Hive UDF作业
说到这次作业,看似简单的几个步骤,对于我这样的菜鸟来说可真是一波三折啊。下面来说说这次的步骤和我遇到的问题。
首先准备工作,搭建好hive环境,保证hadoop集群是启动的。这个就不多说了。
第一步:将数据导入Hive中
在hive中,创建 stock 表结构。
hive> create table if not exists stock (tradedate STRING,tradetime STRING,stockid STRING,buyprice DOUBLE,buysize INT,sellprice DOUBLE,sellsize INT)
>row format delimited fields terminated by ',' STORED AS TEXTFILE;
这一步没什么可说的,顺利进行
将HDFS中的股票历史数据导入hive中。
hive> LOAD DATA INPATH '/home/hadoop/stock.csv' INTO TABLE stock;
结果这里就报错了,错误提示是在hdfs上没有相匹配的目录文件,大概就是这个意思。
我当时就是想不明白是怎么回事,后来找了班上的一些同学的帮助。我们特训班7班的“西安—假装”同学那里我知道了错误的原因在哪里了。
原因:'/home/hadoop/stock.csv 的目录文件是在本地的linux上的,而hdfs是在
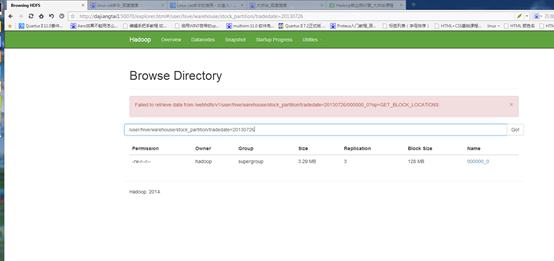
我自己开始就把概念搞混了,错误的以为hdfs是linux里的某个目录。正确操作应该是
hive> LOAD DATA LOCAL INPATH '/home/hadoop/stock.csv' INTO TABLE stock;
加上LOCAL表示本地的意思。

创建分区表 stock_partition,用日期做为分区表的分区ID。
hive> create table if not exists stock_partition (tradetime STRING,stockid STRING,buyprice DOUBLE,buysize INT,sellprice DOUBLE,sellsize INT)
>partitioned by (tradedate STRING) row format delimited fields terminated by ',';
如果设置动态分区首先执行。
hive>set hive.exec.dynamic.partition.mode=nonstrict;
创建动态分区,将stock表中的数据导入stock_partition表。
hive> insert overwrite table stock_partition partition(tradedate)
> select tradetime,stockid,buyprice,buysize,sellprice,sellsize, tradedate from stock distribute by tradedate;
这几步也ok没什么大问题,就是将stock表中的数据导入stock_partition表,这个过程需要一些时间,耐心等待。
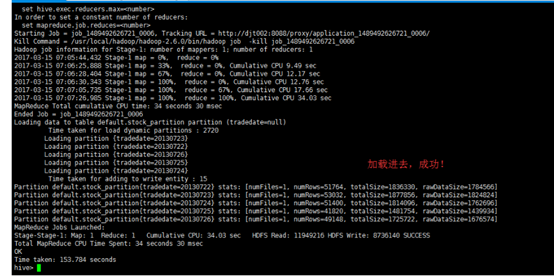
接下来遇到的问题就麻烦了,我也是请教了别人才知道原因出在哪里。
Hive 自定义Max统计最大值,和Hive 自定义Min统计最小值。这两个函数的时候我居然还犯了这样的低级错误自己开始还不知道。
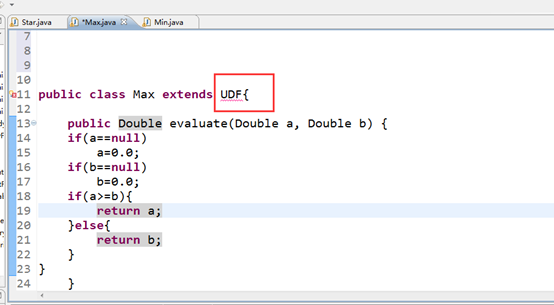
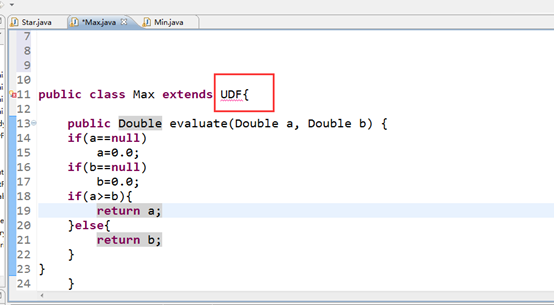
我就直接打包到linux下去使用,毫无疑问肯定报错。其实就是缺少了hive的架包没因进去。
经过到网上下载hive架包,把架包添加到工程,错误消失了,再次打包,结果还是报错了
首先这步将自定义的Max和Min分别打包成maxUDF.jar和minUDF.jar, 然后上传至/home/hadoop/hive目录下,添加Hive自定义的UDF函数
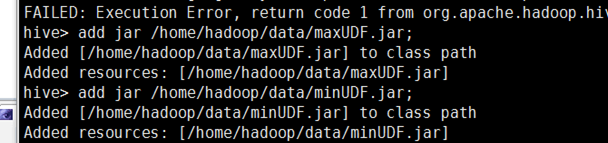
没问题。
接下来创建Hive自定义的临时方法maxprice和minprice

问题来了。
这有说什么原因呢???真的要问下自己了,基础太不扎实了,简直漏洞百出,实在没有头绪的时候,我又和我们班的同学还老师请教了下,开始我是核对jdk版本是否一致,核对结果是一样的,排除了jdk的问题,经过老师和同学的指导,分析:
- 我敲的代码有问题,经过检查,代码没问题,该引入的包都引入了。
- Hive环境没搭建好,这个原因也排除。
- 那就只有最后一个原因了,打包的过程出了问题。
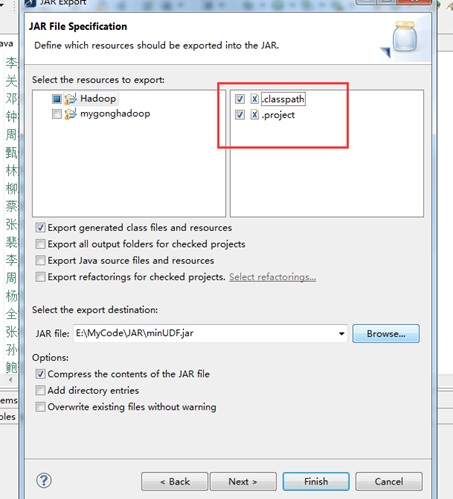
确实是,打包的时候应把这两个文件一起打包,我开始是只打包了代码。
OK这样打包后顺利通过,没问题了

统计204001股票,每日的最高价格和最低价格

真是活见鬼了,没有哪步是顺利过的。又出错了
好吧,分析错误吧,其实这个是图文教程里出错了,正确的应该是
select stockid,tradedate, max(maxprice(buyprice,sellprice)),min(minprice(buyprice,sellprice)) from stock_partition where stockid='204001' group by stockid,tradedate;
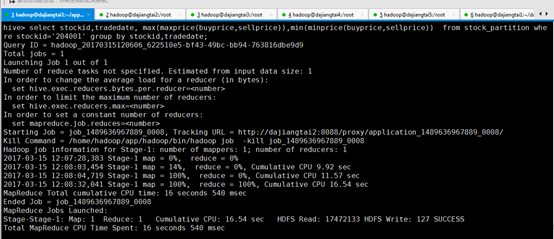
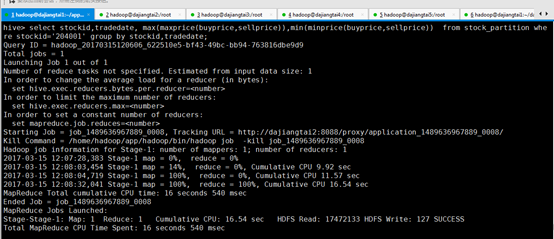
经过实现,结果出来了
统计204001这只股票,每天每分钟的均价

OK结果也出来了,到这里本次作业完成!
Hive UDF作业的更多相关文章
- Hive UDF初探
1. 引言 在前一篇中,解决了Hive表中复杂数据结构平铺化以导入Kylin的问题,但是平铺之后计算广告日志的曝光PV是翻倍的,因为一个用户对应于多个标签.所以,为了计算曝光PV,我们得另外创建视图. ...
- Hive UDF 实验1
项目中使用的hive版本低于0.11,无法使用hive在0.11中新加的开窗分析函数. 在项目中需要使用到row_number()函数的地方,有人写了udf来实现这个功能. new java proj ...
- hive UDF添加方式
hive UDF添加的方式 1.添加临时函数,只能在此会话中生效,退出hive自动失效 hive> add jar /home/jtdata/hiveUDF/out0.jar; Added [/ ...
- DeveloperGuide Hive UDF
Creating Custom UDFs First, you need to create a new class that extends UDF, with one or more method ...
- Hive 执行作业时报错 [ Diagnostics: File file:/ *** reduce.xml does not exist FileNotFoundException: File file:/ ]
2019-03-10 本篇文章旨在阐述本人在某一特定情况下遇到 Hive 执行 MapReduce 作业的问题的探索过程与解决方案.不对文章的完全.绝对正确性负责. 解决方案 Hive 的配置文件 ...
- [转]HIVE UDF/UDAF/UDTF的Map Reduce代码框架模板
FROM : http://hugh-wangp.iteye.com/blog/1472371 自己写代码时候的利用到的模板 UDF步骤: 1.必须继承org.apache.hadoop.hive ...
- 2、Hive UDF编程实例
Hive的UDF包括3种:UDF(User-Defined Function).UDAF(User-Defined Aggregate Function)和UDTF(User-Defined Tabl ...
- Hive UDF 用户自定义函数 编程及使用
首先创建工程编写UDF 代码,示例如下: 1. 新建Maven项目 udf 本机Hadoop版本为2.7.7, Hive版本为1.2.2,所以选择对应版本的jar ,其它版本也不影响编译. 2. po ...
- Hive UDF开发-简介
Hive进行UDF开发十分简单,此处所说UDF为Temporary的function,所以需要hive版本在0.4.0以上才可以. Hive的UDF开发只需要重构UDF类的evaluate函数即可.例 ...
随机推荐
- javascript UI lib
react 现在已经有JS,android,IOS版本的了 react作为View层的库,结合Flux react native Angular 是 MVVM, React 是 Flux(或者 MVC ...
- webpack 3 升级到 webpack 4,遇到问题解决
报错:Error: Chunk.entrypoints: Use Chunks.groupsIterable and filter by instanceof Entrypoint instead 解 ...
- 5、微信卡券code模式
非自定义Code码: "use_custom_code":false,可以群发卡券,客服消息派发卡券 自定义code: "use_custom_code":tr ...
- jquery.form插件中动态修改表单数据
jquery.form jquery.form插件(http://malsup.com/jquery/form/)是大家经常会用到的一个jQuery插件,它可以很方便将表单转换为ajax的方式进行提交 ...
- 在没有go-pear.bat的php中安装pear
因为需要安装phpunit,要先装pear,网上的教程大多数是以双击go-pear.bat开始,但是我安装的php文件夹里压根没有这个文件.经过几次搜索之后终于找到了办法.解决步骤如下:1.下载下面连 ...
- [转CSDN多篇文章]WEB 3D SVG CAD 矢量 几种实现方案
WEB 3D SVG CAD 矢量 几种实现方案 原创 2014年10月24日 08:34:11 标签: WEB3D / CADSVG / 矢量 2665 一.全部自己开发,从底层开始 VML+SVG ...
- GetClass与RegisterClass的应用一例
利用GetClass与RegisterClass可以实现根据字符串来实例化具体的子类,这对于某些需要动态配置程序的场合是很有用的.其他的应用如子窗体切换,算法替换等都能得到应用. unit Examp ...
- Delphi XE5的Android开发平台搭建[转]
Delphi XE5支持Android ARM的开发,可以在Android虚拟机里运行,因此建议将XE5安装在64bit的Windows,内存可以大于3GB Delphi XE5安装光盘中包含了最基本 ...
- onsubmit ajax return false 无效
var flat=false; return flat; async:false, 是重点. 执行ajax时return false的function 与onsubmit()不是同一个函数,所以无 ...
- TeamViewer 的早期版本下载
对于10及上以的:https://www.teamviewer.com/zhcn/download/previous-versions/ 5~9的版本下载:https://community.team ...