ElasticSearch6.3.2 集群做节点冷(warm) 热(hot) 分离
拿一个小规模的5节点ES集群做冷热分离尝试,它上面已经有60多个索引,有些索引按月、每月生成一个索引,随着数据的不断写入,历史数据(只需保留三个月数据,三个月之前的数据视为历史数据)越来越占磁盘空间和内存资源,影响搜索响应时间。因此想把集群中节点分成2种类型,一种是hot节点,配置大内存和SSD,用来扛平常的用户请求;一种是warm节点,机械硬盘小内存,用来存储历史不常用的数据,和偶尔的后台任务查询。
把现有的5台节点全做hot节点,另外新增2台节点做warm节点。参考官方bloghot-warm-architecture-in-elasticsearch-5-x架构实现。需要注意的地方主要是:不要让已有的索引分片被ES自动Rebalance到warm节点上去了,并且新创建的索引,只应该分配在hot节点上。下面来看具体的实现步骤:
第一步:禁用 rebalance
主要是为了防止集群中已有的索引 rebalance 到 新添加的2台warm节点上去,我们只想手动把那些历史索引 迁移到warm节点上。
PUT _cluster/settings
{
"transient": {
"cluster.routing.allocation.cluster_concurrent_rebalance":0
}
}
第二步:给节点加标识:node.attr.box_type
关于 node.attr.box_type 属性介绍,可参考:enabling-awareness
修改hot节点的elasticsearch.yml配置文件,添加一行:
node.attr.box_type: hot
修改warm节点的elasticsearch.yml配置文件,添加一行:
node.attr.box_type: warm
第三步:定义通用的索引模板保证新创建索引的分片不会分配到warm节点上
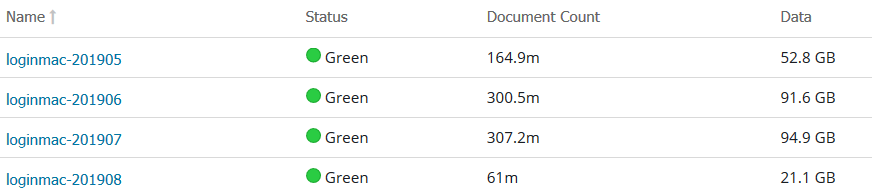
当每月生成一个索引时,新建的索引,肯定是热索引,热索引的分片需要分配到hot节点上,不能分配到warm节点上。比如,loginmac-201908是新建的索引,其分配应该在hot节点上,假设只保留三个月的数据,那么 loginmac-201905就属于历史数据了,需要迁移到warm节点上去。
PUT /_template/hot_template
{
"template": "*",
"order": 0,
"version": 0,
"settings": {
"index": {
"routing": {
"allocation": {
"require": {
"box_type": "hot"
},
"exclude":{
"box_type": "warm"
}
}
},
"number_of_shards": 3,
"number_of_replicas": 1,
"refresh_interval": "50s"
},
"index.unassigned.node_left.delayed_timeout": "3d"
}
}
关于index.routing.allocation.require和index.routing.allocation.exclude可参考:shard-allocation-filtering
第四步 把系统上已有索引的配置全部修改成hot配置
PUT _all/_settings
{
"index": {
"routing": {
"allocation": {
"require": {
"box_type": "hot"
}
}
}
}
}
这是为了,保证当warm节点加入集群时,不要让热索引迁移到到warm节点上。
第五步 重启所有的修改了elasticsearch.yml 配置为 hot 的节点。等待所有的索引初始化完毕
第六步 启动将 elasticsearch.yml 配置为 warm 的节点,并把历史索引数据配置信息修改成 warm
比如 将loginmac-201905索引的配置 改成 box_type 属性改成 warm(将原来的 hot 属性置为null)。(box_type就是用来标识节点属性的)
PUT loginmac-201905/_settings
{
"index": {
"routing": {
"allocation": {
"require": {
"box_type": "warm"
},
"exclude":{
"box_type": null
}
}
}
}
}
第七步 执行reroute命令,将 box_type为warm的索引迁移到 warm节点上。
loginmac-201905 索引box_type设置成warm后,应该会自动 relocating 到 node.attr.box_type为 warm 的标点上。如果没有自动 relocating,那么执行下面的 reroute 命令即可。另外,为了提高 执行 reroute 的效率,可以暂时将 refresh_interval 设置成 -1
其中,node-248是hot节点,node-12是warm节点。
POST /_cluster/reroute
{
"commands": [
{
"move": {
"index": "loginmac-201905",
"shard": 2,
"from_node": "node-248",
"to_node": "node-12"
}
}
]
}
最后,来一张集群冷热节点的示意图:

调整后碰到的一些问题:
在修改 node-02 节点的ES 配置文件时:node.attr.box_type: hot重启后节点并未生效,导致这台节点上的分片全部被迁移到其他节点上去了。因此,修改了配置参数后,可用下面命令先检查一下配置是否生效:
GET /_nodes/node-02
再查看节点信息,可看到节点带有 box_type 为 hot 的属性了。
"attributes": {
"box_type": "hot",
"xpack.installed": "true"
}
所以,在修改了elasticsearch.yml配置文件并重启节点后,最好先GET /_nodes/node-02看一下配置是否生效,否则可能造成大量分片reroute,浪费资源。
另外:还碰到一个重启node-02节点时总是失败的问题:Ubuntu16.04 使用命令:sudo -u user_00 ./bin/elasticsearch -d 一直提示memory not lock 错误(已按官网修改了文件描述符、内存限制等参数)。后来发现使用此种方式 user_00没有足够权限,先用 su user_00 切换到user_00用户,然后再执行 ./bin/elasticsearch -d 启动ES进程。
做完冷热分离后,还可以再做一些其他的优化:
段合并
查看索引loginmac-201905各个段的情况,并force merge
GET /_cat/segments/loginmac-201905?v&h=shard,segment,size,size.memory
POST /loginmac-201905/_forcemerge?max_num_segments=10&flush=true
关闭索引
POST /loginmac-201905/_close
原文:https://www.cnblogs.com/hapjin/p/11314492.html
ElasticSearch6.3.2 集群做节点冷(warm) 热(hot) 分离的更多相关文章
- ES集群Master节点配置问题
ES集群的主节点发现机制采用单播形式,主要配置有三行,如下: discovery.zen.minimum_master_nodes: discovery.zen.ping.multicast.enab ...
- 使用Kubeadm创建k8s集群之节点部署(三十一)
前言 本篇部署教程将讲述k8s集群的节点(master和工作节点)部署,请先按照上一篇教程完成节点的准备.本篇教程中的操作全部使用脚本完成,并且对于某些情况(比如镜像拉取问题)还提供了多种解决方案.不 ...
- redis 集群新增节点,slots槽分配,删除节点, [ERR] Calling MIGRATE ERR Syntax error, try CLIENT (LIST | KILL | GET...
redis reshard 重新分槽(slots) https://github.com/antirez/redis/issues/5029 redis 官方已确认该bug redis 集群重新(re ...
- Elasticsearch-02-入门:集群、节点、分片、索引及常用API
2. 基础入门 2.1 重要概念 2.1.1 集群和节点 1)cluster Elasticsearch集群是由一个或多个节点组成,通过其集群名称来进行唯一标识.节点在搜索到集群之后,通过判断自身的 ...
- Vertica集群单节点宕机恢复方法
Vertica集群单节点宕机恢复方法 第一种方法: 直接通过admintools -> 5 Restart Vertica on Host 第二种方法: 若第一种方法无法恢复,则清空宕机节点的c ...
- 在Linux上使用Nginx为Solr集群做负载均衡
在Linux上使用Nginx为Solr集群做负载均衡 在Linux上搭建solr集群时需要用到负载均衡,但测试环境下没有F5 Big-IP负载均衡交换机可以用,于是先后试了weblogic的proxy ...
- (转)高性能网站架构之缓存篇—Redis集群增删节点
标签: 高性能架构集群缓存redis 上一篇文章,我们搭建了Redis-cluster集群,这篇博客跟大家讲一下如何在一个运行的集群上增加节点或者删除节点. Redis集群添加节点 首先我们要新建立一 ...
- Tomcat集群---Cluster节点配置(转)
<!-- Cluster(集群,族) 节点,如果你要配置tomcat集群,则需要使用此节点. className 表示tomcat集群时,之间相互传递信息使用那个类来实现信息之间的传递. cha ...
- VMware workstation虚拟集群实践(1)—— 配置集群多节点互信
一. 简述 节点互信,是集群管理的基本操作之一.节点互信是通过SSH协议的公钥密钥认证来代替密码认证来实现的.对于单点批量管理多个节点,多个节点之间相互通信来说,配置SSH单方向信任,或者互信十分必要 ...
随机推荐
- 软件设计师14-UML建模
UML图 用例图 用例图:参与者.用例 用例之间的关系:包含关系.扩展关系.泛化关系. 用例的包含关系:查询数据外借信息包含用户登录. 用例的扩展关系:修改之前要先查询,则修改信息包含查询信息用例 类 ...
- nodejs块级作用域
现在让我们了解3个关键字var.let.const,的特性和使用方法. var JavaScript中,我们通常说的作用域是函数作用域,使用var声明的变量,无论是在代码的哪个地方声明的,都会提升到当 ...
- Linux环境oracle导库步骤
1.xshell登录linux 2.切换oracle用户 su - oracle 3.创建directory仓库目录,存放数据库dmp文件 //DIRFILE_zy 表示目录名称 后面的是实际地址 c ...
- 服务器Oracle数据库配置与客户端访问数据库的一系列必要设置
tips:所有路径请对应好自己电脑的具体文件路径. 一.服务器及Oracle数据库设置 1.刚装完的Oracle数据库中只有一个dba账户,首先需要创建一个用户. 2.配置监听,C:\app\Admi ...
- 3.1 Spark概述
一.Spark简介 1.Spark的特点 特点1:运行速度快(内存计算,循环数据流.有向无环图设计机制) 把所有针对数据集的操作转换成一张有向无环图,整个执行引擎调度都是基于这个有向无环图,对这个有向 ...
- 201871010105-曹玉中《面向对象程序设计(java)》第十一周学习总结
201871010105-曹玉中<面向对象程序设计(java)>第十一周学习总结 项目 内容 <面向对象程序设计(java)> https://www.cnblogs.com/ ...
- git push origin master错误
以下错误是因为远程有的文件,本地没有,故而无法push文件到远程 $ git push origin master To git@github.com:AntonioSu/learngitWindow ...
- nginx开启网站目录浏览功能
一.开启全站目录浏览功能 编辑nginx.conf, 在http下面添加以下内容: autoindex on; # 开启目录文件列表 autoindex_exact_size on; # 显示出文件的 ...
- Zookeeper注册中心搭建-单机版(三)
Zookeeper是一个分布式协调组件,本质是一个软件. Zookeeper常用的功能有: 发布订阅功能,把 zookeeper 当作注册中心的原因. 分布式/集群管理功能 Zookeeper是Jav ...
- LeetCode24-Swap_Pairs
swapPairs public ListNode swapPairs(ListNode head) { if(head==null ||head.next==null) return head; L ...