扯扯淡,写个更快的memcpy
写代码有时候和笃信宗教一样,一旦信仰崩溃,是最难受的事情。早年我读过云风的一篇《VC 对 memcpy 的优化》,以及《Efficiency geek 2: copying data in C/C++, optimisation》,所以我是坚信很难能写出比C运行时库更快的memcpy的。但最近有两个事情,让我对这个坚信产生了怀疑。
第一个个是最近在看lz4的代码,lz4可能是目前最快的内存压缩算法,部分评测他比snappy还要快点(lz4的实现后面专文剖析)。研究他的代码,发现他其中有个重要的和其他代码不同地方就是他的内存拷贝采用的是一个宏,而不是使用memcpy。其内部直接使用uint64_t转换指针进行拷贝赋值,个人估计这是他加快处理速度的一个地方。其拷贝代码大意如下,其实现不在乎字长溢出的部分。
//你要保证dst有足够的空间,其要求空间很可能比sz大,都是8字节补齐的。
#define ZEN_TEST_FAST_COPY(dst,src,sz) {\
char *_cpy_dst = dst; \
const char *_cpy_src = src; \
size_t _cpy_size = sz;\
do \
{ \
ZBYTE_TO_UINT64(_cpy_dst) = ZBYTE_TO_UINT64(_cpy_src); \
_cpy_dst += sizeof(uint64_t); \
_cpy_src += sizeof(uint64_t); \
}while( _cpy_size > sizeof(uint64_t) && (_cpy_size -= sizeof(uint64_t))); \
}
第二个是看了一篇文章《哪个memcpy更快?》。发现里面说Linux标准库的memcpy比较不堪。这个有点颠覆了。原文代码有个问题是,其在最开始对非取整的部分进行了操作。但如果memcpy的dst,src参数地址是对齐的,这样明显不利于加快速度。我改进的代码如下:
void *ZEN_OS::fast_memcpy(void *dst, const void *src, size_t sz)
{
void *r = dst; //先进行uint64_t长度的拷贝,一般而言,内存地址都是对齐的,
size_t n = sz & ~(sizeof(uint64_t) - );
uint64_t *src_u64 = (uint64_t *) src;
uint64_t *dst_u64 = (uint64_t *) dst; while (n)
{
*dst_u64++ = *src_u64++;
n -= sizeof(uint64_t);
} //将没有非8字节字长取整的部分copy
n = sz & (sizeof(uint64_t) - );
uint8_t *src_u8 = (uint8_t *) src;
uint8_t *dst_u8 = (uint8_t *) dst;
while (n-- )
{
(*dst_u8++ = *src_u8++);
} return r;
}
文章代码里面还有个一个类似函数,区别在于,其在每次循环拷贝了2次uint64_t字长的数据。为了行文方便我们称之为fast_memcpy[2]把。
while (n)
{
*dst_u64++ = *src_u64++;
*dst_u64++ = *src_u64++;
n -= sizeof(uint64_t)*;
}
为了搞明白到底如何,只有自己测试一下。测试拷贝了8,16……64K,1M,4M字节的数据。在LINUX 64 (GCC 4.3 O3优化),Windows7 X64(Visual 2010 realse),Windwos7 win32(realse)的环境进行了测试,测试采用高精度定时器采集数据。。
第一组测试以字节对齐数据进行,无聊的数据就不贴了,直接上图。如果把最慢的速度比作100%,其他人作为和他的相对比率绘制图片,线条一直在下面的肯定更好一些:
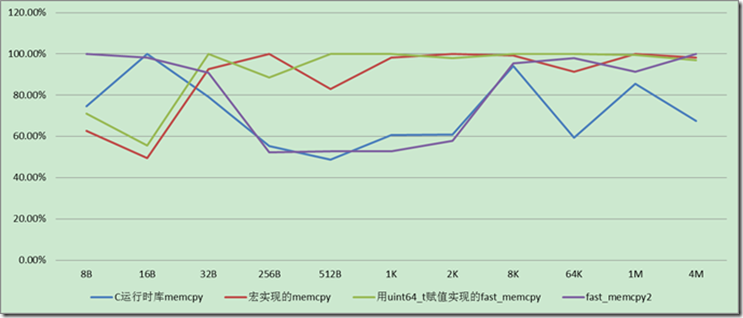
Linux 64位下(GCC 4.3 O3优化),字节对齐情况下拷贝速度对比,如下图,
Windows7 X64,Visaul C++ 2010 Realse, 字节对齐情况下拷贝速度,如下图
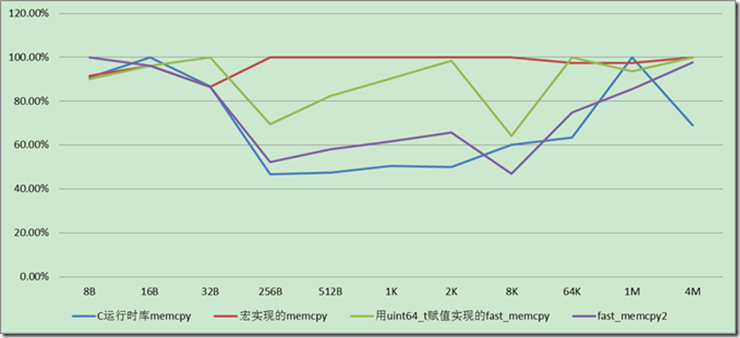
看上面的比较图片就会知道memcpy在对齐清下,memcpy在任何时候都是不错的选择。
但内存拷贝还有另外一种常见情况,就是字节无法对齐的情况,而lz4作为一个压缩算法,可能恰恰要经常面对无法对齐的情况,所以我针对这种情况也做了一下测试。
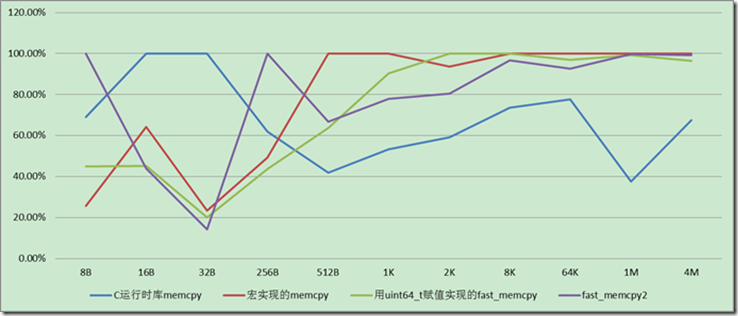
Linux 64位下(GCC 4.3 O3优化),字节非对齐情况下拷贝速度,如下图,
Windows7 X64,Visaul C++ 2010 Realse, 字节非对齐情况下拷贝速度,如下图,宏的拷贝
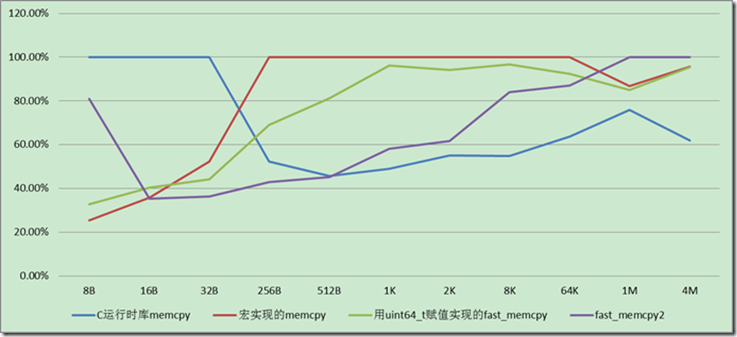
在字节不对齐的情况下,并且拷贝的内存长度小于256字节,用8字节的赋值方式速度会稍微优于memcpy,这可能也是lz4采用这个方法的原因。如果拷贝的尺寸更大的不对齐时,memcpy还是更好的选择。而考虑到lz4大部分情况面对的拷贝字节,应该小于256字节。所以他采用宏拷贝的方式理论上是可以获得一些优势。
结论:
在字节对齐的情况下,memcpy在任何时候几乎都是最优的选择。
确实有些方法在特定条件下比memcpy快一点。但如果你不知道如何选择,默认还是选择memcpy为好。同理也适应memset函数。
Windows 平台上,如果数据长度达到1M或者4M,Windows的下的表现要好于Linxu平台,特别是在64位的平台上。(当然Linux测试环境是虚拟机,是否有一定影响?),可能的原因为止,和frostburn掰扯估计Windows下指令优化也许有过GCC之处。
写出比运行时库memcpy更快函数,这本身就是一个比较扯淡的事情,你的对手有编译器优化,代码运行优化,指令优化等多种手段。《哪个memcpy更快?》一文应该是有缪误的。当然他可能有他的背景(没有开优化?),作者可能并没有说清。
参考文档以及背景阅读:
《VC 对 memcpy 的优化》 云风解释的VC对于各种拷贝长度,编译器做的优化。
《Efficiency geek 2: copying data in C/C++, optimisation》作者对一些Geek的方法做了评估,当然第一篇memset部分写的更为详细一些。有些Geek作法大家可以看看。《各种版本的memcpy(底层优化)》一问解释一些数据拷贝的优化方法。《Optimizing Memcpy improves speed》这个里面提到的memcpy也不是我们所说的C运行时库的memcpy,但此文也解释了一些的提速数据拷贝方法。
《哪个memcpy更快?》误导我的文章,我认为他所述的东东应该有个特殊场景。或者他说的C库的memcpy和我理解就不是一个东东?
《C/C++ tip: How to copy memory quickly》文章也说明了这个问题,他的结论和我们一样。
【本文作者是雁渡寒潭,本着自由的精神,你可以在无盈利的情况完整转载此文 档,转载时请附上BLOG链接:http://www.cnblogs.com/fullsail/,否则每字一元,每图一百不讲价。对Baidu文库和360doc加价一倍】
扯扯淡,写个更快的memcpy的更多相关文章
- 更快的memcpy
更快的memcpy 写代码有时候和笃信宗教一样,一旦信仰崩溃,是最难受的事情.早年我读过云风的一篇<VC 对 memcpy 的优化>,以及<Efficiency geek 2: co ...
- 面试官:如何写出让 CPU 跑得更快的代码?
前言 代码都是由 CPU 跑起来的,我们代码写的好与坏就决定了 CPU 的执行效率,特别是在编写计算密集型的程序,更要注重 CPU 的执行效率,否则将会大大影响系统性能. CPU 内部嵌入了 CPU ...
- 【面向对象】用大白话扯扯那"神奇"的面向对象编程思维(二)
前言: 上一章我们用大白话讲解了一下面向对象的编程思维,那么这一张我们来讲讲如何用面向对象来书写代码.终于到了激动人心的时刻了..... 传送门:https://www.cnblogs.com/sy1 ...
- php提供更快的文件下载
在微博上偶然看到一篇介绍php更快下载文件的方法,其实就是利用web服务器的xsendfile特性,鸟哥的博客中只说了apache的实现方式,我找到了介绍nginx实现方式的文章,整理一下! let' ...
- ClownFish:比手写代码还快的通用数据访问层
http://www.cnblogs.com/fish-li/archive/2012/07/17/ClownFish.html 阅读目录 开始 ClownFish是什么? 比手写代码还快的执行速度 ...
- CSS VS JS动画,哪个更快[译]
英文原文:https://davidwalsh.name/css-js-animation 原作者Julian Shapiro是Velocity.js的作者,Velocity.js是一个高效易用的js ...
- 更快学习 JavaScript 的 6 个思维技巧
更快学习 JavaScript 的 6 个思维技巧 我们在学习JavaScript,或其他任何编码技能的时候,往往是因为这些拦路虎而裹足不前: 有些概念可能会造成混淆,尤其当你是从其他语言转过来的时候 ...
- 新型序列化类库MessagePack,比JSON更快、更小的格式
MessagePack is an efficient binary serialization format. It lets you exchange data among multiple la ...
- mysql DB server端,如何让读写更快
其实,我不是专业的DB管理同学,甚至算不上会了解.只是在最近的工作中,遇到了DB server端优化的契机,所以把这些手段记录下来: 通过调整这个参数的值,可以让DB更给力: 这两个参数的含义: 1. ...
随机推荐
- C++: std::string 与 Unicode 如何结合?
关键字:std::string Unicode 转自:http://www.vckbase.com/document/viewdoc/?id=1293 一旦知道 TCHAR 和_T 是如何工作的,那么 ...
- Binding to the Most Recent Visual Studio Libraries--说的很详细,很清楚
Every version of Visual Studio comes with certain versions of the Microsoft libraries, such as the C ...
- 什么是 .manifest 文件
恩,为了大家都能很方便的理解,我将尽量简单通俗地进行描述. [现象]对这个问题的研究是起源于这么一个现象:当你用VC++2005(或者其它.NET)写程序后,在自己的计算机上能毫无问题地运行,但是当把 ...
- HDU 2159 FATE (DP 二维费用背包)
题目链接 题意 : 中文题不详述. 思路 : 二维背包,dp[i][h]表示当前忍耐值为i的情况下,杀了h个怪得到的最大经验值,状态转移方程: dp[i][h] = max(dp[i][h],dp[i ...
- ArcGIS学习记录—dbf shp shx sbn sbx mdb adf等类型的文件的解释
原文地址: ArcGIS问题:dbf shp shx sbn sbx mdb adf等类型的文件的解释 - Silent Dawn的日志 - 网易博客 http://gisman.blog.163.c ...
- vs 下 opengl 配置问题
项目 -->选择属性 C\C++-->preprocessor-->preprocessor definition 添加GLUT_BUILDING_LIB,中间用分号隔开. 然后点击 ...
- git rebase无法处理的问题
在进行代码整理的时候,遇到了冲突 现在chucklu_master分支指向这个commit SHA-1: 88fa1ee9263402626d85b5a4362e1b620935953f * remo ...
- Android开发之Bitmap.Config.RGB_565
在学习xutils框架的时候,看到sample代码中有一行这样的代码: bitmapUtils.configDefaultBitmapConfig(Bitmap.Config.RGB_565); Bi ...
- windows编译 obs-studio
github下载源码 https://github.com/jp9000/obs-studio 还需要一个开发包 http://code.fosshub.com/OBS/download/depend ...
- UVa 1572 (拓扑排序) Self-Assembly
题意: 有n种正放形,每种正方形的数量可视为无限多.已知边与边之间的结合规则,而且正方形可以任意旋转和反转,问这n中正方形是否可以拼成无限大的图案. 分析: 首先因为可以旋转和反转,所以可以保证在拼接 ...