HashMap的扩容机制以及默认大小为何是2次幂
回顾HashMap的put(Key k, Value v)过程:
(1)对 Key求Hash值,对n-1取模计算出Hash表数组下标
(2)如果没有碰撞,直接放入桶中,即Hash表数组对应位置的链表表头。
(3)如果碰撞了,若节点已经存在就替换旧值,否则以链表的方式将该元素链接到后面。
(4)如果链表长度超过阀值(TREEIFY_THRESHOLD == 8),就把链表转成红黑树。红黑树我不熟悉,这里不展开讲。
(5)如果桶满了(容量 * 加载因子),就需要resize。
HashMap的扩容机制
假设length为Hash表数组的大小,方法indexFor(int hash, int length)为
indexFor(int hash, int length) {
return hash % length;
}
在旧数组中同一条Entry链上的元素,在resize过程中,通过重新计算索引位置后,有可能被放到了新数组的不同位置上。JDK8做了一些优化,resize过程中对Hash表数组大小的修改使用的是2次幂的扩展(指长度扩为原来2倍),这样有2个好处。
好处1
在hashmap的源码中。put方法会调用indexFor(int h, int length)方法,这个方法主要是根据key的hash值找到这个entry在Hash表数组中的位置,源码如下:
/**
* Returns index for hash code h.
*/
static int indexFor(int h, int length) {
// assert Integer.bitCount(length) == 1 : "length must be a non-zero power of 2";
return h & (length-1);
}
上述代码也相当于对length求模。 注意最后return的是h&(length-1)。如果length不为2的幂,比如15。那么length-1的2进制就会变成1110。在h为随机数的情况下,和1110做&操作。尾数永远为0。那么0001、1001、1101等尾数为1的位置就永远不可能被entry占用。这样会造成浪费,不随机等问题。 length-1 二进制中为1的位数越多,那么分布就平均。
好处2
以下图为例,其中图(a)表示扩容前的key1和key2两种key确定索引位置的示例,图(b)表示扩容后key1和key2两种key确定索引位置的示例,n代表length。
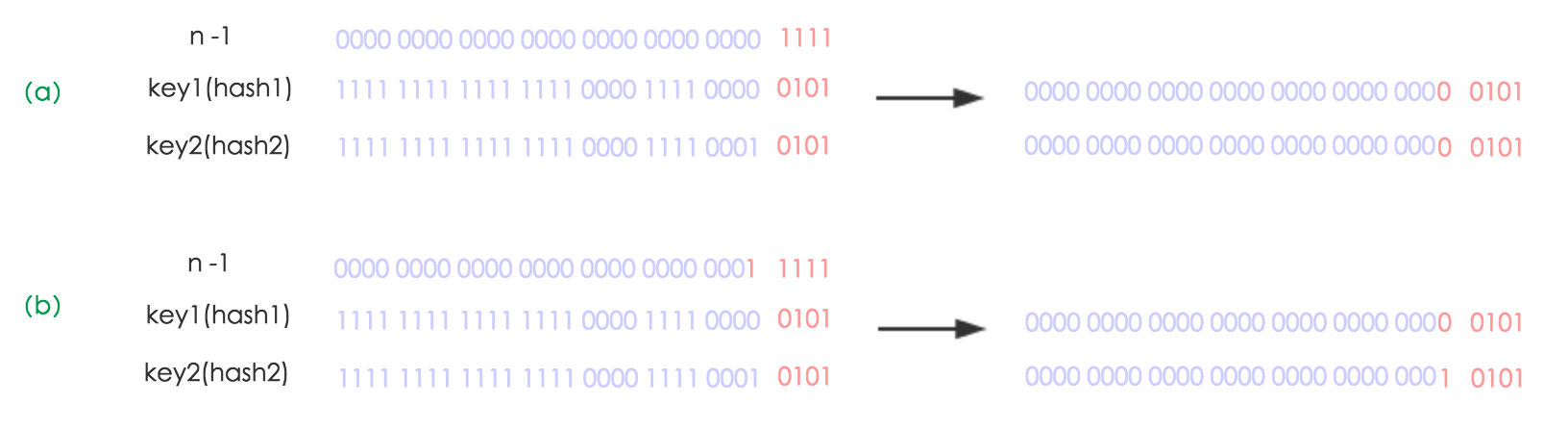
元素在重新计算hash之后,因为n变为2倍,那么n-1的mask范围在高位多1bit(红色),因此新的index就会发生这样的变化:
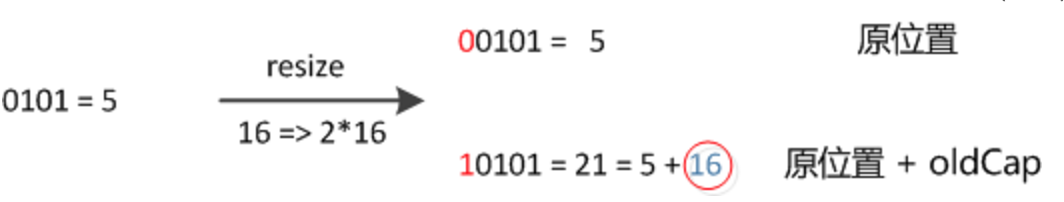
resize过程中不需要像JDK1.7的实现那样重新计算hash,只需要看看原来的hash值新增的那个bit是1还是0就好了,是0的话索引没变,是1的话索引变成“原索引+oldCap”,可以看看下图为16扩充为32的resize示意图(一方面位运算更快,另一方面抗碰撞的Hash函数其实挺耗时的):

源码如下
final Node<K,V>[] resize() {
Node<K,V>[] oldTab = table;
int oldCap = (oldTab == null) ? 0 : oldTab.length;
int oldThr = threshold;
int newCap, newThr = 0;
if (oldCap > 0) {
// 超过最大值就不再扩充了,就只好随你碰撞去吧
if (oldCap >= MAXIMUM_CAPACITY) {
threshold = Integer.MAX_VALUE;
return oldTab;
}
// 没超过最大值,就扩充为原来的2倍
else if ((newCap = oldCap << 1) < MAXIMUM_CAPACITY &&
oldCap >= DEFAULT_INITIAL_CAPACITY)
newThr = oldThr << 1; // double threshold
}
else if (oldThr > 0) // initial capacity was placed in threshold
newCap = oldThr;
else { // zero initial threshold signifies using defaults
newCap = DEFAULT_INITIAL_CAPACITY;
newThr = (int)(DEFAULT_LOAD_FACTOR * DEFAULT_INITIAL_CAPACITY);
}
// 计算新的resize上限
if (newThr == 0) {
float ft = (float)newCap * loadFactor;
newThr = (newCap < MAXIMUM_CAPACITY && ft < (float)MAXIMUM_CAPACITY ?
(int)ft : Integer.MAX_VALUE);
}
threshold = newThr;
@SuppressWarnings({"rawtypes","unchecked"})
Node<K,V>[] newTab = (Node<K,V>[])new Node[newCap];
table = newTab;
if (oldTab != null) {
// 把每个bucket都移动到新的buckets中
for (int j = 0; j < oldCap; ++j) {
Node<K,V> e;
if ((e = oldTab[j]) != null) {
oldTab[j] = null;
if (e.next == null)
newTab[e.hash & (newCap - 1)] = e;
else if (e instanceof TreeNode)
((TreeNode<K,V>)e).split(this, newTab, j, oldCap);
else { // preserve order 链表优化重hash的代码块
Node<K,V> loHead = null, loTail = null;
Node<K,V> hiHead = null, hiTail = null;
Node<K,V> next;
do {
next = e.next;
// 原索引
if ((e.hash & oldCap) == 0) {
if (loTail == null)
loHead = e;
else
loTail.next = e;
loTail = e;
}
// 原索引+oldCap
else {
if (hiTail == null)
hiHead = e;
else
hiTail.next = e;
hiTail = e;
}
} while ((e = next) != null);
// 原索引放到bucket里
if (loTail != null) {
loTail.next = null;
newTab[j] = loHead;
}
// 原索引+oldCap放到bucket里
if (hiTail != null) {
hiTail.next = null;
newTab[j + oldCap] = hiHead;
}
}
}
}
}
return newTab;
}
HashMap的扩容机制以及默认大小为何是2次幂的更多相关文章
- 深入理解HashMap的扩容机制
什么时候扩容: 网上总结的会有很多,但大多都总结的不够完整或者不够准确.大多数可能值说了满足我下面条件一的情况. 扩容必须满足两个条件: 1. 存放新值的时候当前已有元素的个数必须大于等于阈值 2. ...
- HashMap自动扩容机制源码详解
一.简介 HashMap的源码我们之前解读过,数组加链表,链表过长时裂变为红黑树.自动扩容机制没细说,今天详细看一下 往期回顾: Java1.7的HashMap源码分析-面试必备技能 Java1.8的 ...
- HashMap的扩容机制, ConcurrentHashMap和Hashtable主要区别
源代码查看,有三个常量, static final int DEFAULT_INITIAL_CAPACITY = 16; static final int MAXIMUM_CAPACITY = 1 & ...
- HashMap的扩容机制---resize()
虽然在hashmap的原理里面有这段,但是这个单独拿出来讲rehash或者resize()也是极好的. 什么时候扩容:当向容器添加元素的时候,会判断当前容器的元素个数,如果大于等于阈值---即当前数组 ...
- HashMap原理(二) 扩容机制及存取原理
我们在上一个章节<HashMap原理(一) 概念和底层架构>中讲解了HashMap的存储数据结构以及常用的概念及变量,包括capacity容量,threshold变量和loadFactor ...
- 面试题: Java中各个集合类的扩容机制
个人博客网:https://wushaopei.github.io/ (你想要这里多有) Java 中提供了很多的集合类,包括,collection的子接口list.set,以及map等.由于它 ...
- JDK1.8前_HashMap的扩容机制原理
最近在研究hashmap的扩容机制,作为一个小白,相信我的理解,对于一些同样是刚刚接触hashmap的白白是有很很大的帮助,毕竟你去看一些已经对数据结构了解透彻的大神谈hashmap的原理等,人家说的 ...
- 浅谈JAVA中HashMap、ArrayList、StringBuilder等的扩容机制
JAVA中的部分需要扩容的内容总结如下:第一部分: HashMap<String, String> hmap=new HashMap<>(); HashSet<Strin ...
- Java常见集合的默认大小及扩容机制
在面试后台开发的过程中,集合是面试的热话题,不仅要知道各集合的区别用法,还要知道集合的扩容机制,今天我们就来谈下ArrayList 和 HashMap的默认大小以及扩容机制. 在 Java 7 中,查 ...
随机推荐
- 20155305 2016-2017-2 《Java程序设计》实验一 Java开发环境的熟悉(macOS + IDEA)
20155305 2016-2017-2 <Java程序设计>实验一 Java开发环境的熟悉(macOS + IDEA) 实验内容 1.使用JDK编译.运行简单的Java程序: 2.使用E ...
- 20155339 2017-2018-1《信息安全系统设计》第四周课堂测试、Makefile以及myod
20155339 2017-2018-1<信息安全系统设计>第四周课堂测试.Makefile以及myod 测试1-vi 每个.c一个文件,每个.h一个文件,文件名中最好有自己的学号 用Vi ...
- 【HEOI2016】排序
题面 题解 这题好神仙啊... 我们二分这个位置上的数, 然后当\(val[i] \geq mid\)的位置设为\(1\),否则为\(0\) 这样一来,这道题就变成了一个\(01\)序列排序,所以就可 ...
- vmware因为软件出过一次复制的错误导致不能复制到主机的解决方法
只需要把vmware的虚拟机进程全部结束掉,然后重置(先设置不勾选复制等,然后保存后在勾选上并保存)一次虚拟机隔离设置(需要在关闭虚拟机的情况下设置,否则就是灰色不允许操作),然后再开启虚拟机,就能正 ...
- idea alt+enter导包时被锁定导某一个包时的解决方法
在只有一个包指向的时候,把光标放在Test这种字符之间的话 就会直接导这个 所以把光标放在最后就可以导别的了
- [深度学习] 使用Darknet YOLO 模型破解中文验证码点击识别
内容 背景 准备 实践 结果 总结 引用 背景 老规矩,先上代码吧 代码所在: https://github.com/BruceDone/darknet_demo 最近在做深度学习相关的项目的时候,了 ...
- Linux权限管理命令
查询linux命令用法网址:cht.sh 1.chmod——改变文件/目录的权限 用法: ① chmod [{ugoa}{+-=}{rwx}] [文件/目录] ---给文件的(用户.所属组.其他人 ...
- 自己动手做AI:Google AIY开发工具包解析
2018年国际消费性电子展(CES)上,最明显的一个趋势是Amazon与Google的语音技术进驻战,如AmazonAlexa进驻到Acer笔电内,Google Assist进驻到KIA汽车内,其他如 ...
- centos 6.5 双网卡 上网 virtualbox nat hostonly
虚拟机两张网卡:分别调成NAT(eth0)和host only(eht1)模式. nat的网卡不用设置,host only网卡调为(vi /etc/sysconfig/network-scripts/ ...
- Thymeleaf教程【转】
作者:不做浮躁的人 转自:http://www.blogjava.net/bjwulin/archive/2013/02/07/395234.html PS:其他推荐教程地址 http://blog. ...