python_操作linux上的mysql
在编写初期,遇见一个问题,发现怎么连接不上mysql,一直报错1045;
最后发现,只要下面的,连接写正确,不会出现这个问题, 只要你保证你的user、pwd是正确的,
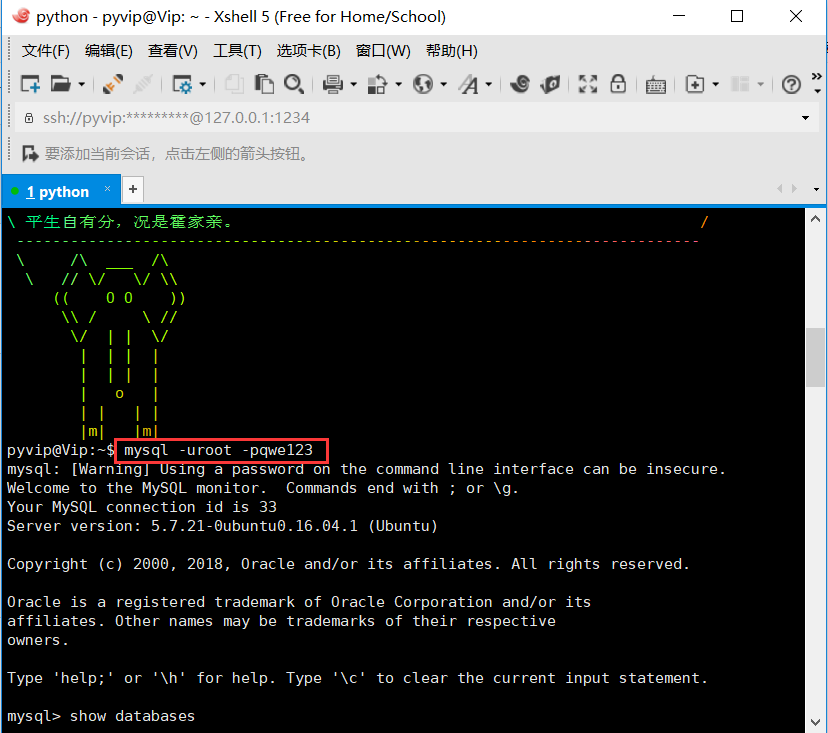
import pymysql
db_config = {
'user': 'root',
'password': 'qwe123',
'db': 'test',
'charset':'utf8'
}
# 连接mysql数据库
con = pymysql.connect(**db_config)
# 创建游标 , 利用游标来执行sql语句
cur = con.cursor()
基本连接是没有问题的。
那我在重复下基本操作命令:
1、建立连接:pymysql.connect(**dbconfig)
连接是不能操作数据库的,需要用连接生成游标来操作
2、创建游标: connection.cursor()
3、执行SQL语句:cursor.execute(sql)
4、获取结果:cur.fetchall()
5、事务的回滚: rollback()
6、事务的提交: commit()
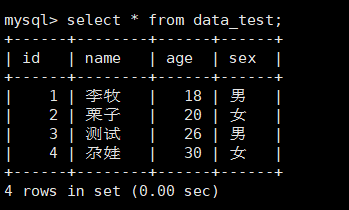
这时,咱们在xshell_mysql 新建一些数据
新建表数据:
CREATE TABLE data_test(
id INT unique,
name VARCHAR(50),
age INT,
sex enum('男','女')
);
表内插入数据:
insert into data_test(id, name, age, sex) VALUES(1, '李牧', 18, '男'),(2, '栗子', 20, '女'),(3, '测试', 26, '男'),(4, '尕娃', 30, '女');
那么在xshell中查询结果如下:
那么我们在pycharm 怎么连接并查询数据呢?
import pymysql def tes_mysql():
db_config = {
'user': 'root',
'password': 'qwe123',
'db': 'test',
'charset':'utf8'
}
# 连接mysql数据库
con = pymysql.connect(**db_config)
# 创建游标 , 利用游标来执行sql语句
cur = con.cursor() try:
# 执行sql语句,不会返回结果,返回其影响的行数
executes = cur.execute("select * from data_test")
# 获取结果
values = cur.fetchall()
for value in values:
print(value) # 提交到数据库,真正把数据插入或者更新到数据
con.commit()
except Exception as e:
print(e)
# 发生了异常,回滚
con.rollback() finally:
# 在最后使用完关闭游标和连接
# 关闭游标
cur.close()
# 关闭连接
con.close()
再进行个参数化把,
定义 test_base.py
import pymysql def tes_mysql(sql):
db_config = {
'user': 'root',
'password': 'qwe123',
'db': 'test',
'charset':'utf8'
}
# 连接mysql数据库
con = pymysql.connect(**db_config)
# 创建游标 , 利用游标来执行sql语句
cur = con.cursor() try:
# 执行sql语句,不会返回结果,返回其影响的行数
executes = cur.execute(sql)
# 获取结果
values = cur.fetchall()
for value in values:
print(value) # 提交到数据库,真正把数据插入或者更新到数据
con.commit()
except Exception as e:
print(e)
# 发生了异常,回滚
con.rollback() finally:
# 在最后使用完关闭游标和连接
# 关闭游标
cur.close()
# 关闭连接
con.close()
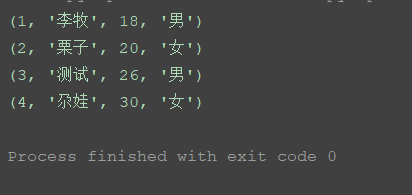
run_select.py
from day.test_base import tes_mysql sql = "select * from data_test"
# 实例化
a = tes_mysql(sql)
运行结果:
简单记录一下。
作者:含笑半步颠√
博客链接:https://www.cnblogs.com/lixy-88428977
声明:本文为博主学习感悟总结,水平有限,如果不当,欢迎指正。如果您认为还不错,欢迎转载。转载与引用请注明作者及出处。
python_操作linux上的mysql的更多相关文章
- 怎样在 Ubuntu Linux 上安装 MySQL
本教程教你如何在基于 Ubuntu 的 Linux 发行版上安装 MySQL.对于首次使用的用户,你将会学习到如何验证你的安装和第一次怎样去连接 MySQL. -- Sergiu MySQL 是一个典 ...
- sqlyog连接Linux上的mysql报错误号码2013,错误号码1130的解决办法
sqlyog连接Linux上的mysql报错误号码2013,错误号码1130的解决办法 1.报错误号码2013,可能是端口号不是默认的3306,需要改成对应的,检查命令是: [root@host et ...
- Linux上通过MySQL命令访问MySQL数据库时常见问题汇总
Linux上通过mysql命令访问MySQL数据库时常见问题汇总 1)创建登录账号 #创建用户并授权 #允许本地访问 create user 'test'@'localhost' identified ...
- 【数据库开发】在Windows上和Linux上配置MySQL的过程
[数据库开发]在Windows上和Linux上配置MySQL的过程 标签(空格分隔): [编程开发] 首先是在Windows上尝试用QT进行MySQL数据库开发,结果总出现driver不能load的错 ...
- linux上安装 mysql
一.linux 上安装 mysql 1.查看mysql是否安装 rpm -qa|grep mysql 2.卸载 mysql yum remove mysql mysql-server mysql-li ...
- Linux上安装mysql,实现主从复制
MYSQL(mariadb) MariaDB数据库管理系统是MySQL的一个分支,主要由开源社区在维护,采用GPL授权许可.开发这个分支的原因之一是:甲骨文公司收购了MySQL后,有将MySQL闭源的 ...
- Linux 上从 MySQL 迁移到 MariaDB 的简单步骤
大家好!这是一篇介绍如何在服务器或个人电脑上从MySQL迁移到MariaDB的教程.也许你会问为什么我们要将数据库管理从MySQL迁移到MariaDB.往下看我们告诉你为什么这样做.为什么要用Mari ...
- linux上安装mysql,tomcat,jdk
Linux 上安装 1 安装jdk 检测是否安装了jdk 运行 java –version 若有 需要将其卸载 a) 查看安装哪些jdk rmp –qa |grep java b) ...
- linux上,mysql使用聚合函数group by 时报错:SELECT list is not in GROUP BY clause and contains nonaggre的问题
之前在windows上测试是可以正常使用的,但是上传到Linux上后,就报错: Expression # of SELECT list is not in GROUP BY clause and co ...
随机推荐
- Internet地址结构
IP地址结构及分类寻址 IP地址 = <网络号> + <主机号> ------------IPv4(32bit)点分四组表示法: 192.168.31.1 ...
- 分析WordPress数据表之用户表(功能篇)
数据表分析 wp_users wp_usermeta 用户系统就是靠着这两张表来实现的. 具体事例分析 添加用户 添加成功后,我们会分别在wp_users及wp_usermeta表中分别看到test0 ...
- vue中使用时间插件、vue使用laydate
<input id="time1" readonly="readonly" placeholder="这里选择时间" v-model= ...
- clickhouse 19.14.m.n简单测试
ClickHouse is a column-oriented database management system (DBMS) for online analytical processing o ...
- mac 下面用dd 制作u盘启动
用dd来把安装包烧到U盘的,发现U盘变小了,mac磁盘工具也不能格式化,就只好用命令行了.diskutil list #1.找到U盘的代号 比如disk1diskutil unmountDisk /d ...
- HTML a标签链接 设置点击下载文件
通常情况下,为文件添加链接后,用户可以通过点击链接,直接将文件下载到本地,如下载 excel 表格等 <a href="/user/test/xxxx.excel">点 ...
- 什么时候会进行 SpringMVC重定向保存参数(FlashMap)?
SpringMVC重定向保存参数(FlashMap):两种情况会保存参数: 1. 当前视图为RedirectView,也即是说当前请求为重定向请求. org.springframe ...
- 【C#】使用C# 读取Http的Post数据
private string Post(string num) { Encoding myEncoding = Encoding.GetEncoding("gb2312"); // ...
- wms证书异常问题
目前我司已定位到两个原因,详细如下, 1. 快速生成的证书存在问题,导致APACHE和NGINX显示的时间都是4号凌晨 2. 贵司在配置完成162和163两台应用的APACHE证书,以及其中10. ...
- 梳理数据库(MySQL)的主要知识点
一.数据库类型 常用的关系型数据库 Oracle:功能强大,主要缺点就是贵 MySQL:互联网行业中最流行的数据库,免费.关系数据库场景中的功能 MySQL 都能很好的满足 MariaDB:MySQL ...