CUDA编程学习 (4)——thread执行效率
1. Warp 和 SIMD 硬件
1.1 作为调度单位的 Warp

每个 block 分为 32-thread warp
在 CUDA 编程模型中,虽然 warp 不是显式编程的一部分,但在硬件实现上,每个 block 会被自动划分成若干个包含 32 个线程的 warp。
warp 作为 SM 中的调度单元:SM(Streaming Multiprocessor)会以 warp 为单位进行调度和管理,这意味着在执行时,每次会选择一个 warp 中的 thread 来运行。
warp 中的线程以 SIMD 方式执行:SIMD(Single Instruction Multiple Data)是一种并行计算方式,表示一个 warp 中的所有 thread 会同时执行相同的指令,但可以处理不同的数据。
thread 数量未来可能变化:当前的 warp 包含 32 个 thread,但在未来的硬件架构中,warp 中的 thread 数量可能会有所改变。
1.2 多维 thread block 中的 warp
首先将 thread block 按行主次线性化为 1D
- 首先是 x 维,其次是 y 维,最后是 z 维,\(T_{row,col}=T_{y,x}\)
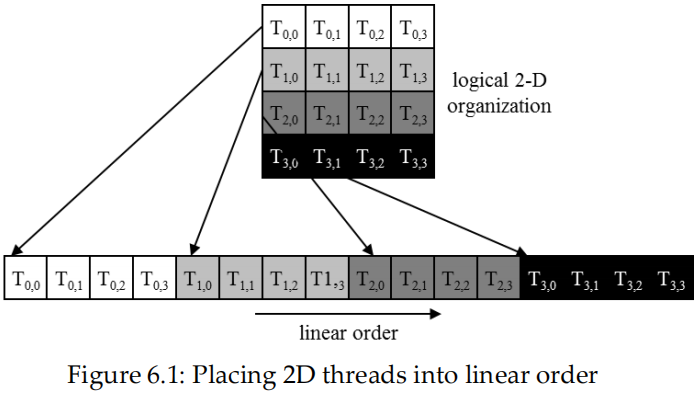
1.3 Block 在线性化后被分区
线性化 block 的划分:
- thread 索引在 warp 中是连续且递增的
- warp 0 从 thread 0 开始
分区方案在不同 device 上是一致的:
- 在不同的 CUDA device 上,warp 的分区方式是相同的,因此可以在控制流中利用这一点进行编程。
- 但是,warp 的确切大小可能会随代际变化:虽然当前 warp 通常包含 32 个 thread,但未来的硬件可能会改变这个大小。
不要依赖 warp 内或 warp 之间的执行顺序:
- CUDA 程序不能依赖 warp 内部或不同 warp 之间的执行顺序,因为 thread 的执行顺序并没有严格的保证。
- 如果 thread 之间存在依赖性,需要使用
__syncthreads()进行同步:当某些 thread 的结果会影响其他 thread 时,必须显式使用同步函数__syncthreads(),否则可能会得到错误的结果。
1.4 SMs 是 SIMD(单指令多数据流)处理器
指令获取、解码和控制的控制单元在多个处理单元之间共享
- 控制开销被最小化(模块1)
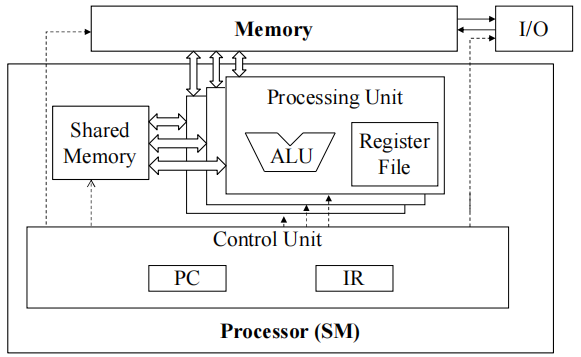
1.5 warp thread 间的 SIMD 执行
warp 中的所有 thread 在任何时间点都必须执行相同的指令
如果所有 thread 都遵循相同的控制流路径,这种方法就能高效运行
- 所有 if-then-else 语句都做出相同的决定
- 所有循环的遍历次数相同
1.6 控制分歧
当同一个 warp 中的 thread 由于做出不同的控制决策而走上不同的控制流路径时,就会发生控制分歧。
- 比如在一个
if语句中,一些 thread 选择走then路径,而另一些线程选择走else路径。 - 或者一些 thread 执行循环的次数比其他 thread 多。
当前 GPU 中,warp 中的 thread 如果选择了不同的控制路径,选择不同路径的 thread 会被串行化执行。
- GPU会依次执行每个控制路径,在执行某个路径时,所有选择该路径的线程会并行执行,而没有选择该路径的线程则会暂停(即这些线程不参与当前路径的执行)。
- 当涉及嵌套控制流语句(如嵌套的
if-else或循环)时,控制分歧的复杂性会增加,不同路径的数量也会变得非常大,进一步增加了执行的开销。
1.6.1 控制分歧示例
当分支或循环条件依赖于 thread 索引时,可能会产生分歧。
具有分歧的示例 kernel 语句:
if (threadIdx.x > 2) {}- 这为一个 block 中的 thread 创建了两条不同的控制路径
- 决策粒度 < warp的大小;thread 0、1 和 2 与第一个 warp 中的其余 thread 遵循不同的路径
没有分歧的示例:
if (blockIdx.x > 2) {}决策粒度 = block 的大小的倍数;在任何一个 warp 中的所有 thread 都会遵循相同的路径
1.7 示例:向量加法 kernel
// Device Code
// Compute vector sum C = A + B
// Each thread performs one pair-wise addition
__global__
void vecAddKernel(float* A, float* B, float* C, int n)
{
int i = threadIdx.x + blockDim.x * blockIdx.x;
if(i < n) C[i] = A[i] + B[i];
}
1.7.1 对 1000 个元素的向量大小进行分析
假设 block 大小为 256 个 thread
- 每个 block 有 8 个 warp
block 0、1 和 2 中的所有 thread 都在有效范围内
i值从 0 到 767这三个 block 中的 24 个 warp 都不会有控制分歧
block 3 中的大多数 warp 不会有控制分歧
- warp 0-6 中的 thread 都在有效范围内,因此没有控制分歧
block 3 中的一个 warp 会有控制分歧
thread 的
i值从 992 到 999 都在有效范围内thread 的
i值从 1000 到 1023 将超出有效范围
控制分歧导致的串行化效果很小
32 个 warp 中只有 1 个有控制分歧
对性能的影响可能小于 3%
2. 控制分歧对性能的影响
2.1 控制分歧对性能的影响
- 边界条件检查对并行代码的完整功能和稳健性至关重要
- tiled 矩阵乘法 kernel 有许多边界条件检查
- 令人担忧的是,这些检查可能会导致性能严重下降
例如,请看下面的 tile 加载代码:
if(Row < WIDTH && p * TILE_WIDTH + tx < WIDTH) {
ds_M[ty][tx] = M[Row * WIDTH + p * TILE_WIDTH + tx];
} else {
ds_M[ty][tx] = 0.0;
}
if(p * TILE_WIDTH + ty < WIDTH && Col < WIDTH) {
ds_N[ty][tx] = N[(p * TILE_WIDTH + ty) * WIDTH + Col];
} else {
ds_N[ty][tx] = 0.0;
}
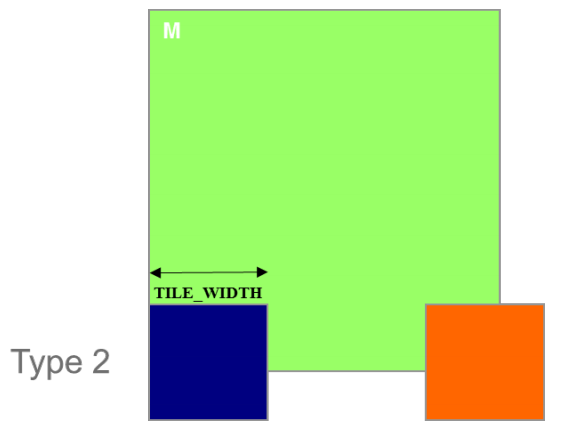
2.2 装载 M tiles 的两种 blocks
- Type 1:直到最后阶段,所有 tile 都在有效区域的 block
- Type 2:部分 tile 一直在有效范围之外的 block
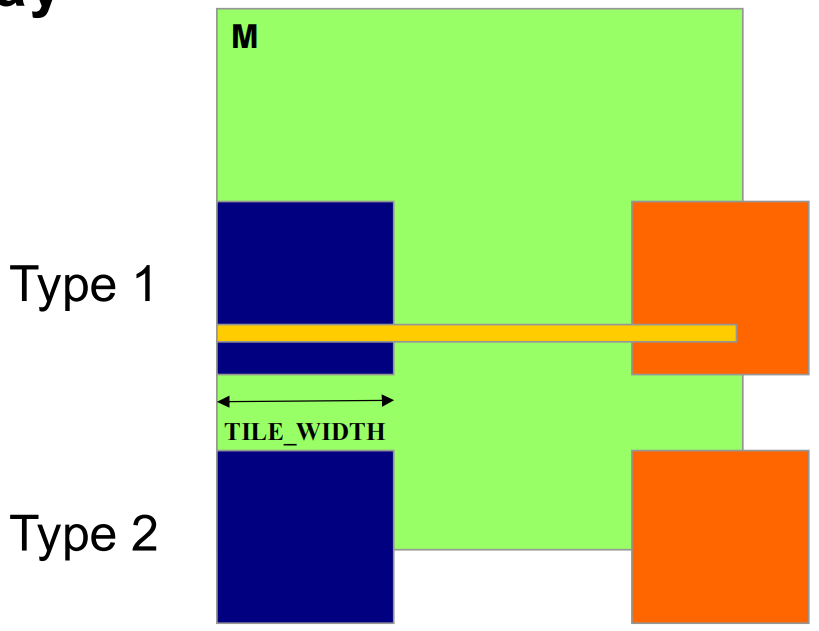
2.3 控制分歧影响分析
- 假设有 \(16\times 16\) tiles 和 thread blocks
- 每个 thread blocks 有 8 个 warps(\(256/32\))
- 假设有一个 \(100\times100\) 正方形矩阵
- 每个 thread 将经历 7 个阶段(\(100/16\) 的上限,因为 tiles 为 \(16 \times 16\))
- 共有 49 个 thread blocks(每个维度 7 个)
2.3.1 加载 M tiles 时的控制分歧
现在共有 42(\(6\times7\))个 Type 1 blocks,共 336(\(8\times42\))个 warps
它们都有 7 个阶段,因此共有 2,352 (\(336\times7\)) 个 warp-phases
warps 只有在最后阶段才有控制分歧
因此有 336 个 warp-phases 存在控制分歧
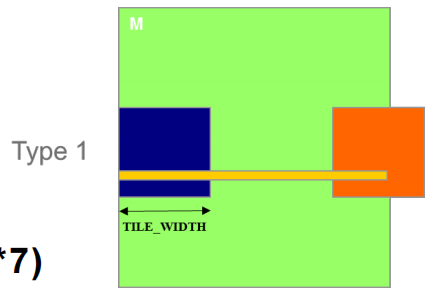
2.3.2 加载 M tiles 时的控制分歧(Type 2)
- Type 2:分配给载入底层 tiles 的 7 个 block,共有 56(\(8\times7\))个 warps
- 它们都有 7 个阶段,因此共有 392(\(56\times7\)) 个 warp-phases
- 每个 Type 2 block 中有两个 warp 处于 valid range 的边界,包涵控制分歧
- 其余 6 个 warp 不在有效范围内
- 因此,只有 14(\(2\times7\))warp-phases 有控制分歧
2.3.3 控制分歧的总体影响
- Type 1 Blocks:2,352 个 warp-phases 中有 336 个存在控制分歧
- Type 2 Blocks:392 个 warp-phases 中有 14 个存在控制分歧
- 对性能的影响预计低于 \(12\%\)(\(350/2,944\) 或 \((336+14)/(2352+14)\))
2.3.4 补充
- 计算 N tiles 加载控制分歧的影响略有不同(自行计算)
- 估计的性能影响取决于数据
- 对于较大的矩阵,影响会小得多
- 一般来说,控制分歧对大型输入数据集的边界条件检查影响不大
- 应毫不犹豫地使用边界检查,以确保充分发挥功能
- kernel 充满控制流结构并不意味着会出现大量控制分歧
- 我们将在 "并行算法模式" 模块中介绍一些自然会导致控制分歧的算法模式(如并行缩减)
CUDA编程学习 (4)——thread执行效率的更多相关文章
- CUDA编程学习笔记1
CUDA编程模型是一个异构模型,需要CPU和GPU协同工作. host和device host和device是两个重要的概念 host指代CPU及其内存 device指代GPU及其内存 __globa ...
- cuda编程学习1——hello world!
将c程序最简单的hello world用cuda编写在GPU上执行,以下为代码: #include<iostream>using namespace std;__global__ void ...
- mysql存储过程的学习(mysql提高执行效率之进阶过程)
1:存储过程: 答:存储过程是sql语句和控制语句的预编译集合,以一个名称存储并作为一个单元处理:存储过程存储在数据库内,可以由应用程序调用执行,而且允许用户声明变量以及进行流程控制,存储类型可以接受 ...
- CUDA编程学习相关
1. CUDA编程之快速入门:https://www.cnblogs.com/skyfsm/p/9673960.html 2. CUDA编程入门极简教程:https://blog.csdn.net/x ...
- cuda编程学习3——VectorSum
这个程序是把两个向量相加 add<<<N,1>>>(dev_a,dev_b,dev_c);//<N,1>,第一个参数N代表block的数量,第二个参数1 ...
- cuda编程学习2——add
cudaMalloc()分配的指针有使用限制,设备指针的使用限制总结如下: 1.可以将其传递给在设备上执行的函数 2.可以在设备代码中使用其进行内存的读写操作 3.可以将其传递给在主机上执行的函数 4 ...
- CUDA编程接口:异步并发执行的概念和API
1.主机和设备间异步执行 为了易于使用主机和设备间的异步执行,一些函数是异步的:在设备完全完成任务前,控制已经返回给主机线程了.它们是: 内核发射; 设备间数据拷贝函数; 主机和设备内拷贝小于64KB ...
- CUDA编程学习笔记2
第二章 cuda代码写在.cu/.cuh里面 cuda 7.0 / 9.0开始,NVCC就支持c++11 / 14里面绝大部分的语言特性了. Dim3 __host__ __device__ dim3 ...
- CUDA编程学习(四)
利用Block和Thread进行并行加速 _global_ void add(int *a, int *b, int *c) { int index = threadIdx.x + blockIdx. ...
- CUDA编程学习(三)
我们知道一个grid包含多个block,而一个block又包含多个thread,下面将是如何进行下thread中的并行. /**** Splot a block into parallel threa ...
随机推荐
- java_基本类型
1. 所有的基本类型都是小写 例如 int 2. 所有的类 类型首字母大写 例如String
- draw.io 输入数学公式
首先我们要把数学排版功能打开: 然后输入数学公式: AsciiMath 公式由 ` 包裹,如:`a2+b2 = c^2` LaTeX 公式由 $$ 包裹,如:$$\sqrt{3×-1}+(1+x)^2 ...
- 【测试平台开发】——01Vue前端框架实操
一.VScode官网地址 https://code.visualstudio.com/ 但是官网下载贼慢,需要修改下国内地址: 原地址:https://az764295.vo.msecnd.net/s ...
- win11(含win10)自带的一键镜像备份与还原方法
winxp和win7时代小伙伴们备份或恢复系统时大都采用类似一键ghost类的软件制作系统盘的映像,当遇到故障时再恢复,但win10和win11其实自带有这种映像制作和还原功能,我们就再也不需要额外安 ...
- Blender 2D动画
前情提要: 本来之前会的,很久没有弄,居然忘了,忘得透透的,没得办法,先简单记录一下 前提: 安装有Blender软件 步骤: 1. 打开Blender 2.点击文件,新建,2D Animation ...
- Could not resolve placeholder 'xxx.xxx.xxx' in value "http://${xxx.xxx.xxx}"
代码一切正常,忽然报这个错误, 原因为,当前配置在配置文件最后,且前面均为注释,把当前配置位置提前即可
- 【YashanDB知识库】含有NUL字节的varchar字符串查询时出现截断
[问题分类]功能使用 [关键字]NUL字符 [问题描述]数据库中插入一条含有NUL字符(\00)的字符串,使用yasql在终端进行查询,字符串从NUL处被截断,未能完整展示全部字符. [问题原因分析] ...
- mysql事务隔离级别及MVCC 原理
一.事务的隔离级别 为了保证事务与事务之间的修改操作不会互相影响,innodb希望不同的事务是隔离的执行的,互不干扰. 两个并发的事务在执行过程中有 读读.读写(一个事务在读某条数据的同时另一个事务在 ...
- 【效果】使用canvas rotate实现一个旋转的矩形
使用canvas rotate实现一个旋转的矩形,并且以矩形的中心为原点,围绕原点旋转: <canvas id="canvas" width="800" ...
- Angular – ESLint
介绍 Angular wrap 了一层 ESLint, 定义了一些 best practice guide. 这篇说说如何 setup 它. 这个 ESLint 并不是 under Angular T ...