER ...
- 震惊!Manus邀请码炒到5万元一个!附免费获取Manus邀请码两种方式
在AI技术蓬勃发展的当下,一款名为Manus的产品掀起了行业巨浪.本文将深入剖析这款全球首款通用AI智能体,从它的惊艳亮相.独特功能,到其性能突破.模式限制,以及在AI领域的深远意义,全方位带大家了解 ...
- 【Python】ini解析ERROR:没有实例属性‘__getintem__’
abaqus python 搭配ini 时,出现AttributeError: ConfigParser instance has no attribute 'getitem' 20230404 ed ...
- python 二级 基本数据类型
1.思维导图 需要特殊记忆知识点 -1.01E-3值为 0.00101 基本运算一共9个: 取整 a//b 取余数 a%b x的y次幂 :x**y 数值运算函数 format 格式的控制 常用的操作 ...
- go string转int strconv包
前言 strconv 主要用于字符串和基本类型的数据类型的转换 s := "aa"+100 //字符串和整形数据不能放在一起 所以需要将 100 整形转为字符串类型 //+号在字符 ...
- go cobra实例讲解
概述 cobra 库是 golang 的一个开源第三方库,能够快速便捷的建立命令行应用程序. 优势:cobra 可以快速建立CLI程序,使我们更专注于命令需要处理的具体的业务逻辑. 举两个例子: hu ...
- 原生JS实现虚拟列表(不使用Vue,React等前端框架)
好家伙, 1. 什么是虚拟列表 虚拟列表(Virtual List)是一种优化长列表渲染性能的技术.当我们需要展示成千上万条数据时,如果一次性将所有数据渲染到DOM中,会导致页面卡顿甚至崩溃.虚拟 ...
- RabbitMQ集群部署(一)——单机模式部署
本文分享自天翼云开发者社区<RabbitMQ集群部署(一)--单机模式部署>,作者:芋泥麻薯 RabbitMQ是一种开源消息队列系统,是AMQP的标准实现,用erlang语言开发.Rabb ...
- 冒泡排序--java进阶day06
1.冒泡排序 https://kdocs.cn/l/ciMkwngvaWfz?linkname=150996835 我们会发现上图排序的样子非常像之前打印的倒三角,所以,冒泡排序也需要使用循环嵌套 2 ...