python爬虫1
1 网页结构
html:超文本标记语言------->类似人的鼻子耳朵,长在那里,大体骨架就是那个样子
css:层叠样式表------->这个是外观的深化,比如贴个双眼皮,橙色眼睛。。。
js:动态脚本语言----->人的技能,跳舞rap
学习网站:w3cshool
2 requests使用
(1)开发环境使用pycharm
(2)爬虫基本原理
request---->向服务器发送访问的请求
responce---->服务器收到用户请求以后,会验证请求的有效性然后向用户发送响应的内容。客户端收到响应并显示出来。
(3)get post请求方式
get:
post:
使用有道翻译网页作为案例,http://fanyi.youdao.com/,按F12进入开发者模式,单击network,此时为空。
在输入框中输入"中国你好"单击翻译
单击network---->XHR找到翻译数据
查看请求方式为post,并可以加那个headers中的URL复制出来,因为post需要自己构建请求头
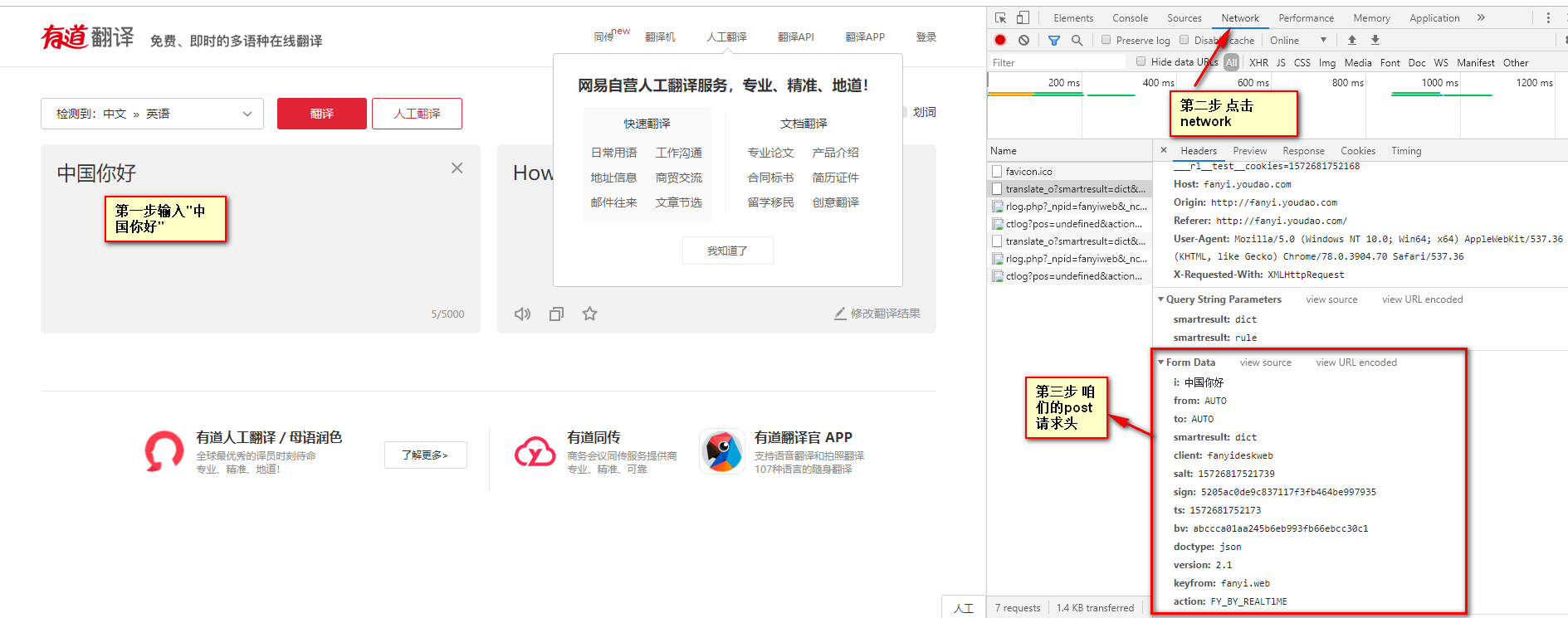
使用request.post抓取有道翻译的结果
import requests
import json
def get_translate_date(word=None):
url='http://fanyi.youdao.com/translate?smartresult=dict&smartresult=rule'
Form_data = {'i':word, 'from':'AUTO','to': 'AUTO','smartresult': 'dict', 'client':'fanyideskweb',
'salt':'','sign':'78181ebbdcb38de9b4a3f4cd1d38816b','doctype':'json',
'version': '2.1','keyfrom':'fanyi.web','action':'FY_BY_CLICKBUTTION','typoResult':'false'} response = requests.post(url, data=Form_data) # 请求表单数据
content = json.loads(response.text) # 将JSON格式字符串转字典
print(content)
print(content['translateResult'][0][0]['tgt']) # 打印翻译后的数据
if __name__ == '__main__':
get_translate_date('中国你好')
3 使用beautiful soup解析网页
通过requests可以抓取网页源码并解析提取数据,beautiful soup被移植到bs4库中,也就是安装它需要先安装bs4.官方中文文档https://beautifulsoup.readthedocs.io/zh_CN/v4.4.0/
(1)打开网页
(2)筛选路径soup.select()
随便选择一句话----->右击检查(右侧弹出开发者界面)----->右击左边高亮数据------>选择copy----->选择copy selector
(3)引入re库
https://docs.python.org/zh-cn/3/library/re.html re中文官网
(4)最终代码
import requests
from bs4 import BeautifulSoup
import re url="http://www.cntour.cn/"
strhtml=requests.get(url)
soup=BeautifulSoup(strhtml.text,'lxml')# 通过lxml解析后转换为树形结构,每个节点都是对象
data=soup.select("#main > div > div.mtop.firstMod.clearfix > div.centerBox > ul.newsList > li > a")
print(data)
for item in data:
result={
'title':item.get_text(),#连接在<a>标签中用get_text
'link':item.get('href'),#在<a>href属性用get
'ID':re.findall('\d+',item.get('href'))#\d表示匹配数字 +表示匹配前一个字符1次或者多次
}
print(result)
(5)最后结果
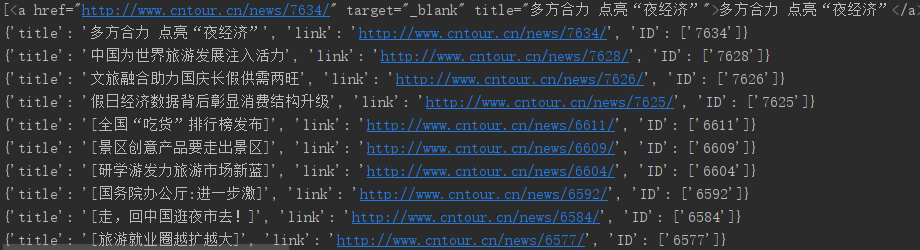
完事!
python爬虫1的更多相关文章
- Python 爬虫模拟登陆知乎
在之前写过一篇使用python爬虫爬取电影天堂资源的博客,重点是如何解析页面和提高爬虫的效率.由于电影天堂上的资源获取权限是所有人都一样的,所以不需要进行登录验证操作,写完那篇文章后又花了些时间研究了 ...
- python爬虫成长之路(一):抓取证券之星的股票数据
获取数据是数据分析中必不可少的一部分,而网络爬虫是是获取数据的一个重要渠道之一.鉴于此,我拾起了Python这把利器,开启了网络爬虫之路. 本篇使用的版本为python3.5,意在抓取证券之星上当天所 ...
- python爬虫学习(7) —— 爬取你的AC代码
上一篇文章中,我们介绍了python爬虫利器--requests,并且拿HDU做了小测试. 这篇文章,我们来爬取一下自己AC的代码. 1 确定ac代码对应的页面 如下图所示,我们一般情况可以通过该顺序 ...
- python爬虫学习(6) —— 神器 Requests
Requests 是使用 Apache2 Licensed 许可证的 HTTP 库.用 Python 编写,真正的为人类着想. Python 标准库中的 urllib2 模块提供了你所需要的大多数 H ...
- 批量下载小说网站上的小说(python爬虫)
随便说点什么 因为在学python,所有自然而然的就掉进了爬虫这个坑里,好吧,主要是因为我觉得爬虫比较酷,才入坑的. 想想看,你可以批量自动的采集互联网上海量的资料数据,是多么令人激动啊! 所以我就被 ...
- python 爬虫(二)
python 爬虫 Advanced HTML Parsing 1. 通过属性查找标签:基本上在每一个网站上都有stylesheets,针对于不同的标签会有不同的css类于之向对应在我们看到的标签可能 ...
- Python 爬虫1——爬虫简述
Python除了可以用来开发Python Web之后,其实还可以用来编写一些爬虫小工具,可能还有人不知道什么是爬虫的. 一.爬虫的定义: 爬虫——网络爬虫(又被称为网页蜘蛛,网络机器人,在FOAF社区 ...
- Python爬虫入门一之综述
大家好哈,最近博主在学习Python,学习期间也遇到一些问题,获得了一些经验,在此将自己的学习系统地整理下来,如果大家有兴趣学习爬虫的话,可以将这些文章作为参考,也欢迎大家一共分享学习经验. Pyth ...
- [python]爬虫学习(一)
要学习Python爬虫,我们要学习的共有以下几点(python2): Python基础知识 Python中urllib和urllib2库的用法 Python正则表达式 Python爬虫框架Scrapy ...
- python爬虫学习(1) —— 从urllib说起
0. 前言 如果你从来没有接触过爬虫,刚开始的时候可能会有些许吃力 因为我不会从头到尾把所有知识点都说一遍,很多文章主要是记录我自己写的一些爬虫 所以建议先学习一下cuiqingcai大神的 Pyth ...
随机推荐
- 《BUG创造队》第六次作业:团队项目系统设计改进与详细设计
项目 内容 这个作业属于哪个课程 2016级软件工程 这个作业的要求在哪里 实验十 团队作业6:团队项目系统设计改进与详细设计 团队名称 BUG创造队 作业学习目标 1.编写完整<软件系统设计说 ...
- BZOJ -3730(动态点分治)
题目:在一片土地上有N个城市,通过N-1条无向边互相连接,形成一棵树的结构,相邻两个城市的距离为1,其中第i个城市的价值为value[i]. 不幸的是,这片土地常常发生地震,并且随着时代的发展,城市的 ...
- Jupyter Notebook(持续更新)
1.引用Pandas import pandas as pd 2.创建DataFrame bb=pd.DataFrame(enron_data) 3.查看列 & 行 dataFrame.sha ...
- vue饿了么UI库-笔记
1. :rules="{required: true, message: '有效期不能为空'}" :rules="{type:'date',required: true, ...
- 4个MySQL优化工具AWR,帮你准确定位数据库瓶颈!(转载)
对于正在运行的mysql,性能如何,参数设置的是否合理,账号设置的是否存在安全隐患,你是否了然于胸呢? 俗话说工欲善其事,必先利其器,定期对你的MYSQL数据库进行一个体检,是保证数据库安全运行的重要 ...
- python 微服务开发书中几个方便的python框架
python 微服务开发是一本讲python 如果进行微服务开发的实战类书籍,里面包含了几个很不错的python 模块,记录下,方便后期回顾学习 处理并发的模块 greenlet && ...
- CSS3 之书页阴影效果
视觉如下: CSS3 之书页阴影效果: <html> <head> <meta charset="UTF-8"> <title>书页 ...
- Programming a robot
题目链接:Gym - 101492H 自己的纯暴力做法: /* */ # include <iostream> # include <cstdio> # include < ...
- 初识es
初识es es是什么? es是基于Apache Lucene的开源分布式(全文)搜索引擎,,提供简单的RESTful API来隐藏Lucene的复杂性. es除了全文搜索引擎之外,还可以这样描述它: ...
- USACO 奶牛抗议 Generic Cow Protests
USACO 奶牛抗议 Generic Cow Protests Description 约翰家的N头奶牛聚集在一起,排成一列,正在进行一项抗议活动.第i头奶牛的理智度 为Ai,Ai可能是负数.约翰希望 ...