jdk1.8 HashMap源码讲解
1. 开篇名义
jdk1.8中hashMap发生了一些改变,在之前的版本中hsahMap的组成是数组+链表的形式体现,而在1.8中则改为数组+链表+红黑树的形式实现,通过下面两张图来对比一下二者的不同。
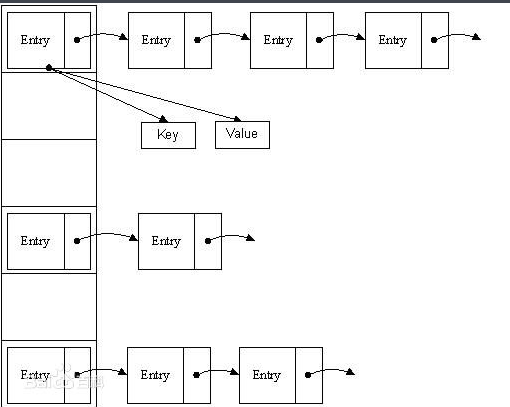
jdk1.8之前的hashMap结构图,基本对象为Entry<k,v>
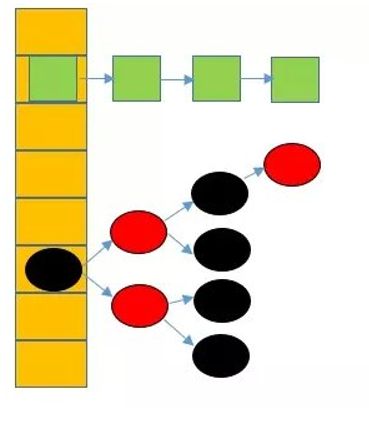
jdk1.8的hashMap结构图,基本对象改为了Node<k,v>
注意:无论Entry<key,value>还是Node<key,value>都实现了 Map.Entry<K,V> 接口;
下面的内容将不在讨论关于jdk1.7的内容,重点讨论一下jdk1.8中hashMap的相关代码实现
2. HashMap类概览(实现的接口、继承的类,以及成员变量)
public class HashMap<K,V> extends AbstractMap<K,V> implements Map<K,V>, Cloneable, Serializable {
// 序列号
private static final long serialVersionUID = 362498820763181265L;
// 默认的初始容量是16
static final int DEFAULT_INITIAL_CAPACITY = 1 << 4;
// 最大容量
static final int MAXIMUM_CAPACITY = 1 << 30;
// 默认的填充因子0.75f,可以在创建hashMap时指定
static final float DEFAULT_LOAD_FACTOR = 0.75f;
// 当桶(bucket)上的结点数大于这个值时会转成红黑树
static final int TREEIFY_THRESHOLD = 8;
// 当桶(bucket)上的结点数小于这个值时树转链表
static final int UNTREEIFY_THRESHOLD = 6;
// 桶中结构转化为红黑树对应的table的最小长度,即:当数组的长度大于64并且桶的长度大于8同时满足时,才会触发由链表变为红黑树
static final int MIN_TREEIFY_CAPACITY = 64;
/* ---------------- Fields -------------- */
transient Node<k,v>[] table; // 存储元素的数组,总是2的幂次倍,由tableSizeFor(int cap)方法计算得出,思考为什么要用transient关键字修饰
transient Set<map.entry<k,v>> entrySet; // 存放具体的元素的集 transient int size; // 存放元素的个数 transient int modCount; //每次扩容和更改map结构的计数器
int threshold; //临界值 当实际大小(容量*填充因子)超过临界值时,会进行扩容
final float loadFactor; //hashTable的填充因子,用于实际参与运算的加载因子 }
3. HashMap构造函数
3.1 HashMap的空参构造函数
/**
* HashMap的空参构造函数,该函数就做了一件事:
* 初始化转载因子,经默认的转载因子(0.75)赋值给loadFactor
*/
public HashMap() {
this.loadFactor = DEFAULT_LOAD_FACTOR; // all other fields defaulted
}
3.2 HashMap的单参构造函数
/**
* 单参数构造函数,指定hashMap的初始数组长度值
*
*/
public HashMap(int initialCapacity) {
//调用本类中(int,float)构造函数,测试转载因子为默认值
this(initialCapacity, DEFAULT_LOAD_FACTOR);
}
3.3 HashMap(int ,fioat)型构造函数
public HashMap(int initialCapacity, float loadFactor) { //指定初始容量和转载因子
// 初始容量不能小于0,否则报错
if (initialCapacity < 0)
throw new IllegalArgumentException("Illegal initial capacity: " +
initialCapacity);
// 初始容量不能大于最大值(1<<30),否则为最大值
if (initialCapacity > MAXIMUM_CAPACITY)
initialCapacity = MAXIMUM_CAPACITY;
// 填充因子不能小于或等于0,不能为非数字
if (loadFactor <= 0 || Float.isNaN(loadFactor))
throw new IllegalArgumentException("Illegal load factor: " +
loadFactor);
// 初始化填充因子
this.loadFactor = loadFactor;
// 初始化threshold大小,根据传入值的大小重新计算初始hashMap数组的长度临界值
this.threshold = tableSizeFor(initialCapacity);
}
3.4 HashMap(Map<? extends K, ? extends V> m)型构造函数
/**
* 根据传人的Map映射构造一个新的HashMap
*/
public HashMap(Map<? extends K, ? extends V> m) {
this.loadFactor = DEFAULT_LOAD_FACTOR;
putMapEntries(m, false);
}
//putMapEntries函数会将传进的map放到新的hashMap中
final void putMapEntries(Map<? extends K, ? extends V> m, boolean evict) {
int s = m.size();
if (s > 0) {
// 判断table是否已经初始化
if (table == null) { // pre-size
// 未初始化,s为m的实际元素个数
float ft = ((float)s / loadFactor) + 1.0F;
int t = ((ft < (float)MAXIMUM_CAPACITY) ?
(int)ft : MAXIMUM_CAPACITY);
// 计算得到的t大于阈值,则初始化阈值
if (t > threshold)
threshold = tableSizeFor(t);
}
// 已初始化,并且m元素个数大于阈值,进行扩容处理
else if (s > threshold)
resize();
// 将m中的所有元素添加至HashMap中
for (Map.Entry<? extends K, ? extends V> e : m.entrySet()) {
K key = e.getKey();
V value = e.getValue();
putVal(hash(key), key, value, false, evict);
}
}
}
3.5 总结
- 空参构造,初始化加载因子为默认值
- 单参数构造,指定数组初始长度(并非实际的长度,实际长度会根据tableSizeFor(int cap)函数进行计算,该构造函数自动调用双参数构造函数
- 双参构造函数,指定数组的实际长度(通过计算后直接获得)和加载因子;
- 传人键值对映射
注意:除了最后一种构造函数调用了putVal()方法进行了数组创建之外,其他构造方法只是在维护成员属性,并没有实际进行创建,创建数组实在putVal()方法中执行的
4.核心方法
4.1 根据初始值计算Map数组的初始长度
/**
* Returns a power of two size for the given target capacity.
* 返回大于给定值的最小的2的倍数
*/
static final int tableSizeFor(int cap) {
int n = cap - 1;
n |= n >>> 1; //让当前数据的最高位非0值补全低位数据,让高位参数到运算中,减少hash碰撞的产生
n |= n >>> 2;
n |= n >>> 4;
n |= n >>> 8;
n |= n >>> 16;
return (n < 0) ? 1 : (n >= MAXIMUM_CAPACITY) ? MAXIMUM_CAPACITY : n + 1;
}
思考:
- 首先为什么cap-1?
这是为了防止,cap已经是2的幂。如果cap已经是2的幂, 又没有执行这个减1操作,则执行完后面的几条无符号右移操作之后,返回的capacity将是这个cap的2倍。
- 为什么是分别后移1、2、4、8 、16?
正好是倍数关系,这样正好能保证比原始数据小的低位全部变为1,并且保证了效率,第一次移动一位后前两位变成11,再移动四位正好能将刚才的两位数再降位变成1111,再移动4位 正好将1111继续降位到后边
- 为什么不继续无符号右移32位?
因为hashMap的最大数为1<<30,经过上面的多次移动,一共移动了1+2+4+8+16,已经超过了30位
4.2 hashMap的put()
public V put(K key, V value) {
return putVal(hash(key), key, value, false, true); //在putVal()方法中进行第一次的数组创建
}
4.3 putVal()源码(最核心的方法)
final V putVal(int hash, K key, V value, boolean onlyIfAbsent,
boolean evict) {
Node<K,V>[] tab; Node<K,V> p; int n, i;
// 步骤①:tab为空则创建
// table未初始化或者长度为0,进行扩容
if ((tab = table) == null || (n = tab.length) == 0)
n = (tab = resize()).length;
// 步骤②:计算index,并对null做处理
// (n - 1) & hash 确定元素存放在哪个桶中,桶为空,新生成结点放入桶中(此时,这个结点是放在数组中)
if ((p = tab[i = (n - 1) & hash]) == null) //用&运算代替%运算,提高运算效率,前提是数组长度n需要时2de整数倍,长度的确定由4.1中tableSizeFor确定
tab[i] = newNode(hash, key, value, null); // 桶中已经存在元素 else { Node<K,V> e; K k; // 步骤③:节点key存在,直接覆盖value // 比较桶中第一个元素(数组中的结点)的hash值相等,key相等 if (p.hash == hash && ((k = p.key) == key || (key != null && key.equals(k)))) // 将第一个元素赋值给e,用e来记录 e = p; // 步骤④:判断该链为红黑树 // hash值不相等,即key不相等;为红黑树结点 else if (p instanceof TreeNode) // 放入树中 e = ((TreeNode<K,V>)p).putTreeVal(this, tab, hash, key, value); // 步骤⑤:该链为链表 // 为链表结点 else { // 在链表最末插入结点 for (int binCount = 0; ; ++binCount) { // 到达链表的尾部 if ((e = p.next) == null) { // 在尾部插入新结点 p.next = newNode(hash, key, value, null); // 结点数量达到阈值,转化为红黑树 if (binCount >= TREEIFY_THRESHOLD - 1) // -1 for 1st treeifyBin(tab, hash); // 跳出循环 break; } // 判断链表中结点的key值与插入的元素的key值是否相等 if (e.hash == hash && ((k = e.key) == key || (key != null && key.equals(k)))) // 相等,跳出循环 break; // 用于遍历桶中的链表,与前面的e = p.next组合,可以遍历链表 p = e; } } // 表示在桶中找到key值、hash值与插入元素相等的结点 if (e != null) { // 记录e的value V oldValue = e.value; // onlyIfAbsent为false或者旧值为null if (!onlyIfAbsent || oldValue == null) //用新值替换旧值 e.value = value; // 访问后回调 afterNodeAccess(e); // 返回旧值 return oldValue; } } // 结构性修改 ++modCount; // 步骤⑥:超过最大容量 就扩容 // 实际大小大于阈值则扩容 if (++size > threshold) resize(); // 插入后回调 afterNodeInsertion(evict); return null; }
- 判断键值对数组table[i]是否为空或为null,否则执行resize()进行扩容;
- 根据键值key计算hash值得到插入的数组索引i,如果table[i]==null,直接新建节点添加,转向⑥,如果table[i]不为空,转向③;
- 判断table[i]的首个元素是否和key一样,如果相同直接覆盖value,否则转向④,这里的相同指的是hashCode以及equals;
- 判断table[i] 是否为treeNode,即table[i] 是否是红黑树,如果是红黑树,则直接在树中插入键值对,否则转向⑤;
- 遍历table[i],判断链表长度是否大于8,大于8的话把链表转换为红黑树,在红黑树中执行插入操作,否则进行链表的插入操作;遍历过程中若发现key已经存在直接覆盖value即可;
- 插入成功后,判断实际存在的键值对数量size是否超多了最大容量threshold,如果超过,进行扩容。
4.4 hash算法(计算key的hash值)
/**
* 计算key.hashcode()并将哈希的高位扩展到低位。按照官方的说法,无符号右移是为了让高位参与运算,提高计算的均衡性
*
*/ static final int hash(Object key) {
int h;
return (key == null) ? 0 : (h = key.hashCode()) ^ (h >>> 16);
}
jdk1.8 HashMap源码讲解的更多相关文章
- JDK1.8 HashMap源码分析
一.HashMap概述 在JDK1.8之前,HashMap采用数组+链表实现,即使用链表处理冲突,同一hash值的节点都存储在一个链表里.但是当位于一个桶中的元素较多,即hash值相等的元素较多时 ...
- JDK1.8 HashMap源码
序言 触摸本质才能永垂不朽 HashMap底层是基于散列算法实现,散列算法分为散列再探测和拉链式.HashMap 则使用了拉链式的散列算法,并在JDK 1.8中引入了红黑树优化过长的链表.数据结构示意 ...
- JDK1.7 HashMap 源码分析
概述 HashMap是Java里基本的存储Key.Value的一个数据类型,了解它的内部实现,可以帮我们编写出更高效的Java代码. 本文主要分析JDK1.7中HashMap实现,JDK1.8中的Ha ...
- JDK1.8 HashMap 源码分析
一.概述 以键值对的形式存储,是基于Map接口的实现,可以接收null的键值,不保证有序(比如插入顺序),存储着Entry(hash, key, value, next)对象. 二.示例 public ...
- JDK1.7 hashMap源码分析
了解HashMap原理之前先了解一下几种数据结构: 1.数组:采用一段连续的内存空间来存储数据.对于指定下标的查找,时间复杂度为O(1),对于给定元素的查找,需要遍历整个数据,时间复杂度为O(n).但 ...
- jdk1.8 HashMap源码分析(resize函数)
// 扩容兼初始化 final Node<K, V>[] resize() { Node<K, V>[] oldTab = table; int oldCap = (oldTa ...
- HashMap源码分析(一)
基于JDK1.7 HashMap源码分析 概述 HashMap是存放键值对的集合,数据结构如下: table被称为桶,大小(capacity)始终为2的幂,当发生扩容时,map容量扩大为两倍 Hash ...
- 【JDK1.8】JDK1.8集合源码阅读——HashMap
一.前言 笔者之前看过一篇关于jdk1.8的HashMap源码分析,作者对里面的解读很到位,将代码里关键的地方都说了一遍,值得推荐.笔者也会顺着他的顺序来阅读一遍,除了基础的方法外,添加了其他补充内容 ...
- HashMap源码分析-jdk1.7
注:转载请注明出处!!!!!!!这里咱们看的是JDK1.7版本的HashMap 学习HashMap前先知道熟悉运算符合 *左移 << :就是该数对应二进制码整体左移,左边超出的部分舍弃,右 ...
随机推荐
- Tempdb--Allocation Bottleneck
Alloctaion bottleneck refers to contention in the system pages that store allocation structures. PFS ...
- 10-12Linux流编程的一些知识点
第五章 Linux 的流编程 Linux流操作基础 流和文件的关系:流相当于一个缓冲区,可以将文件描述符和流关联,获得相应的缓冲区,以此来提高系统对磁盘的存取速度. 流的结构和操作 ...
- api接口响应类型定义
public class Response<T> { public ResponseStatus Status { get; set; } public string Message { ...
- DataGridView添加一行数据、全选、取消全选、清空数据、删除选中行
.net 2005下的Windows Form Application,一个DataGridView控件和4个Button,界面设置如下: 代码如下,有注解,相信大家都看得明白: ...
- Winfrom PictureBox 设置图片自适应
初始状态 Bitmap bm = new Bitmap(Image.FromStream(System.Net.WebRequest.Create(new Uri(result.Result)).Ge ...
- Django_Restframwork_序列号组件
第一种序列化方式. 第二种方法通过Model_to_dict方法进行创建 第三种方式序列号组件Serializers: 第四种方法序列化 五.ModelSerializer组件. POST校验 PU ...
- mysql--视图,触发器,事务,存储过程
一.视图 视图是一个虚拟表(非真实存在),是跑到内存中的表,真实表是硬盘上的表,怎么就得到了虚拟表,就是你查询的结果,只不过之前我们查询出来的虚拟表,从内存中取出来显示在屏幕上,内存中就没有了这些表的 ...
- 1083 矩阵取数问题(DP)
1083 矩阵取数问题 基准时间限制:1 秒 空间限制:131072 KB 分值: 5 难度:1级算法题 收藏 关注 一个N*N矩阵中有不同的正整数,经过这个格子,就能获得相应价值的奖励,从左上走 ...
- html中object和embed标签的区别
♦object定义一个嵌入的对象.请使用此元素向您的 XHTML 页面添加多媒体.此元素允许您规定插入 HTML 文档中的对象的数据和参数,以及可用来显示和操作数据的代码. ♦<object&g ...
- python 开发工具IDE pycharm的破解版安装
打开终端 cd /etc 命令行输入 sudo vim hosts 输入mac密码 输入i,进入编辑模式(注意在英文状态下书写) 粘贴0.0.0.0 account.jetbrains.com到文件最 ...