内存吞金兽(Elasticsearch)的那些事儿 -- 写入&检索原理
协调节点
客户端写入一条数据,到Elasticsearch集群里边就是由协调节点来处理这次请求:

集群上的每个节点都是coordinating node,表明这个节点可以做路由。比如节点1接收到了请求,但发现这个请求的数据应该是由节点2处理(因为主分片在节点2上),所以会把请求转发到节点2上。
- coodinate node通过hash算法可以计算出是在哪个主分片上,然后路由到对应的index node
shard = hash(document_id) % (num_of_primary_shards)
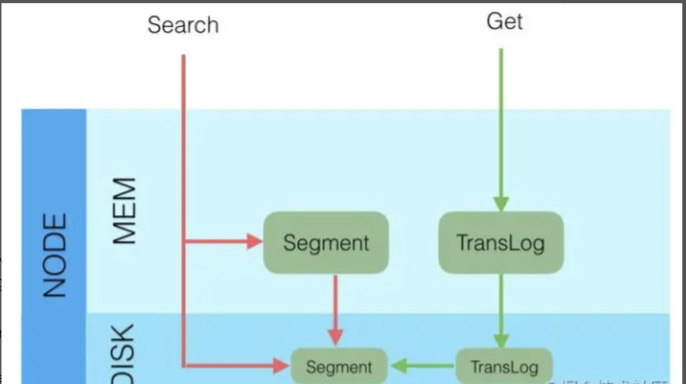
节点写入
- 将数据写到内存缓存区
- 然后将数据写到translog缓存区
- 定期将数据从buffer中refresh到FileSystemCache中,生成segment文件,一旦生成segment文件,就能通过索引查询到了
- refresh完,memory buffer就清空了。
- 定期将translog 从buffer flush到磁盘中
- 定期/定量从FileSystemCache中,结合translog内容
flush index到磁盘中。

默认配置运行流程:
- Elasticsearch会把数据先写入内存缓冲区,然后每隔1s刷新到文件系统缓存区(当数据被刷新到文件系统缓冲区以后,数据才可以被检索到)。所以:Elasticsearch写入的数据需要1s才能查询到
- 为了防止节点宕机,内存中的数据丢失,Elasticsearch会另写一份数据到日志文件上,但最开始的还是写到内存缓冲区,每隔5s才会将缓冲区的刷到磁盘中。所以:Elasticsearch某个节点如果挂了,可能会造成有5s的数据丢失。
- 等到磁盘上的translog文件大到一定程度或者超过了30分钟,会触发commit操作,将内存中的segment文件异步刷到磁盘中,完成持久化操作。
说白了就是:写内存缓冲区(定时去生成segment,生成translog),能够让数据能被索引、被持久化。最后通过commit完成一次的持久化。
最后
等主分片写完了以后,会将数据并行发送到副本集节点上,等到所有的节点写入成功就返回ack给协调节点,协调节点返回ack给客户端,完成一次的写入。
更新和删除
- 给对应的
doc记录打上.del标识,如果是删除操作就打上delete状态,如果是更新操作就把原来的doc标志为delete,然后重新新写入一条数据 前面提到了,每隔1s会生成一个segment 文件,那segment文件会越来越多越来越多。Elasticsearch会有一个merge任务,会将多个segment文件合并成一个segment文件。在合并的过程中,会把带有
delete状态的doc给物理删除掉。
检索原理
核心
link:3. 数据结构
两大类
es的检索主要分为两大类
- 根据ID查询doc(实时)
- 检索内存的Translog文件
- 检索硬盘的Translog文件
- 检索硬盘的Segment文件
- 根据query(搜索词)去查询匹配的doc(近实时,因为segment文件是每隔一秒才生成一次的)
- 查询Segment
三阶段
QUERY_AND_FETCH(查询完就返回整个Doc内容)
QUERY_THEN_FETCH(先查询出对应的Doc id ,然后再根据Doc id 匹配去对应的文档)
DFS_QUERY_THEN_FETCH(先算分,再查询)
- 「这里的分指的是 词频率和文档的频率(Term Frequency、Document Frequency)众所周知,出现频率越高,相关性就更强」
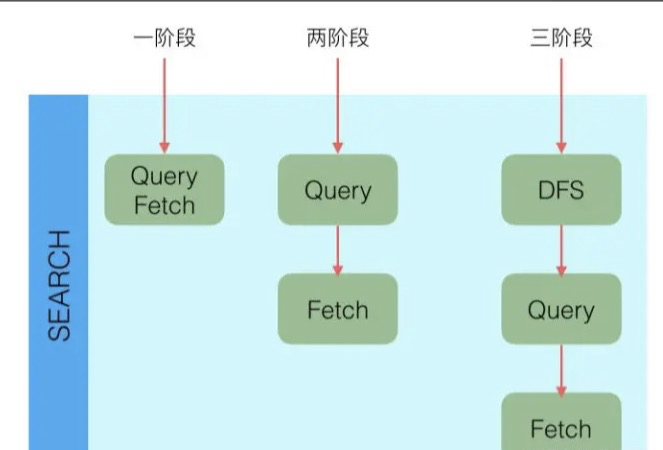
一般我们用得最多的就是QUERY_THEN_FETCH,第一种查询完就返回整个Doc内容(QUERY_AND_FETCH)只适合于只需要查一个分片的请求。
QUERY_THEN_FETCH总体的大概流程流程:
- 客户端请求发送到集群的某个节点上。集群上的每个节点都是coordinate node(协调节点)
- 然后协调节点将搜索的请求转发到所有分片上(主分片和副本分片都行)
- 每个分片将自己搜索出的结果
(doc id)返回给协调节点,由协调节点进行数据的合并、排序、分页等操作,产出最终结果。 - 接着由协调节点根据
doc id去各个节点上拉取实际的document数据,最终返回给客户端。
Query Phase阶段时节点做的事:
- 协调节点向目标分片发送查询的命令(转发请求到主分片或者副本分片上)
- 数据节点(在每个分片内做过滤、排序等等操作),返回
doc id给协调节点
Fetch Phase阶段时节点做的是:
- 协调节点得到数据节点返回的
doc id,对这些doc id做聚合,然后将目标数据分片发送抓取命令(希望拿到整个Doc记录) - 数据节点按协调节点发送的
doc id,拉取实际需要的数据返回给协调节点
内存吞金兽(Elasticsearch)的那些事儿 -- 写入&检索原理的更多相关文章
- 内存吞金兽(Elasticsearch)的那些事儿 -- 认识一下
背景及常见术语 背景 Elasticsearch 是一个开源的搜索引擎,建立在一个全文搜索引擎库 Apache Lucene 基础之上. Lucene 可以说是当下最先进.高性能.全功能的搜索引擎库- ...
- 内存吞金兽(Elasticsearch)的那些事儿 -- 常见问题痛点及解决方案
1.大数据量的查询效率如何保证: 查询的流程:往 ES 里写的数据,实际上都写到磁盘文件里去了,查询的时候,操作系统会将磁盘文件里的数据自动缓存到 Filesystem Cache 里面去 最佳的情况 ...
- elasticsearch 亿级数据检索案例与原理
版权说明: 本文章版权归本人及博客园共同所有,转载请标明原文出处( https://www.cnblogs.com/mikevictor07/p/10006553.html ),以下内容为个人理解,仅 ...
- Elasticsearch系列---Elasticsearch的基本概念及工作原理
基本概念 Elasticsearch有几个核心的概念,花几分钟时间了解一下,有助于后面章节的学习. NRT Near Realtime,近实时,有两个层面的含义,一是从写入一条数据到这条数据可以被搜索 ...
- Elasticsearch-基础介绍及索引原理分析(转载)
最近在参与一个基于Elasticsearch作为底层数据框架提供大数据量(亿级)的实时统计查询的方案设计工作,花了些时间学习Elasticsearch的基础理论知识,整理了一下,希望能对Elastic ...
- Elasticsearch-基础介绍及索引原理分析
介绍 Elasticsearch 是一个分布式可扩展的实时搜索和分析引擎,一个建立在全文搜索引擎 Apache Lucene(TM) 基础上的搜索引擎.当然 Elasticsearch 并不仅仅是 L ...
- Elasticsearch由浅入深(十一)内核原理
倒排索引组成结构以及索引不可变原因 对于倒排索引是非常适合用来进行搜索的它的结构:(1)包含这个关键词的document list(2)包含这个关键词的所有document的数量:IDF(invers ...
- elasticsearch 基础 —— 分布式文档存储原理
路由一个文档到一个分片中 当索引一个文档的时候,文档会被存储到一个主分片中. Elasticsearch 如何知道一个文档应该存放到哪个分片中呢?当我们创建文档时,它如何决定这个文档应当被存储在分片 ...
- ElasticSearch第三弹之存储原理
我们上文中介绍的ES内部索引的写处理流程是在ES的内存中执行的,而数据被分配到特定的主.副分片上之后,最终是存储到磁盘上的,这样在断电的时候就不会丢失数据.具体的存储路径可在配置文件 ../confi ...
- Elasticsearch(二)--集群原理及优化
一.ES原理 1.索引结构ES是面向文档的 各种文本内容以文档的形式存储到ES中,文档可以是一封邮件.一条日志,或者一个网页的内容.一般使用 JSON 作为文档的序列化格式,文档可以有很多字段,在创建 ...
随机推荐
- C#常见的四种经典查找算法
前言 在编程领域,数据结构与算法是构建高效.可靠和可扩展软件系统的基石.它们对于提升程序性能.优化资源利用以及解决复杂问题具有至关重要的作用.今天大姚给大家分享四种C#中常见的经典查找算法. C#数据 ...
- Linux进程监控系统
目录 动态监控进程 top 基本语法 关键信息说明 第一行:系统信息 第二行:进程信息 第三行:CPU占用情况 第四行:内存信息 第五行:交换区信息 交互操作 操作选项 应用实例 监控网络状态 net ...
- ubuntu服务器上部署EMQX SLL
1. 安装MQTT的简易服务器集成环境EMQX $wget https://www.emqx.com/zh/downloads/broker/5.1.6/emqx-5.1.6-ubuntu18 ...
- 基于YOLO实现滑块验证码破解
申明:本案例中的思路和技术仅用于学习交流.请勿用于非法行为. 一.训练模型 详细训练步骤和导出模型参考 滑块验证码识别模型训练 二.模型试用 通过YoloDotNet运行模型,计算出滑块缺口位置后用R ...
- PA1-总结
前言 代码全是自己写的,没看过参考代码,思路也有部分和指导书不一样,算是个原创?然后毕竟pa1是简单的部分,也没有什么值得骄傲的地方,只是作为一次记录. 毕竟自己的水平还是有限,可能部分地方会有些bu ...
- Sublime之快捷操作
列举常用的Sublime操作,涉及操作 1.每行默认需要统一添加逗号 1)全选 ctrl + a 2) 组合键 ctrl + shift + l 即可进行操作 (这里是L哦) 之后也可以使用HOME键 ...
- mysql5.7之密码重置
一.windows下更改mysql数据库密码在windows下找到my.ini文件,例如:C:\ProgramData\MySQL\MySQL Server 5.7,打开该文件夹下的my.ini文件, ...
- 进程管理工具之PM2
Github地址 https://github.com/Unitech/pm2 官方文档 http://pm2.keymetrics.io/docs/usage/quick-start/ npm安装 ...
- 从Hbase shell理解列式存储
列存储和行存储在理解上的差别挺大,特别是在非常数据行存储之后. 在行存储中,每张表的结构是固定的,某一列可以没有值但是这一列是必须在的.那么可以理解行存储的数据是结构化的. 但是列存储确有每行的数据却 ...
- element-ui季度选择组件
1.基于elementui开发的季度选择组件 2.调用 <el-quarter-picker v-model="start_time" :size="size&qu ...