flink ETL数据处理
Flink ETL 实现数据清洗

一:需求(针对算法产生的日志数据进行清洗拆分)
1. 算法产生的日志数据是嵌套json格式,需要拆分
2.针对算法中的国家字段进行大区转换
3.最后把不同类型的日志数据分别进行储存
二:整体架构
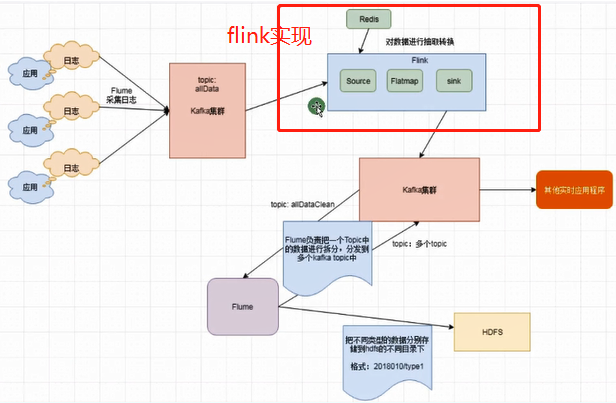
这里演示处理从rabbitmq来的数据 进行数据处理 然后发送到rabbitmq

自定义redistSource flink没有redis的source
package com.yw.source; import org.apache.flink.streaming.api.functions.source.SourceFunction;
import org.slf4j.Logger;
import org.slf4j.LoggerFactory;
import redis.clients.jedis.Jedis;
import redis.clients.jedis.exceptions.JedisConnectionException; import java.util.HashMap;
import java.util.Map; /**
* redis中进行数据初始化
* <p>
* 在reids中保存国家和大区关系
* hset areas AREA_IN IN
* hset areas AREA_US US
* hset areas AREA_CT TW,HK
* hset areas AREA_AR PK,KW,SA
*
*
* @Auther: YW
* @Date: 2019/6/15 10:23
* @Description:
*/
public class MyRedisSource implements SourceFunction<HashMap<String, String>> {
private final Logger LOG = LoggerFactory.getLogger(MyRedisSource.class); private boolean isRuning = true;
private Jedis jedis = null;
private final long SLEEP = 60000;
private final long expire = 60; @Override
public void run(SourceContext<HashMap<String, String>> ctx) throws Exception {
this.jedis = new Jedis("localhost", 6397);
// 存储国家和地区关系
HashMap<String, String> map = new HashMap<>();
while (isRuning) {
try {
map.clear(); // 老数据清除
Map<String, String> areas = jedis.hgetAll("areas");
for (Map.Entry<String, String> entry : areas.entrySet()) {
String key = entry.getKey();
String value = entry.getValue();
String[] splits = value.split(",");
for (String split : splits) {
map.put(split, key);
}
}
if (map.size() > 0) {
// map >0 数据发送出去
ctx.collect(map);
}else {
LOG.warn("获取数据为空!");
}
// 歇6秒
Thread.sleep(SLEEP);
} catch (JedisConnectionException e) {
LOG.error("redis连接异常 重新连接",e.getCause());
// 如果连接异常 重新连接
jedis = new Jedis("localhost", 6397);
}catch (Exception e){
LOG.error("redis Source其他异常",e.getCause());
} }
} @Override
public void cancel() {
isRuning = false;
while (jedis != null) {
jedis.close();
}
}
}
DataClean数据处理
package com.yw; import com.alibaba.fastjson.JSONArray;
import com.alibaba.fastjson.JSONObject;
import com.rabbitmq.client.AMQP;
import com.yw.source.MyRedisSource;
import org.apache.flink.streaming.api.CheckpointingMode;
import org.apache.flink.streaming.api.datastream.DataStream;
import org.apache.flink.streaming.api.datastream.DataStreamSource;
import org.apache.flink.streaming.api.environment.CheckpointConfig;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
import org.apache.flink.streaming.api.functions.co.CoFlatMapFunction;
import org.apache.flink.streaming.connectors.rabbitmq.RMQSink;
import org.apache.flink.streaming.connectors.rabbitmq.RMQSinkPublishOptions;
import org.apache.flink.streaming.connectors.rabbitmq.RMQSource;
import org.apache.flink.streaming.connectors.rabbitmq.common.RMQConnectionConfig;
import org.apache.flink.streaming.util.serialization.SimpleStringSchema;
import org.apache.flink.util.Collector; import java.util.HashMap; /**
* @Auther: YW
* @Date: 2019/6/15 10:09
* @Description:
*/
public class DataClean {
// 队列名
public final static String QUEUE_NAME = "two.aa.in"; public static void main(String[] args) throws Exception {
// 获取环境
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
// 一分钟 checkpoint
env.enableCheckpointing(60000);
env.getCheckpointConfig().setCheckpointingMode(CheckpointingMode.EXACTLY_ONCE);
env.getCheckpointConfig().setMinPauseBetweenCheckpoints(30000); // enableCheckpointing最小间隔时间(一半)
env.getCheckpointConfig().setCheckpointTimeout(10000);// 超时时间
env.getCheckpointConfig().setMaxConcurrentCheckpoints(1);
env.getCheckpointConfig().enableExternalizedCheckpoints(CheckpointConfig.ExternalizedCheckpointCleanup.RETAIN_ON_CANCELLATION); final RMQConnectionConfig rmqConf = new RMQConnectionConfig.Builder().setHost("127.0.0.1").setPort(5672).setVirtualHost("/").setUserName("guest").setPassword("guest").build();
// 获取mq数据
DataStream<String> data1 = env.addSource(new RMQSource<String>(rmqConf, QUEUE_NAME, false, new SimpleStringSchema())).setParallelism(1);
//{"dt":"2019-06-10","countryCode":"US","data":[{"type":"s1","score":0.3,"level":"A"},{"type":"s2","score":0.1,"level":"B"},{"type":"s3","score":0.2,"level":"C"}]}
DataStreamSource<HashMap<String, String>> mapData = env.addSource(new MyRedisSource());
// connect可以连接两个流
DataStream<String> streamOperator = data1.connect(mapData).flatMap(new CoFlatMapFunction<String, HashMap<String, String>, String>() {
// 保存 redis返回数据 国家和大区的映射关系
private HashMap<String, String> allMap = new HashMap<String, String>(); // flatMap1 处理rabbitmq的数据
@Override
public void flatMap1(String value, Collector<String> out) throws Exception {
JSONObject jsonObject = JSONObject.parseObject(value);
String countryCode = jsonObject.getString("countryCode");
String dt = jsonObject.getString("dt");
// 获取大区
String area = allMap.get(countryCode);
JSONArray jsonArray = jsonObject.getJSONArray("data");
for (int i = 0; i < jsonArray.size(); i++) {
JSONObject jsonObject1 = jsonArray.getJSONObject(i);
jsonObject1.put("area", area);
jsonObject1.put("dt", dt);
out.collect(jsonObject1.toJSONString());
}
} // 处理redis的返回的map类型的数据
@Override
public void flatMap2(HashMap<String, String> value, Collector<String> out) throws Exception {
this.allMap = value;
}
});
streamOperator.addSink(new RMQSink<String>(rmqConf, new SimpleStringSchema(), new RMQSinkPublishOptions<String>() {
@Override
public String computeRoutingKey(String s) {
return "CC";
} @Override
public AMQP.BasicProperties computeProperties(String s) {
return null;
} @Override
public String computeExchange(String s) {
return "test.flink.output";
}
}));
data1.print();
env.execute("etl");
}
}
rabbitmq 模拟数据
package com.yw; import com.rabbitmq.client.Channel;
import com.rabbitmq.client.Connection;
import com.rabbitmq.client.ConnectionFactory; import java.text.SimpleDateFormat;
import java.util.Date;
import java.util.Random; /**
* @Auther: YW
* @Date: 2019/6/5 14:57
* @Description:
*/
public class RabbitMQProducerUtil {
public final static String QUEUE_NAME = "two.aa.in"; public static void main(String[] args) throws Exception {
//创建连接工厂
ConnectionFactory factory = new ConnectionFactory(); //设置RabbitMQ相关信息
factory.setHost("127.0.0.1");
factory.setUsername("guest");
factory.setPassword("guest");
factory.setVirtualHost("/");
factory.setPort(5672); //创建一个新的连接
Connection connection = factory.newConnection();
//创建一个通道
Channel channel = connection.createChannel();
// 声明一个队列
// channel.queueDeclare(QUEUE_NAME, false, false, false, null);
//发送消息到队列中
String message = "{\"dt\":\""+getCurrentTime()+"\",\"countryCode\":\""+getCountryCode()+"\"," +
"{\"type\":\""+getType()+"\",\"score\":"+getScore()+"\"level\":\""+getLevel()+"\"}," +
"{\"type\":\""+getType()+"\",\"score\":"+getScore()+"\"level\":\""+getLevel()+"\"}," +
"{\"type\":\""+getType()+"\",\"score\":"+getScore()+"\"level\":\""+getLevel()+"\"}]}"; //我们这里演示发送一千条数据
for (int i = 0; i < 20; i++) {
channel.basicPublish("", QUEUE_NAME, null, (message + i).getBytes("UTF-8"));
System.out.println("Producer Send +'" + message);
} //关闭通道和连接
channel.close();
connection.close();
} public static String getCurrentTime() {
SimpleDateFormat sdf = new SimpleDateFormat("yyyy-MM-dd HH:mm:ss");
return sdf.format(new Date());
} public static String getCountryCode() {
String[] types={"US","TN","HK","PK","KW","SA","IN"};
Random random = new Random();
int i = random.nextInt(types.length);
return types[i];
} public static String getType() {
String[] types={"s1","s2","s3","s4","s5"};
Random random = new Random();
int i = random.nextInt(types.length);
return types[i];
} public static String getScore() {
String[] types={"0.1","0.2","0.3","0.4","0.5"};
Random random = new Random();
int i = random.nextInt(types.length);
return types[i];
}
public static String getLevel() {
String[] types={"A","B","C","D","E"};
Random random = new Random();
int i = random.nextInt(types.length);
return types[i];
}
}
redis 初始化数据
* hset areas AREA_IN IN
* hset areas AREA_US US
* hset areas AREA_CT TW,HK
* hset areas AREA_AR PK,KW,SA

------------最后运行DataClean------------

flink ETL数据处理的更多相关文章
- Spark与Flink大数据处理引擎对比分析!
大数据技术正飞速地发展着,催生出一代又一代快速便捷的大数据处理引擎,无论是Hadoop.Storm,还是后来的Spark.Flink.然而,毕竟没有哪一个框架可以完全支持所有的应用场景,也就说明不可能 ...
- 基于docker构建flink大数据处理平台
https://www.cnblogs.com/1ssqq1lxr/p/10417005.html 由于公司业务需求,需要搭建一套实时处理数据平台,基于多方面调研选择了Flink. 初始化Swarm环 ...
- 基于Broadcast 状态的Flink Etl Demo
接上文: [翻译]The Broadcast State Pattern(广播状态) 最近尝试了一下Flink 的 Broadcase 功能,在Etl,流表关联场景非常适用:一个流数据量大,一个流数据 ...
- Flink学习笔记-新一代Flink计算引擎
说明:本文为<Flink大数据项目实战>学习笔记,想通过视频系统学习Flink这个最火爆的大数据计算框架的同学,推荐学习课程: Flink大数据项目实战:http://t.cn/EJtKh ...
- Flink入门介绍
什么是Flink Apache Flink是一个分布式大数据处理引擎,可以对有限数据流和无限数据流进行有状态计算.可部署在各种集群环境,对各种大小的数据规模进行快速计算. Flink特性 支持高吞吐. ...
- 深度介绍Flink在字节跳动数据流的实践
本文是字节跳动数据平台开发套件团队在1月9日Flink Forward Asia 2021: Flink Forward 峰会上的演讲分享,将着重分享Flink在字节跳动数据流的实践. 字节跳动数据流 ...
- 带你玩转Flink流批一体分布式实时处理引擎
摘要:Apache Flink是为分布式.高性能的流处理应用程序打造的开源流处理框架. 本文分享自华为云社区<[云驻共创]手把手教你玩转Flink流批一体分布式实时处理引擎>,作者: 萌兔 ...
- Flink基础概念入门
Flink 概述 什么是 Flink Apache Apache Flink 是一个开源的流处理框架,应用于分布式.高性能.高可用的数据流应用程序.可以处理有限数据流和无限数据,即能够处理有边界和无边 ...
- ETL的经验总结
ETL的考虑 做数据仓库系统,ETL是关键的一环.说大了,ETL是数据整合解决方案,说小了,就是倒数据的工具.回忆一下工作这么些年来,处理数据迁移.转换的工作倒还真的不少.但是那些工作基 ...
随机推荐
- springcloud - bus
在重新设置了后的bootstrap.yml和application.yml后,可以看到bus-refresh的端点请求了.在之前bootstrap也可以设定哪个端点是可见,哪个未见. 如: #actu ...
- Mongo 安装及基本操作
一. 安装 Mongo文档: https://docs.mongodb.com/v3.6/administration/install-enterprise-linux/ Linux mongo的配置 ...
- THUPC&CTS 2019 游记
day ? 去THU报了个到. day? THUPC比赛日,三个人都没有智商,各种签到题不会做,被各路神仙吊着打.G题还猜了个假结论,做了好久都不对.最后顺利打铁了. 还顺便去看一下THUAC. da ...
- Hadoop 在启动或者停止的时候需要输入yes确认问题
启动或者停止hadoop的时候,信息如下: Stopping namenodes on [hadoop1 hadoop2] The authenticity of host 'hadoop2 (172 ...
- Windows 安装R
下载 R 的安装包 双击 安装包 进行安装 安装完成 测试 修改 R 中的CRAN镜像 添加到 Windows 的环境变量中 测试
- 【Django】Django项目结构与单元测试
学校的软工项目要开发一个网站,自然的想到用python+Django来做.由于之前没有用Django开发过大型的网站项目,所以遇到了一些问题.记录在此,便于以后查阅. 今天完成了项目结构的设计.部分的 ...
- 2019软工实践_Alpha(6/6)
队名:955 组长博客:https://www.cnblogs.com/cclong/p/11913269.html 作业博客:https://edu.cnblogs.com/campus/fzu/S ...
- Python3之logging模块浅析
Python3之logging模块浅析 目录 Python3之logging模块浅析 简单用法 日志与控制台同时输出 一个同时输出到屏幕.文件的完成例子 日志文件截取 日志重复打印问题解决 问题分 ...
- java8新特性一图整理
可以右键在新选项卡打开查看大图 原图地址:https://www.processon.com/view/5abb31abe4b027675e42cebc#map
- SpringBoot使用jasypt加解密密码
在我们的服务中不可避免的需要使用到一些秘钥(数据库.redis等) 开发和测试环境还好,但生产如果采用明文配置讲会有安全问题,jasypt是一个通用的加解密库,我们可以使用它. <depende ...