[系统集成] 部署 mesos-exporter 和 prometheus 监控 mesos task
前几天我在mesos平台上基于 cadvisor部署了 influxdb 和 grafana,用于监控 mesos 以及 docker app 运行信息,发现这套监控系统不太适合 mesos + docker 的架构,原因是:
1)mesos task id 和 docker container name 不一致
cadvisor 的设计基于 docker host,没有考虑到mesos 数据中心;
cadvisor 用 docker name(docker ps能看到)来标记抓取的数据,而 mesos 用 task id(在mesos ui 或者metrics里能看到) 来标记正在运行的任务。mesos task 的类型可以是 docker 容器,也可以是非容器。mesos task id 与docker container name 的命名也是完全不一样的。
上述问题导致 cadvisor 抓取到数据后,用户难以识别属于哪个 mesos task
2)cadvisor 和 grafana 不支持报警
经过查询资料,发现 mesos-exporter + prometheus + alert-manager 是个很好的组合,可以解决上述问题:
mesos-exporter 是 mesosphere 开发的工具,用于导出 mesos 集群包括 task 的监控数据并传递给prometheus;prometheus是个集 db、graph、statistic 于一体的监控工具;alert-manager 是 prometheus 的报警工具
搭建方法:
1. build mesos-exporter
git clone https://github.com/mesosphere/mesos_exporter.git
cd mesos_exporter
docker build -f Dockerfile -t mesosphere/mesos-exporter .
2. docker pull prometheus, alert-manager
3. 部署 mesos-exporter, alert-manager, prometheus
mesos-exporter:
{
"id": "mesos-exporter-slave",
"instances": 6,
"cpus": 0.2,
"mem": 128,
"args": [
"-slave=http://127.0.0.1:5051",
"-timeout=5s"
],
"constraints": [
["hostname","UNIQUE"],
["hostname", "LIKE", "slave[1-6]"]
],
"container": {
"type": "DOCKER",
"docker": {
"image": "172.31.17.36:5000/mesos-exporter:latest",
"network": "HOST"
},
"volumes": [
{
"containerPath": "/etc/localtime",
"hostPath": "/etc/localtime",
"mode": "RO"
}
]
}
}
请打开slave 防火墙的9110/tcp 端口
alert-manager:
{
"id": "alertmanager",
"instances": 1,
"cpus": 0.5,
"mem": 128,
"constraints": [
["hostname","UNIQUE"],
["hostname", "LIKE", "slave[1-6]"]
],
"labels": {
"HAPROXY_GROUP":"external",
"HAPROXY_0_VHOST":"alertmanager.test.com"
},
"container": {
"type": "DOCKER",
"docker": {
"image": "172.31.17.36:5000/alertmanager:latest",
"network": "BRIDGE",
"portMappings": [
{ "containerPort": 9093, "hostPort": 0, "servicePort": 0, "protocol": "tcp" }
]
},
"volumes": [
{
"containerPath": "/etc/localtime",
"hostPath": "/etc/localtime",
"mode": "RO"
},
{
"containerPath": "/etc/alertmanager/config.yml",
"hostPath": "/var/nfsshare/alertmanager/config.yml",
"mode": "RO"
},
{
"containerPath": "/alertmanager",
"hostPath": "/var/nfsshare/alertmanager/data",
"mode": "RW"
}
]
}
}
prometheus:
{
"id": "prometheus",
"instances": 1,
"cpus": 0.5,
"mem": 128,
"args": [
"-config.file=/etc/prometheus/prometheus.yml",
"-storage.local.path=/prometheus",
"-web.console.libraries=/etc/prometheus/console_libraries",
"-web.console.templates=/etc/prometheus/consoles",
"-alertmanager.url=http://alertmanager.test.com"
],
"constraints": [
["hostname","UNIQUE"],
["hostname", "LIKE", "slave[1-6]"]
],
"labels": {
"HAPROXY_GROUP":"external",
"HAPROXY_0_VHOST":"prometheus.test.com"
},
"container": {
"type": "DOCKER",
"docker": {
"image": "172.31.17.36:5000/prometheus:latest",
"network": "BRIDGE",
"portMappings": [
{ "containerPort": 9090, "hostPort": 0, "servicePort": 0, "protocol": "tcp" }
]
},
"volumes": [
{
"containerPath": "/etc/localtime",
"hostPath": "/etc/localtime",
"mode": "RO"
},
{
"containerPath": "/etc/prometheus",
"hostPath": "/var/nfsshare/prometheus/conf",
"mode": "RO"
},
{
"containerPath": "/prometheus",
"hostPath": "/var/nfsshare/prometheus/data",
"mode": "RW"
}
]
}
}
4. prometheus 配置
prometheus.yml
# my global config
global:
scrape_interval: 15s # By default, scrape targets every 15 seconds.
evaluation_interval: 15s # By default, scrape targets every 15 seconds.
# scrape_timeout is set to the global default (10s). # Attach these labels to any time series or alerts when communicating with
# external systems (federation, remote storage, Alertmanager).
external_labels:
monitor: 'codelab-monitor' # Load and evaluate rules in this file every 'evaluation_interval' seconds.
rule_files:
# - "first.rules"
# - "second.rules" scrape_configs:
- job_name: 'mesos-slaves'
scrape_interval: 5s
metrics_path: '/metrics'
scheme: 'http'
target_groups:
- targets: ['172.31.17.31:9110', '172.31.17.32:9110', '172.31.17.33:9110', '172.31.17.34:9110', '172.31.17.35:9110', '172.31.17.36:9110']
- labels:
group: 'office'
待补充 ...
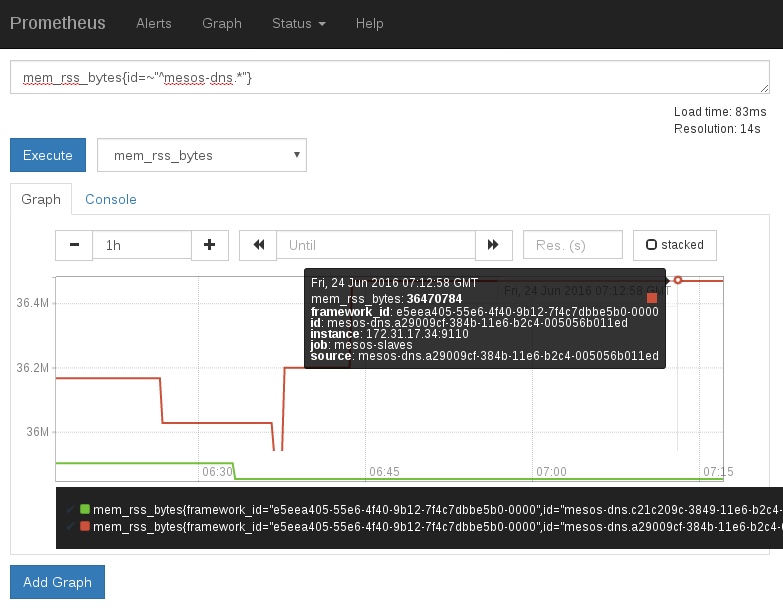
5. 报警设置
待补充 ...
6. 与 grafana 集成
prometheus的 graph 功能不太完善,可以与 grafana 集成,让 grafana 承担 graph 功能。
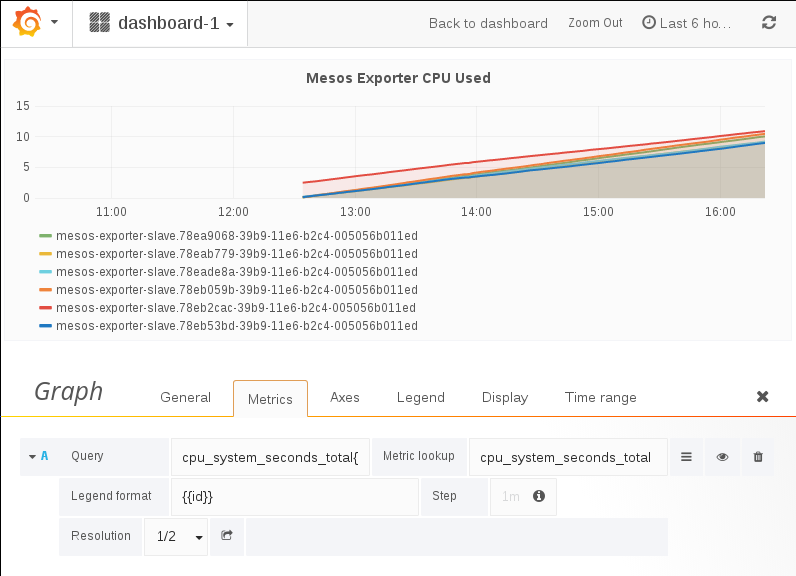
data source 设置:

7. 附:mesos metrics 和 statics 地址
http://master1:5050/metrics/snapshot
http://slave4:5051/metrics/snapshot
http://master1:5050/master/state.json
http://slave4:5051/monitor/statistics.json
用户可以基于上述页面的数据,编写自己的监控程序。
[系统集成] 部署 mesos-exporter 和 prometheus 监控 mesos task的更多相关文章
- 部署prometheus监控kubernetes集群并存储到ceph
简介 Prometheus 最初是 SoundCloud 构建的开源系统监控和报警工具,是一个独立的开源项目,于2016年加入了 CNCF 基金会,作为继 Kubernetes 之后的第二个托管项目. ...
- Prometheus监控软件部署方法
背景:负责基于区块链的某公正项目的状态上报模块设计编码,基于Prometheus进行二次开发 1.说明Prometheus 是一个开源的服务监控软件,它通过 HTTP 协议从远程机器收集数据并存储在本 ...
- Kubernetes集群部署史上最详细(二)Prometheus监控Kubernetes集群
使用Prometheus监控Kubernetes集群 监控方面Grafana采用YUM安装通过服务形式运行,部署在Master上,而Prometheus则通过POD运行,Grafana通过使用Prom ...
- 使用 Docker 部署 Grafana + Prometheus 监控 MySQL 数据库
一.背景 在平时开发过程当中需要针对 MySQL 数据库进行监控,这里我们可以使用 Grafana 和 Prometheus 来实现监控功能.Grafana 是一款功能强大的仪表盘面板,支持多种数据源 ...
- 基于k8s集群部署prometheus监控ingress nginx
目录 基于k8s集群部署prometheus监控ingress nginx 1.背景和环境概述 2.修改prometheus配置 3.检查是否生效 4.配置grafana图形 基于k8s集群部署pro ...
- 基于k8s集群部署prometheus监控etcd
目录 基于k8s集群部署prometheus监控etcd 1.背景和环境概述 2.修改prometheus配置 3.检查是否生效 4.配置grafana图形 基于k8s集群部署prometheus监控 ...
- 容器编排系统K8s之Prometheus监控系统+Grafana部署
前文我们聊到了k8s的apiservice资源结合自定义apiserver扩展原生apiserver功能的相关话题,回顾请参考:https://www.cnblogs.com/qiuhom-1874/ ...
- 如何利用Prometheus监控你的应用
Prometheus作为一套完整的开源监控接近方案,因为其诸多强大的特性以及生态的开放性,俨然已经成为了监控领域的事实标准并在全球范围内得到了广泛的部署应用.那么应该如何利用Prometheus对我们 ...
- 如何利用Prometheus监控你的应用(此列子是对于golang sdk进行运用)
Prometheus作为一套完整的开源监控接近方案,因为其诸多强大的特性以及生态的开放性,俨然已经成为了监控领域的事实标准并在全球范围内得到了广泛的部署应用.那么应该如何利用Prometheus对我们 ...
随机推荐
- CentOS下查看进程和删除进程
1. 在 LINUX 命令平台输入 1-2 个字符后按 Tab 键会自动补全后面的部分(前提是要有这个东西,例如在装了 tomcat 的前提下, 输入 tomcat 的 to 按 tab).2. ps ...
- mongodb C# 驱动查询
INoSqlProvider provider = NoSqlManager.Create("CloudTable"); IMongoCollection<FormMongo ...
- 观 GT Java语言管理系统的感悟
继上次java系统考核完... 坦白说,我对我自己写的例子还是很满意的,虽说学长们给的评价不高 ,但我一直以为是学长们对我们的要求太高,以他们的眼光在看待我们,所以我对学长们给的评价并没有太过在意,当 ...
- Surprise团队第一周项目总结
Surprise团队第一周项目总结 团队项目 基本内容 五子棋(Gobang)的开发与应用 利用Android Studio设计一款五子棋游戏,并丰富其内涵 预期目标 实现人人模式:2个用户可以在同一 ...
- bootstrap-16
进度条----基本样式: Bootstrap框架中对于进度条提供了一个基本的样式,一个100%宽度的背景色,然后高亮颜色表示完成进度.其实制作这样的进度条非常容易,一般是使用两个容器,外容器具有一定的 ...
- HttpURlconntiuon获取网络数据
package Network; import java.io.BufferedReader;import java.io.IOException;import java.io.InputStream ...
- 苹果Xcode 证书生成、设置、应用完整图文教程
Xcode 证书生成.设置.应用,与大家分享. 为了能够在iPhone或iPod Touch上运行iPhone应用程序,必须使用有效的数字证书签名.这个证书用于将您的开发者身份与在注册期间所提供的已确 ...
- C++ 开篇
C++ 程序员历练之路 1.C++ primer 2.C++程序设计语言 C++之父的作品 3.C++标准库 STL 4.TCP/IP协议详解 共3卷 5.Oracle数据库和MySQl数据库的学习 ...
- rabbitmq 重复ACK导致消息丢失
rabbitmq 重复确认导致消息丢失 背景 rabbitmq 在应用场景中,大多采用工作队列 work-queue的模式. 在一个常见的工作队列模式中,消费者 worker 将不断的轮询从队列中拉取 ...
- Java-接口和抽象类区别
在类的设计中,需要明确一个原则,一个类不要去继承一个已经实现好的类,只能继承抽象类或实现接口,如果接口和抽象类都可以使用,那么优先使用接口,避免继承局限