sql server 小记——分区表(上)
我们知道很多事情都存在一个分治的思想,同样的道理我们也可以用到数据表上,当一个表很大很大的时候,我们就会想到将表拆
分成很多小表,查询的时候就到各个小表去查,最后进行汇总返回给调用方来加速我们的查询速度,当然切分可以使用横向切分,纵向
切分,比如我们最熟悉的订单表,通常会将三个月以外的订单放到历史订单表中,这里的三个月就是将订单表进行切分的依据。
好了,分区表的好处我想大家都很清楚了,下面我们看看如何实现。
一:分区表
这里我们做个例子,创建一个test数据库,表名为shop,以createtime作为分区依据。
1:确定分区依据
怎么分区的话,这个要看具体业务逻辑了,你可以按照时间,地区,求模等等都可以。
2:创建文件组
既然是文件组,肯定是对文件进行分类管理的,默认情况下就一个mdf和ldf文件,当所有的数据都挤压在mdf上,确实不是一个
很好的事情,降低我们的查询速度,当用到文件组的时候就可以创建多个ndf来分摊mdf中的数据,甚至还可以将ndf分摊到几个磁盘
上,充分利用服务器多核处理能力,说了这么多,我们看看sql语句咋搞,这里我创建四个文件组,分别存放2013之前,2013,2014
和2014年之后的数据。
alter database Test add filegroup Before2013
alter database Test add filegroup T2013
alter database Test add filegroup T2014
alter database Test add filegroup After2014
3:创建文件
根据上面在文件组上的概述,文件的作用大家都知道了,这里我们要做的是,将次文件.ndf附加到文件组上,因为我创建了4个文件组,
所以我也创建4个文件分别存放在这4个文件组中。
alter database Test add file
(Name=N'Before2013',filename='D:\Program Files\Microsoft SQL Server\MSSQL10.MSSQLSERVER\MSSQL\DATA\Before20131.ndf',size=5mb,maxsize=100Mb,filegrowth=5mb)
to filegroup Before2013
alter database Test add file
(Name=N'T2013',filename='D:\Program Files\Microsoft SQL Server\MSSQL10.MSSQLSERVER\MSSQL\DATA\T20131.ndf',size=5mb,maxsize=100Mb,filegrowth=5mb)
to filegroup T2013
alter database Test add file
(Name=N'T2014',filename='D:\Program Files\Microsoft SQL Server\MSSQL10.MSSQLSERVER\MSSQL\DATA\T20141.ndf',size=5mb,maxsize=100Mb,filegrowth=5mb)
to filegroup T2014
alter database Test add file
(Name=N'After2014',filename='D:\Program Files\Microsoft SQL Server\MSSQL10.MSSQLSERVER\MSSQL\DATA\After20141.ndf',size=5mb,maxsize=100Mb,filegrowth=5mb)
to filegroup After2014
4:编写分区函数
刚才也说了,我们是按照时间进行切分的,将数据表数据分成:
① 2013年之前
② 2013-2014
③ 2014-2015
④ 2015之后
既然都知道依据了,我们分区函数也方便写了。
create partition function RangeTime (datetime)
as range left for values ('2012-12-31','2013-12-31','2014-12-31')
从上面的sql,我们可以看到三个点将时间轴分成了4段
第一:rangeTime 为分组函数名。
第二:left 其实就是当时间点在边界时到底属于左侧还是右侧,因为这里是left,所以属于左侧,如果是right关键词,那就属于右侧了。
5:编写分区方案
分区方案也就是将分区函数与文件组进行一个关联,刚才也说了,3个时间点将一个时间轴分成了4部分,刚好对应了4个文件组。
那么具体的sql写法如下:
create partition scheme RangeSchema_CreateTime
as partition RangeTime
to (before2013,T2013,T2014,after2014)
6:创建分区表
跟普通表创建有点不一样,分区表的创建还需要指定这个分区需要使用哪个分区方案下的分区字段,那么这里就是RangeSchema_CreateTime
中的CreateTime字段。
create table Shop
(
ID varchar(50),
ShopName varchar(50),
CreateTime datetime
) on RangeSchema_CreateTime(CreateTime)
这里要注意,如果在创建表的时候指定了ID为主键的话,这个时候需要指定ID为分区字段,否则会报错的。
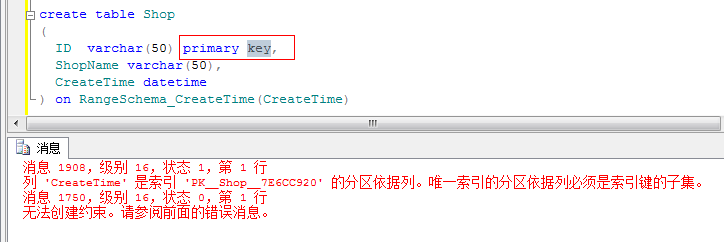
这时候可以在不要主键的情况下先创建表,然后再指定ID为主键。

7:插入测试数据并统计
这里我先插入10w条数据,然后来看看数据在各个分区的情况。‘
<1>插入数据
<2> 统计每个分区的数据量
这里主要有一个查询分区的关键字“$partition”,非常的有用。
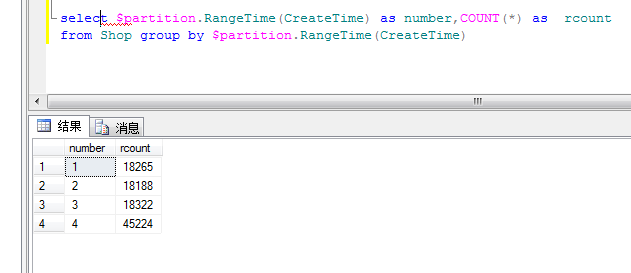
好了,到这个我们通过sql语句来实现分区表就已经完成了。
二:使用管理界面创建分区表
1:首先我们创建test1数据库和shop表
2:创建文件组和文件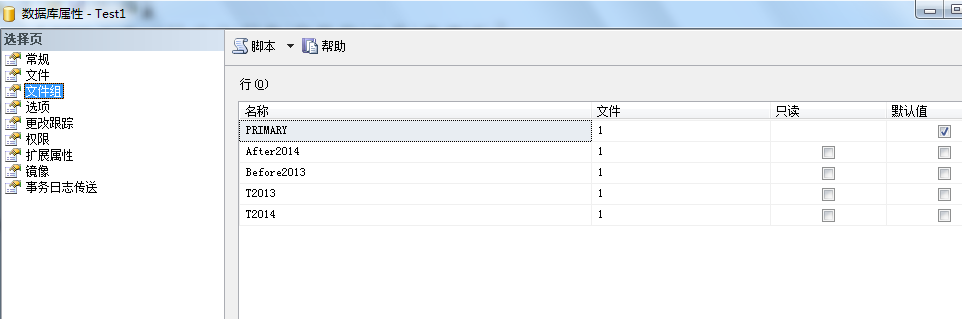
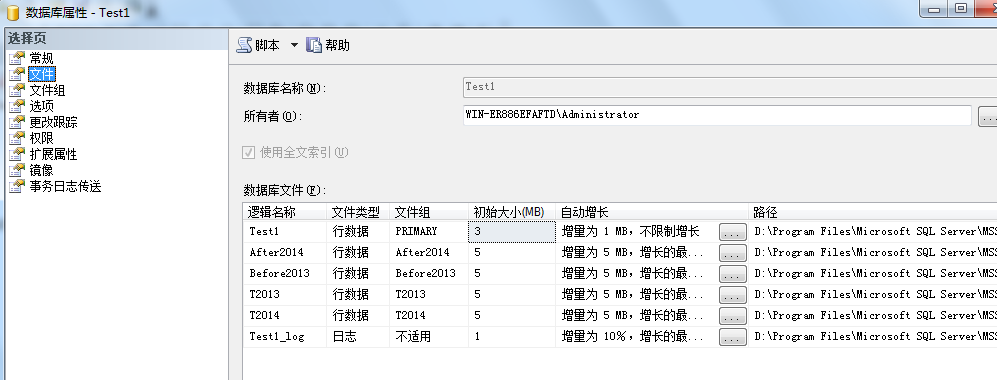
3:创建分区
①:右键Shop表,弹出菜单中选择 “存储” => "创建分区"
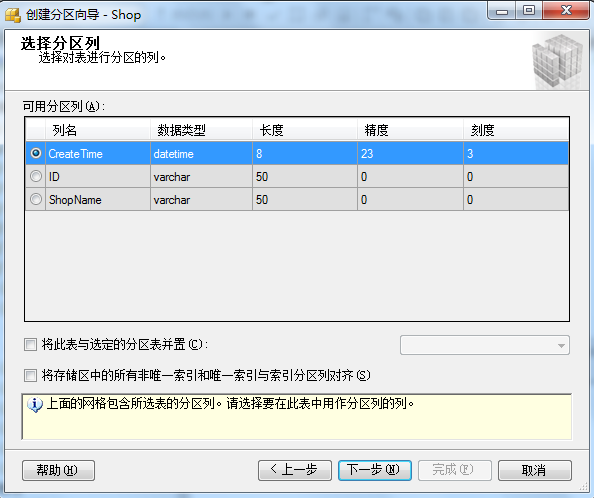
②:创建“分区函数”名 和 “分区方案”名。
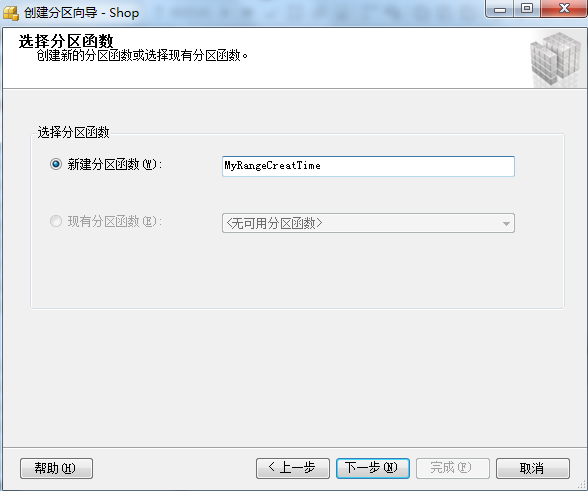

③:创建分区映射,也就是将”分区函数“和“文件组”进行关联。
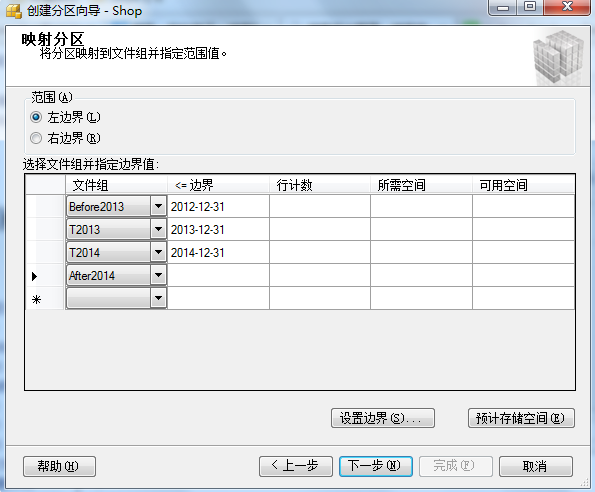
④: 最后我们可以看一下界面给我生成的分区函数以及分区方案,蛮有意思的。
USE [Test1]
GO
BEGIN TRANSACTION
CREATE PARTITION FUNCTION [MyRangeCreatTime](datetime) AS RANGE LEFT FOR VALUES (N'2012-12-31T00:00:00', N'2013-12-31T00:00:00', N'2014-12-31T00:00:00') CREATE PARTITION SCHEME [MySchemeCreateTime] AS PARTITION [MyRangeCreatTime] TO ([Before2013], [T2013], [T2014], [After2014]) ALTER TABLE [dbo].[Shop] DROP CONSTRAINT [PK__Shop__3214EC277F60ED59] ALTER TABLE [dbo].[Shop] ADD PRIMARY KEY NONCLUSTERED
(
[ID] ASC
)WITH (PAD_INDEX = OFF, STATISTICS_NORECOMPUTE = OFF, SORT_IN_TEMPDB = OFF, IGNORE_DUP_KEY = OFF, ONLINE = OFF, ALLOW_ROW_LOCKS = ON, ALLOW_PAGE_LOCKS = ON) ON [PRIMARY] CREATE CLUSTERED INDEX [ClusteredIndex_on_MySchemeCreateTime_635288828144372217] ON [dbo].[Shop]
(
[CreateTime]
)WITH (SORT_IN_TEMPDB = OFF, IGNORE_DUP_KEY = OFF, DROP_EXISTING = OFF, ONLINE = OFF) ON [MySchemeCreateTime]([CreateTime]) DROP INDEX [ClusteredIndex_on_MySchemeCreateTime_635288828144372217] ON [dbo].[Shop] WITH ( ONLINE = OFF ) COMMIT TRANSACTION
从图中可以看到生成好的分区函数名”[MyRangeCreatTime]“ 和分区架构名“[MySchemeCreateTime]”,最后我们执行下该sql就ok了。
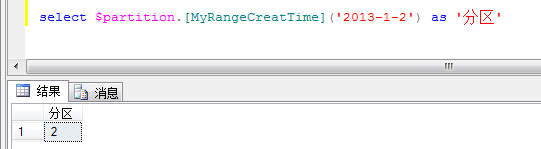
⑤ 插入测试数据并进行简单的测试
这里测试下“2013-1-1”是在哪个分区下。
sql server 小记——分区表(上)的更多相关文章
- sql server 小记——分区表
我们知道很多事情都存在一个分治的思想,同样的道理我们也可以用到数据表上,当一个表很大很大的时候,我们就会想到将表拆 分成很多小表,查询的时候就到各个小表去查,最后进行汇总返回给调用方来加速我们的查询速 ...
- SQL Server 2005 分区表实践——分区切换
本文演示了 SQL Server 2005 分区表分区切换的三种形式: 1. 切换分区表的一个分区到普通数据表中:Partition to Table: 2. 切换普通表数据到分区表的一个分区中:Ta ...
- SQL Server连接不上本地服务器
昨天星期一,到公司,如常打开电脑后,上个厕所,吃个早餐,电脑才完全醒来.打开项目后台,发现登不上,用户名或密码错误,认真输入几遍,还是错误,打开本地数据库,sql server连接不上,提示错误: 我 ...
- 干货 | RDS For SQL Server单库上云
数据库作为核心数据的重要存储,很多时候都会面临数据迁移的需求,例如:业务从本地迁移上云.数据中心故障需要切换至灾备中心.混合云或多云部署下的数据同步.流量突增导致数据库性能瓶颈需要拆分-- 本文将会一 ...
- 关于SQL Server中分区表的文件与文件组的删除(转)
在SQL Server中对表进行分区管理时,必定涉及到文件与文件组,关于文件与文件组如何创建在网上资料很多,我博客里也有两篇相关转载文件,可以看看,我这就不再细述,这里主要讲几个一般网上很少讲到的东西 ...
- SQL Server 在Alwayson上使用内存表"踩坑"
200 ? "200px" : this.width)!important;} --> 介绍 因为线上alwayson环境的一个数据库上使用内存表.经过大概一个星期监控程序发 ...
- SQL server无法连接上服务器的相关问题
安装MySql以后,SQL server突然就连接不上服务器了,问了老师,说是啥进程关闭了,都打开了也没搞好,都准备重装了,结果看到度妈上面的一篇文献,原来是SQL server MSSQLSERV ...
- SQL Server现有表上自增属性增删原理研究
项目需求:线上有一张表,数据类型为int类型,现在由于项目变更,需要这一列添加自增属性,而且,为了保证能尽快完成,希望使用脚本来实现,而不是在表设计中通过GUI窗口来实现. 问题来了:SQL Serv ...
- SQL Server 查看分区表(partition table)的分区范围(partition range)
https://www.cnblogs.com/chuncn/archive/2009/02/20/1395165.html SQL Server 2005 的分区表(partition table) ...
随机推荐
- $("").click与onclick的区别示例介绍
Html代码: <script type="text/javascript"> $(function(){ $("#btn4").click(fun ...
- border-style 属性
border-style 属性用于设置元素所有边框的样式,或者单独地为各边设置边框样式. 只有当这个值不是 none 时边框才可能出现. 例子 1 border-style:dotted solid ...
- [译]WebVR技术方案草案
注:基于官方的.bs规范专用格式进行了翻译,但结果发现无法编译成html格式,所幸基本兼容.markdown格式. 中文翻译项目地址:https://github.com/web3d/webvr-sp ...
- MYSQL 解锁与锁表
解锁 第一种 show processlist; 找到锁进程,kill id ; 第二种 mysql>UNLOCK TABLES; 锁表 锁定数据表,避免在备份过程中,表被更新 mysql> ...
- lodash常用方法1--查询
1.find var _ = require('lodash'); var user1 = { name: 'zhangsan', height: 180, weight: 120 }; var us ...
- 把GAE程序通过SSH部署到 VPS
大部分在文档上都写了, 写这篇文章的目的是发现现在appcfg.py update xxxx的时候会打开浏览器访问google请求授权(后台内建了一个本地server, 端口是8090, 授权成功后会 ...
- C# AOP框架入门
AOP面向切面编程(Aspect Oriented Programming),是通过预编译方式和运行期动态代理实现程序功能的统一维护的一种技术.Spring框架用的核心技术就是AOP,是函数式编程的一 ...
- Electron - 创建跨平台的桌面客户的应用程序
Electron 框架的前身是 Atom Shell,可以让你写使用 JavaScript,HTML 和 CSS 构建跨平台的桌面应用程序.它是基于io.js 和 Chromium 开源项目,并用于在 ...
- HoverTree菜单0.1.3新增效果
HoverTree菜单0.1.3增加弹出菜单的动态效果,可以是动态下拉,也可以是动态淡入. 效果请看:http://keleyi.com/jq/hovertree/demo/demo.0.1.3.ht ...
- CSS基础教程 -- 媒体查询屏幕适配
响应式布局 Media Query 的使用方法 在上例中, 我们使用Media Queries来根据3种不同尺寸的窗口使用3种不同的样式.通过不同的媒体类型和条件定义样式表规则,媒体查询让CSS可以更 ...