内存吞金兽(Elasticsearch)的那些事儿 -- 写入&检索原理
协调节点
客户端写入一条数据,到Elasticsearch集群里边就是由协调节点来处理这次请求:

集群上的每个节点都是coordinating node,表明这个节点可以做路由。比如节点1接收到了请求,但发现这个请求的数据应该是由节点2处理(因为主分片在节点2上),所以会把请求转发到节点2上。
- coodinate node通过hash算法可以计算出是在哪个主分片上,然后路由到对应的index node
shard = hash(document_id) % (num_of_primary_shards)
节点写入
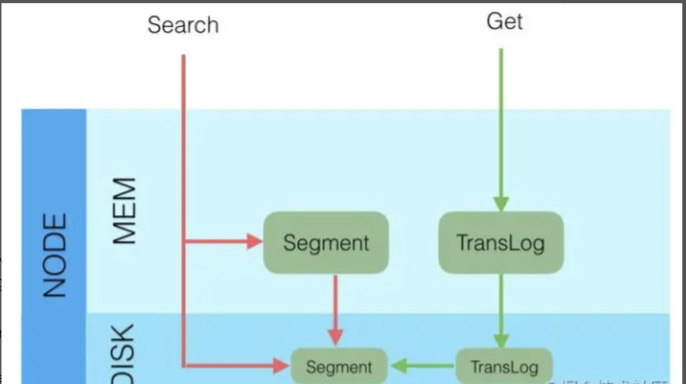
- 将数据写到内存缓存区
- 然后将数据写到translog缓存区
- 定期将数据从buffer中refresh到FileSystemCache中,生成segment文件,一旦生成segment文件,就能通过索引查询到了
- refresh完,memory buffer就清空了。
- 定期将translog 从buffer flush到磁盘中
- 定期/定量从FileSystemCache中,结合translog内容
flush index到磁盘中。

默认配置运行流程:
- Elasticsearch会把数据先写入内存缓冲区,然后每隔1s刷新到文件系统缓存区(当数据被刷新到文件系统缓冲区以后,数据才可以被检索到)。所以:Elasticsearch写入的数据需要1s才能查询到
- 为了防止节点宕机,内存中的数据丢失,Elasticsearch会另写一份数据到日志文件上,但最开始的还是写到内存缓冲区,每隔5s才会将缓冲区的刷到磁盘中。所以:Elasticsearch某个节点如果挂了,可能会造成有5s的数据丢失。
- 等到磁盘上的translog文件大到一定程度或者超过了30分钟,会触发commit操作,将内存中的segment文件异步刷到磁盘中,完成持久化操作。
说白了就是:写内存缓冲区(定时去生成segment,生成translog),能够让数据能被索引、被持久化。最后通过commit完成一次的持久化。
最后
等主分片写完了以后,会将数据并行发送到副本集节点上,等到所有的节点写入成功就返回ack给协调节点,协调节点返回ack给客户端,完成一次的写入。
更新和删除
- 给对应的
doc记录打上.del标识,如果是删除操作就打上delete状态,如果是更新操作就把原来的doc标志为delete,然后重新新写入一条数据 前面提到了,每隔1s会生成一个segment 文件,那segment文件会越来越多越来越多。Elasticsearch会有一个merge任务,会将多个segment文件合并成一个segment文件。在合并的过程中,会把带有
delete状态的doc给物理删除掉。
检索原理
核心
link:3. 数据结构
两大类
es的检索主要分为两大类
- 根据ID查询doc(实时)
- 检索内存的Translog文件
- 检索硬盘的Translog文件
- 检索硬盘的Segment文件
- 根据query(搜索词)去查询匹配的doc(近实时,因为segment文件是每隔一秒才生成一次的)
- 查询Segment
三阶段
QUERY_AND_FETCH(查询完就返回整个Doc内容)
QUERY_THEN_FETCH(先查询出对应的Doc id ,然后再根据Doc id 匹配去对应的文档)
DFS_QUERY_THEN_FETCH(先算分,再查询)
- 「这里的分指的是 词频率和文档的频率(Term Frequency、Document Frequency)众所周知,出现频率越高,相关性就更强」
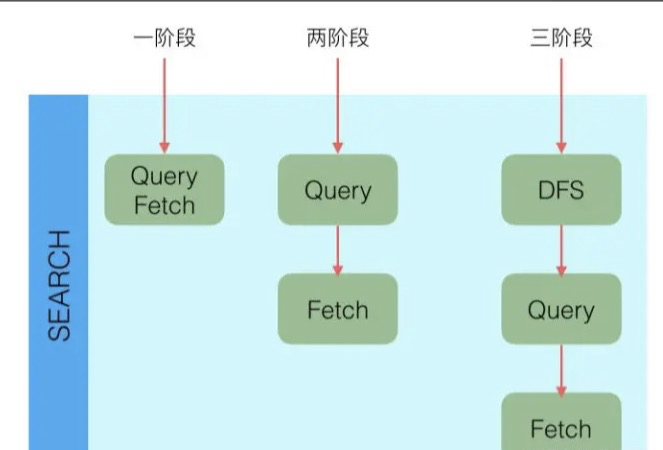
一般我们用得最多的就是QUERY_THEN_FETCH,第一种查询完就返回整个Doc内容(QUERY_AND_FETCH)只适合于只需要查一个分片的请求。
QUERY_THEN_FETCH总体的大概流程流程:
- 客户端请求发送到集群的某个节点上。集群上的每个节点都是coordinate node(协调节点)
- 然后协调节点将搜索的请求转发到所有分片上(主分片和副本分片都行)
- 每个分片将自己搜索出的结果
(doc id)返回给协调节点,由协调节点进行数据的合并、排序、分页等操作,产出最终结果。 - 接着由协调节点根据
doc id去各个节点上拉取实际的document数据,最终返回给客户端。
Query Phase阶段时节点做的事:
- 协调节点向目标分片发送查询的命令(转发请求到主分片或者副本分片上)
- 数据节点(在每个分片内做过滤、排序等等操作),返回
doc id给协调节点
Fetch Phase阶段时节点做的是:
- 协调节点得到数据节点返回的
doc id,对这些doc id做聚合,然后将目标数据分片发送抓取命令(希望拿到整个Doc记录) - 数据节点按协调节点发送的
doc id,拉取实际需要的数据返回给协调节点
内存吞金兽(Elasticsearch)的那些事儿 -- 写入&检索原理的更多相关文章
- 内存吞金兽(Elasticsearch)的那些事儿 -- 认识一下
背景及常见术语 背景 Elasticsearch 是一个开源的搜索引擎,建立在一个全文搜索引擎库 Apache Lucene 基础之上. Lucene 可以说是当下最先进.高性能.全功能的搜索引擎库- ...
- 内存吞金兽(Elasticsearch)的那些事儿 -- 常见问题痛点及解决方案
1.大数据量的查询效率如何保证: 查询的流程:往 ES 里写的数据,实际上都写到磁盘文件里去了,查询的时候,操作系统会将磁盘文件里的数据自动缓存到 Filesystem Cache 里面去 最佳的情况 ...
- elasticsearch 亿级数据检索案例与原理
版权说明: 本文章版权归本人及博客园共同所有,转载请标明原文出处( https://www.cnblogs.com/mikevictor07/p/10006553.html ),以下内容为个人理解,仅 ...
- Elasticsearch系列---Elasticsearch的基本概念及工作原理
基本概念 Elasticsearch有几个核心的概念,花几分钟时间了解一下,有助于后面章节的学习. NRT Near Realtime,近实时,有两个层面的含义,一是从写入一条数据到这条数据可以被搜索 ...
- Elasticsearch-基础介绍及索引原理分析(转载)
最近在参与一个基于Elasticsearch作为底层数据框架提供大数据量(亿级)的实时统计查询的方案设计工作,花了些时间学习Elasticsearch的基础理论知识,整理了一下,希望能对Elastic ...
- Elasticsearch-基础介绍及索引原理分析
介绍 Elasticsearch 是一个分布式可扩展的实时搜索和分析引擎,一个建立在全文搜索引擎 Apache Lucene(TM) 基础上的搜索引擎.当然 Elasticsearch 并不仅仅是 L ...
- Elasticsearch由浅入深(十一)内核原理
倒排索引组成结构以及索引不可变原因 对于倒排索引是非常适合用来进行搜索的它的结构:(1)包含这个关键词的document list(2)包含这个关键词的所有document的数量:IDF(invers ...
- elasticsearch 基础 —— 分布式文档存储原理
路由一个文档到一个分片中 当索引一个文档的时候,文档会被存储到一个主分片中. Elasticsearch 如何知道一个文档应该存放到哪个分片中呢?当我们创建文档时,它如何决定这个文档应当被存储在分片 ...
- ElasticSearch第三弹之存储原理
我们上文中介绍的ES内部索引的写处理流程是在ES的内存中执行的,而数据被分配到特定的主.副分片上之后,最终是存储到磁盘上的,这样在断电的时候就不会丢失数据.具体的存储路径可在配置文件 ../confi ...
- Elasticsearch(二)--集群原理及优化
一.ES原理 1.索引结构ES是面向文档的 各种文本内容以文档的形式存储到ES中,文档可以是一封邮件.一条日志,或者一个网页的内容.一般使用 JSON 作为文档的序列化格式,文档可以有很多字段,在创建 ...
随机推荐
- WebElement的常用属性和方法
WebElement是WebDriver.find_element()方法返回的一个对象,该对象用来描述Web上的一个元素,比如输入框,按钮等.本节介绍WebElement的常用属性和方法. 一.We ...
- ESP8266 + mg90s(舵机)
ESP8266+mg90s(舵机) 准备阶段 ESP8266(nodeMcu) MG90S(舵机) 面包板 线3 连线 ESP8266 MG90S(舵机) GND 棕色 VCC 红色 模拟引脚 橙色 ...
- ABC372 (D,E)
ABC372 (D,E) D 一道比较简单的二分查找题目. 观察到每个数能成为 \(j\) 的条件是独立的,因此想到统计每个数能成为它前面哪些数的 \(j\). 对于每个\(ed\), 二分 \(1 ...
- 3.5 Linux命令行下如何识别文件类型?
对于第一次使用 Linux 命令行的用户,可能真的搞不清楚哪个是文件,哪个是目录,究其原因是很难直接通过名字看出来目录和文件的区别. 虽然从名称上不容易分辨,但是可以从颜色上进行区分.一般情况下,Li ...
- Classical wave-optics analogy of quantum-information processing
量子信息处理的经典波-光模拟(Spreeuw 2002 PRA) <经典波光学.pdf> 核心: 1. 只有'局域纠缠' 有经典模拟! 基于经典波光学的模拟模型系统,应用于3个涉及到3qu ...
- LVM 使用与扩容总结
转载请注明出处: LVM(Logical Volume Manager,逻辑卷管理器)是一个用于Linux系统的磁盘管理工具.它提供了一种更加灵活的存储管理机制,可以方便地进行磁盘的扩容.缩减.快照以 ...
- 微软憋大招:SQL Server + Copilot = 地表最强AI数据库!
微软憋大招:SQL Server + Copilot = 地表最强AI数据库! 微软布局代码AI霸主地位 微软在人工智能领域的布局引人注目,尤其在代码生成领域,微软通过Copilot展现出了强大的竞争 ...
- Checking Table 设计模式 - 从概念、建模、设计到实现——兼谈基于业务需求驱动的设计模式创新
郑 先全, 架构师, NEC Asia Pacific Pte Ltd 简介: 如何基于业务需求驱动理念来开展我们的模式创新,成为了当今架构师.设计师的重要职责之一.本文通过具体的 Checking ...
- Git之清除历史记录操作
近期公司需要将之前代码仓库中的提交记录都清理,所以操作一下,记录一下步骤: 安全考虑: 有时候在提交代码时,不小心提交了敏感数据,如账号密码什么的,这样在历史记录中就可以查看到,这样很不安全,所以就需 ...
- Vue.js 文本交替滚动
1.前言 当一段文本需要单行显示,但是又限于容器宽度无法完全展示时,我们需要对其滚动展示,所以就有了这个插件,如图: 2.封装思路 使用js模拟循环滚动的动画,容器宽度固定且超出隐藏,文本元素禁止换行 ...